محتویات
- تعریف هوش
- تعریف هوشتجاری
- اهداف هوشتجاری
- سطوح هوشتجاری
- مراحل پیادهسازی هوشتجاری
- تعریف ETL
- نعریف Data Warehouse
- تعریف Data Mart
- انواع دیتابیس
- روش بدستآوردن و تبدیل دادهها در روش سنتی
تعریف هوش
وقتی میخواهیم به سازمانی صفت هوشمندی بدیم که این سازمان علاوه بر صفتها و قابلیتهای دیگهای که داشت الان هوشمند هم شده در تعریف لغتی هوش در لغتنامه دهخدا اینجوری اومده: زیرکی، آگاهی و شعور و فهم و فراست
هرکدوم از این تعاریف یا مجموعه از این تعاریف میتونه باعث بشه که ما به یک سازمان یا یک شخص بگیم این شخص یک شخص باهوشیه
تعریف هوشتجاری
وقتی میخواهیم یک سازمانی رو درگیر مبحثی به نام هوشتجاری کنیم دقیقاً چه هدفی داریم و تعریفمون از هوشتجاری چیه؟
به فرآیند تبدیل داده به اطلاعات در جهت انجام تصمیمگیری هوشتجاری میگن
حالا این هوش تجاری یک هدف دیگهای هم علاوه براینکه بیاد یسری اطلاعات رو تولید بکنه داره اونم اینه که ما در نهایت بیایم از طریق اون اطلاعات اقدام به تصمیمگیری بکنیم یه هدف دیگهای هم داره اینکه بیاد این تصمیمگیری رو تسهیل و در نهایت موجب افزایش کارایی اون سازمان بشه
(خب در حالت عادی هم یک سازمان تصمیمگیری میکنه و یکسری اطلاعات رو هم داره و بدون مشکل کارش رو انجام میده ولی وقتی ما یک سیستم هوشتجاری راهاندازی میکنیم و یک سازمان رو دچار فرآیند هوشتجاری میکنیم بیشتر هدفمون اینه که بیایم تسهیل و افزایش کارایی رو توی سازمان داشته باشیم)
اهداف هوشتجاری
طبیعتاً ما از پیادهسازی هر سیستمی توی یک سازمان دنبال یکسری هدف و اهداف هستیم و دوست داریم به یکسری نتایج برسیم.
هدف از پیادهسازی سیستمهای هوشتجاری توی یک سازمان:
- تسهیل در تصمیمگیری (مثال: فرضاً اگر من مدیر یک سازمان باشم اگر لازم شد تصمیمگیری انجام بدم اطلاعات رو راحت بدست بیارم یعنی تو زمانی که تصمیم گرفتیم تا برای سازمان تصمیمگیری کنیم تازه شروع نکنیم که دادهها رو تبدیل به اطلاعات کنیم و بعد اونها رو تحلیل کنیم و درنهایت تصمیمگیری کنیم. بهتره ما یک بستر یا سیستم یا سامانهای داشته باشیم که اینها دیتاها رو به صورت مداوم و مرتب آنالیز بکنه و نتایج رو بدست بیاره و هر وقت ما نیاز به این دادهها داشتیم که بخواهیم تصمیمی رو از روی اونها بگیریم خیلی راحت با چند کلیک یا خوندن یک گزارش خیلی ساده بتونیم اون تصمیم رو بگیریم بدون این که دچار هیچ روال اضافهای توی سیستم اداری نشم که بخوایم دیتا رو بگیریم و تبدیل به اطلاعات بکنیم و تحلیل کنیم پس میخواهیم همه اینها رو بذاریم کنار)
- افزایش کارایی سازمان (مثال: اینکه بتونیم با نگاه کردن به وضعیت جاری سازمانمون مشکلات رو تشخیص بدیم و درنهایت مشکلات و نواقص رو برطرف کنیم ما وقتی یک سیستم آمادهای داشته باشیم که این سیستم دائم در حال بروز شدنه و دادههای سازمان ما رو میگیره و وضعیت سازمان رو تو خودش نگهداری میکنه و یه تحلیلی رو روش انجام میده و من هر وقت به این سامانه نگاه کنم میتونم متوجه بشم که مشکل کجاست، ایراد کجاست کدوم بخش سازمان ما مثلاً نیاز به تزریق نیرو داره، نیاز به تزریق سرمایه داره و به هر نحوی که لازم باشه اون مشکل رو برطرف میکنم)
- تشخیص زود هنگام خطرات قبل از اینکه سازمان دچار مشکل شود (مثال: فرض کنید فصل تابستون شده و مثلاً ۱۰ سال قبل از این تاریخ ما پشتبوم خونه رو ایزوگام کردیم حالا با توجه به اینکه یه مدت زمان طولانی از تعمیرات قبلی گذشته ما ۲ راه داریم: ۱) الان که فصل تابستونه و بارندگی وجود نداره و هوا نسبتاً خوبه و مشکلی وجود نداره وضعیت ایزوگام رو بررسی کنیم و ببنیم جاییاش مشکل یا نشتی داره آب به ساختمون نفوذ کرده یا نه و اگه مشکل داشت اقدام به رفعش کنیم ۲) یه راه دیگه اینه که بگیم این ۱۰ سال که مشکلی به وجود نیومده پس احتمالاً امسال هم بدون مشکل رفع میشه حالا هر وقت که مشکلی پیش اومد و آب به خونه نفوذ کرد و باعث مشکل سقف شد اقدام به برطرف کردنش میکنیم. خب قطعاً روش اول خیلی بهتره ولی روش دوم هم مشکلی نداره ولی چون در روش دوم پیشبینی برای وضعیت خرابی نکردیم پس ممکنه با مشکلات زیادی مواجه بشیم (مثلاً سقف خونه خراب بشه و تعمیرش بیشتر از تعمیر ایزوگام در وقت خودش باشه) پس اگه من یک سیستمی داشته باشم تا بتونم وضعیت سازمان رو دائم رصد کنم میتونم مشکلات رو قبل از به وجود اومدنشون پیشبینی کنم و قبل از اینکه هزینههای سازمان ما خیلی زیاد بشه اون موقع که دارم رشد هزینههای بیرویه رو میبینم متوجه میشم و میام جلوش رو میگیرم ولی وقتی همچین سیستمی رو نداشته باشم هر وقت که این هزینهها فرضاً به aریال رسید و اون a خط قرمز ما بود تازه دنبال مشکل میگردیم و اینکه چجوری میتونیم رفعش کنیم ولی دیگه اون aریال هزینه انجام شده و قابل بازگشت نیست)
- شناسایی فرصتهای کسب و کار قبل از رقبا (مثال: یکی از کاربردهای BI تحلیل بازار و نیازسنجی اون بازار یا جامعه است. اگر سازمان ما یک تحلیل خوب و قوی از نیازهای بازار داشته باشه خیلی سریعتر از دیگر رقبا میتونه اقدامی رو انجام بده (محصولی ارائه بده، خدمتی ارایه بده) که این در نتیجه میتونه باعث بشه سازمان یک سودآوری بالایی داشته باشه و یه سهم زیادی از بازار بالقوه در خدمت سازمان خودمون قرار بگیره)
- بالا بردن سطح رضایتمندی مشتریان (مثال: فرضاً اگر ما یکسری خدمات و محصولات رو برای یه قشر خاصی از بازار هدفمون ایجاد کرده باشیم و دیتای وضعیت رضایتمندی مشتریانمون رو داشته باشیم میتونیم خیلی سریع متوجه بشیم که کجای نرمافزار، کجای خدمتی که داریم ارائه میدیم خوب نیست، مشکل داره و احتیاج به تقویت داره پس قبل از اینکه مشتری ما از ما ناراضی بشه و بیاد با ما قطع همکاری بکنه من مشکل رو برطرف میکنم و مشتری فعلیمون رو حفظ خواهیم کرد)
سطوح هوشتجاری
سطوح هوشتجاری در سازمانها مشابه سطوح مدیریتی در سازمانها است یعنی برای هر سطح مدیریتی در سازمان ما باید یک سیستم هوشتجاری مناسب با اون سطح رو طراحی کنیم اما منظور این نیست که ما بیایم برای هر بخش یا هر سطحی بیایم یک سیستم راهاندازی بکنیم بیتشر منظور اینه که اگه ما یه سیستم هوشتجاری توی یک سازمان میخواهیم راهاندازی کنیم بیایم اون رو با استفاده از دسترسیهایی که میدیم(بحث دسترسیهای امنیتی) بیایم سطحبندی کنیم افراد رو شناسایی بکنیم سطوحی که قراره توی سازمان از این سیستم استفاده کننده رو شناسایی بکنیم و با توجهع به سطح دسترسی اونها بیایمبه اطلاعاتی که توی این سسیستم وجود داره دسترسی بدیم. این سطوح همانند سطوح مدیریتیه.
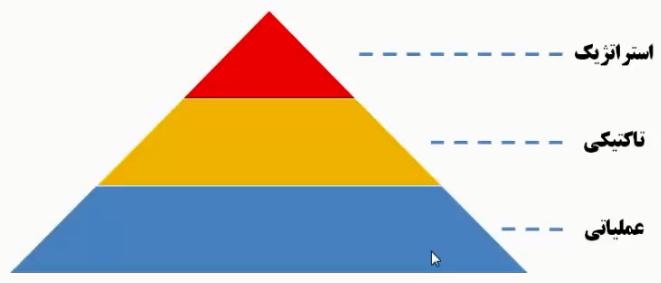 سطح اول
سطح اول

- استراتژیک: توی این سطح ما خیلی نباید کاربر یا مدیر سازمان رو درگیر جزئیات کنیم مدیر فرضاً فقط باید یکسری نمودار راحت و قابلفهم داشته باشه که بتونه با اونها کار بکنه و با صرف کمترین زمان و با یک نگاه بتونه متوجه بشه که وضعیت سازمان به چه صورته و اشکال کار از کجاست توی این سطح در سازمان ما تصمیمگیری انجام میدیم یعنی شاید خیلی درگیر این نشن که بخوان متوجه بشن که توی یک سازمان ۱۰۰ نفره کدوم کاربر داره اشتباه کار میکنه، بلکه میان میبینن که کدوم واحد درگیر شده و متوجه میشن که مثلاً توی واحد x داره کمکاری صورت میگیره و روال کاری اشتباهه پس میان به مدیر اون واحد اطلاع میدن و وظیفه اون مدیر میشه که اون شخص رو پیدا بکنه
سطح دوم
- تاکتیکی: مدیران واحد یا مدیران اجرایی سازمان که میان در جزئیات کار دخیل میشن که فرآیند در واحدشون به چه شکلی داره انجام میشه افراد توی این سطح بیشتر مدیران فنی هستند یعنی درگیر کار فنی هستند و نسبت به مدیران استراتژیک احتیاج به جزئیات بیشتر و کلیات کمتری دارند.
سطح سوم
- عملیاتی: یعنی کارشناسان واحد، اونهایی که باید کارها رو انجام بدن و taskهایی براشون تعریف شده این افراد اصلاً نیاز نیست کلیات سازمان رو ببینند توی سیستمهای هوشتجاری وقتی میخواهیم داشبردی رو طراحی بکنیم یکسری آبجکت داریم از نمودارها gauge بیشتر برای بالای سطوح بالاتر سازمان استفاده میکنیم و از جداول که توش detaile رو نشون میدن تو سطح عملیاتی استفاده میکنیم.
مراحل پیادهسازی هوشتجاری
این بحص راجع به این موضوع هست که یک سیستم هوشتجاری چه مراحلی رو باید توی یک سازمان طی کنه و ما برای پیادهسازیاش چه مراحلی رو باید طی کنیم و چه کارهایی رو باید انجام بدیم.
ما برای پیادهسازی هوشتجاری ۲ تا روش داریم: ۱) سنتی ۲)مدرن
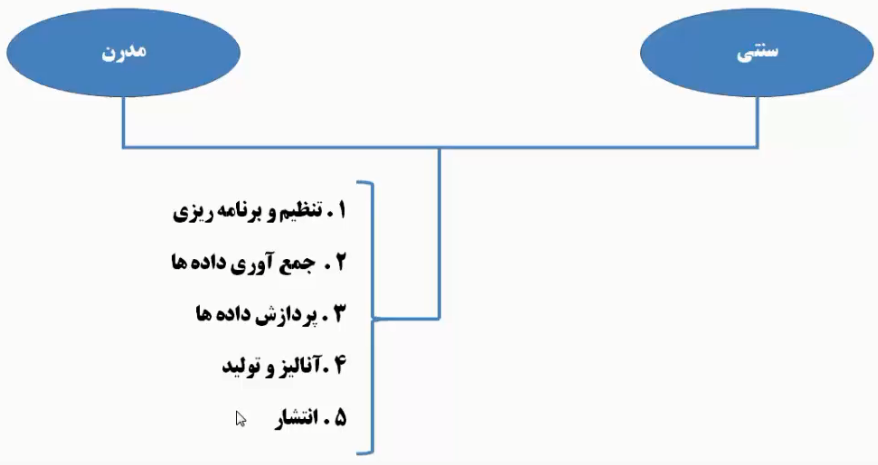
چیزی که توی این بخش مهمه که بدونید اینه که هردوی این روشها یعنی روش سنتی و روش مدرن ۵ مرحله مشترک دارند(۵ مرحله وجود داره که ما بتونیم یک سیستم هوشتجاری رو چه از طریق روش سنتی و چه از طریق روش مدرن پیادهسازی کنیم):
- تنظیم و برنامهریزی: یعنی بیایم ببینیم که اصلاً به چه چیزی توی سازمان نیاز داریم و بعد از اینکه سیستم در سازمان پیادهسازی شد چه ارزش افزودهای برای سازمان ایجاد میکنه در حقیقت باید یک پلن کلی برای کارمون داشته باشیم
- جمعآوری دادهها: فرضاٍ میدونیم که یک سیستم هوشتجاری میخوایم یا یک سیستم هوشتجاری احتیاج داریم که بخشی از اون مثلاً قراره سیستم منابع انسانی ما رو شامل بشه حالا توی این سیستم منابع انسانی ما احتیاج به یکسری داده داریم خب این دادهها ممکنه توی دیتابیسهای مختلفی وجود داشته باشه و همشون توی یک دیتابیس خاص جمع نشده باشن و پخش شده باشن(فرضاً بخشی از دیتای ما توی دیتابیس مربوط به سیستم حظور و غیاب ما باشه و بخشی توی سیستم قراردادهای ما باشه و ...) پس اگر این سیستمهای ما یکپارچه نباشن ممکنه دیتابیسهاشون هم یکپارچه نباشن پس باید توجه کنیم که این دادهها رو از کجا جمع بکنیم.
- پردازش دادهها: یعنی اگر قرار باشه این دادهها رو از دیتابیسها و پایگاهدادههای مختلف جمع کنیم و همون رو بدون هیچ پردازشی به کاربر نهایی نشون بدیم خب سیستم هوشتجاری طراحی نکردم ما باید بیایم یک پردازشی روی دادهها انجام بدیم شاید لازم بشه دادهها رو تغییر بدیم یا یه بخشی از دادهها رو بیاریم و نیاز نباشه همه دادهها رو بیاریم.
- آنالیز و تولید: ما میایم براسای نیاز سازمانمون دادهها رو تحلیل میکنیم مثلاً رتبهبندی وضعیت کارمندان، دستهبندی دادهها (مثلاً توی دادههایی که مربوط به یک کارمنده اگر بتونیم توی یک دستهبندی خاص قرارش بدیم باعث رتبهبندی کارمندانمون شدیم) یعنی قبل از پیادهسازی به صورت تئوری و روی کاغذ بدونیم که چه چیزی از دادهها میخواهیم بدست بیاوریم و دادهها هر حالتی داشته باشه نتیجه خروجیاش چه چیزی خواهد شد.
- انتشار: وقتی توی مرحله قبل آنالیزمون رو انجام دادیم و سیستم رو در نهایت شروع به تولید کردهایم و حالا که سیستم تولید شد میایم و سیستم رو در اختیار کاربران قرار میدیم. البته یه بحثی که قطعاً وجود داره اینه که وقتی ما یک سیستمی رو تولید میکنیم و سیستم در اختیار کاربر قرار میگیره و کاربر باهاش کار میکنه ما شروع به دریافت بازخورد یا فیدبک میکنیم، ما باید این فیدبکها رو جمع کنیم و تغییرات رو در سیستم اعمال کنیم.
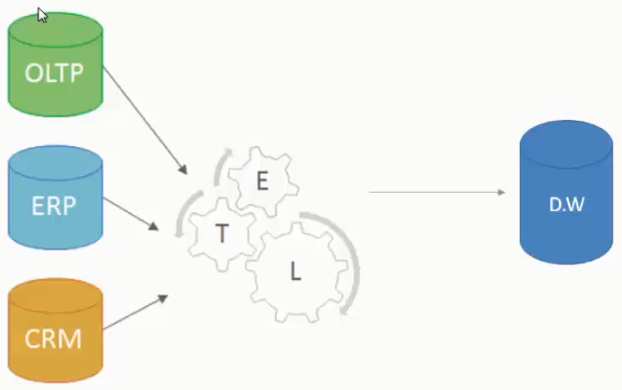
تعریف ETL
سیستمهای هوشتجاری غالباً بکگراندشون یه سیستم DataWarehouseه
من وقتی میخوام یک DW رو تشکیل بدم باید دادهها رو از دیتابیسهای گوناگون چه از نظر نوعی اوراکل، sql server و ...باید جمعآوری بکنم و اینکه ممکنه از سیستمهای مختلفی هم این دادهها رو جمعآوری بکنم (مثلاً ممکنه دادههای سیستم منابع انسانی یه بخشیش توی دیتابیس سیستم حظور و غیاب ما باشه و یه بخشیش توی سیستم قراردادهای پرسنلی باشه، یه بخشیش توی سیستم CRM امون باشه که بخشی از اون مربوط به پرسنل خودمونه و دادهها اونجا باشه و ...) وقتی ما میخوایم DW تشکیل بدیم یا وقتی میخوایم یک سیستم هوشتجاری طراحی کنیم پیشزمینهاش باید یک DW تشکیل بدیم که پیشزمینهی تشکیل DW انجام فعالیتهای ETLه
پس وقتی قرار باشه دادههای ما تبدیل به اطلاعات بشن یسری فعالیت باید روشون انجام بدیم که به مجموعه این فعالیتها میتونیم بگیم ETL = تعریف ساده
منظور از ETL

- E یعنی Extract: یعنی بیایم دیتا رو از دیتابیسهای مختلف یا از یک دیتابیس بیرون بکشیم
- T یعنی Tranfer: یعنی بیایم این داده رو انتقال بدیم، فرضاً ما یکسری اطلاعات از دیتابیسمون بیرون کشیدیم و استخراج کردیم و میایم اینها رو انتقال میدیم. اتقال یعنی یک بستری رو فراهم کنیم (میتونیم تو طول انتقال یکسری پردازش هم روی دیتاها انجام بدیم مثلا بیایم بگیم یه ضریبی رو برای حقوق پرسنلمون در نظر بگیر | ما یک سیستم قراردادها داریم که توی اون حقوق هر پرسنلمون نوشته شده ولی ما توی داشبوردمون احتیاج به ضریب این عدد داریم یا یه ضریب رشدش رو احتیاج داریم و نیاز نیست مبلغ حقوقش رو ببینیم | در این حالت میتونیم بیایم یک DW تشکیل بدیم که یکی از جداول یا یکی از فیلدهای یکی از جدولهاش روش حقوق رو به صورت ضریب نگهداری بکنه |حالا ما توی این خط انتقال یا Transferای که داریم یعنی وثتی دیتا رو Extract کردیم و میخوایم ببریم یه جایی ذخیرهاش کنیم یک خط انتقالی تشکیل میدیم که این خط انتقال Transfer ماست که میتونه خیلی ساده دیتا خونده بشه و در اونطرف بارگذاری بشه و میتونه یکسری پردازش هم روش صورت بگیره(ضرب و تقسیم بشه منها بشه با فیلدهای دیگهای جمع بشه) و یه تغییری روش انجام بشه و در نهایت ببریم به مرحله بعدی رو بارگذاری رو انجام بدیم.
- L یعنی Load: ما توی Load بارگذاری میکنیم دیتایی رو که از E خوندیم رو و از طریق T انتقال و پردازش کردیم. اون محلی که برای نگهداری دادههای پردازش یافته و انتقال یافته ما از دیتابیس اصلی در نظر میگیریم اون مرحله Load هستش.
نکته: امکان داره توی یکسری از متون و کتابها ببینید که ما یک مرحله دیگهای هم برای ETL داریم که با اون مرحله میشه ETLa
- A یعنی Aggregation: یعنی داده رو تو مرحله اول استخراج کنیم توی مرحله دوم انقالش بدیم توی مرحله سوم بارگذاری کنیم و درنهایت یکجا جمعآوریاش کنیم و همه رو کنار هم نگهداری کنیم Aggregation مثلاً بیایم بگیم دادههای مربوط به مالی همشون توی یک جدول باشن
نکته: طبیعتاً ما a رو توی همهی ETLهامون داریم و هیچ ETL ای نمیتونه بدون Aggregation باشه و این مرحله ۴ بیشتر میتونه توی همون مرحله ۳ باشه برای همین توی خیلی از کتابها بهش اشاره نمیشه
تعریف DataWarehouse
ما برای اینکه بتونیم یک سیستم هوشتجاری رو تشکیل و طراحی بکنیم احتیاج به این داریم که پشت سیستم هوشتجاریمون یک DataWarehouse باشه. پس غالباً سیستمهای هوشتجاری روی D.Wای شکل میگیرند. D.W از طریق انجام فعالیتهای ETL مختلف روی دیتابیسهای مختلفمون تشکیل میشه.
D.W یا همون انبارهداده به مجموعهای از دادهها گفته میشه که از منابع مختلف اطلاعاتی سازمان جمعآوری شده، دستهبندی و ذخیره میشوند و برای تشکیل D.W هم ما نیاز به فعالیت ETL داریم. همانطور که در شکل زیر نیز بهش اشاره شده ما ممکنه چندین نوع دیتابیس مختلف داشته باشیم (دیتابیس CRM داشته باشیم/ دیتابیس ERP یا هر نوع دیتابیس OLTP) پس D.W تشکیل شده از دیتاهای دیتابیسهای دیگه است پس وقتی روی یک دیتابیس یا چند دیتابیس فرآیند ETL انجام میدیم و یک خروجی به صورت table میگیرم میایم به یه شکلی این دادهها رو توی tableها میچینیم و در نهایت توی یک مخزنی ذخیره میکنم اون مخزن اسمش D.W است.
ویژگیهای D.W
D.W قاعدتاً یکسری ویژگیها داره، ما به هر دیتابیسی با این ویژگیهای خاص میتونیم بگیم D.W
- موضوعگرا: یعنی تمام دادههایی که توی یک موضوع باهم مشترک هستند یکجا بذاریم مثلاً بیایم یک D.W تشکیل بدیم برای بخش فروشمون و بیایم دادههای مربوط به فروش رو توی اون دیتابیس نگهداری کنیم پس باید بیایم بررسی کنیم که دادههای کدوم بخشهای سازمان مربوط به فروش ما میشود تا ما بیایم برای واحد فروش یک D.W تشکیل بدهیم حالا فروش میتونه تشکیل شده باشه از بخش وصول مطالبات، بخش تبلیغات، بخش بازاریابی و هر بخشی که به نحوی کار و فعالیتش منجر به این میشه که واحد فروش ما درگیر بشه
- یکپارچگی: یک D.W باید یکپارچه باشه یعنی یک مدل واحد برای ذخیرهسازی داده باید براش درنظر بگیریم پس دادههامون نباید به شکلهای مختلف توش ذخیرهسازی شوند اون واحد بودن اون مدل یعنی یک مدل استاندارد دربیاریم و بگیم D.W ما دادهها توش باید به یک صورت خاص ذخیره بشه با این ترتیب قرار بگیرند و فرضاً جداول ما حتماً دارای این فیلدها باشند پس باید یک مدل واحد براش دربیاریم.
- از بین نرفتنی: یعنی نتونیم بیایم transaction روی D.W امون تشکیل بدیم. D.W اصولاً دیتابیسیه که ما روش transaction نداریم و فقط روش کوئری میزنیم. پس کاربر ما حتی تو هر سطح سازمانی که میخواد باشه اجازه تغییر دادن دادههای D.W رو نداره. نمیتونه بیاد فرضاً یک رکورد خاص رو تاریخش رو آپدیت بکنه یا یک رکوردی رو پاک بکنه یا خودش دستی بیاد یک رکوردی رو اضافه بکنه. این کارها باید از طریق همون سیستم ETLای که داشته دادهها از دیتابیسهای دیگه خونده بشه و از طریق بخش T اگر پردازشی هست روش انجام بشه و درنهایت بیاد رو D.Wامون قرار بگیره. پس آپدیت توی D.W نداریم insert داریم ولی فقط از طریق ETLای که انجام میدیم Delete نداریم چون قراره سوابق یک سازمان رو توی D.Wامون نگهداری بکنیم D.W یک سازمان دادههاش شسته رفته است و داده نویز توش نداریم و قبل از اینکه داده بیاد تو D.W قرار بگیره اون تمیزکاریها و اون کارهایی که باید انجام بدیم و پالایش کنیم رو انجام میدیم و بعد توی D.W داده قرار میگیره پس داده اضافهای تو D.W نداریم و به هیچ وجه احتیاجی به Delete, Update نخواهیم داشت.
- متغیر با زمان: توی دیتابیس دادههای مربوط به ۱ ماه اخیر رو توش نگهداری میکنیم خب ما نمیتونیم همچین تعریفی برای دیتابیس داشته باشیم چون نمیشه گفت دادههای مربوط به ۱ ماه توی دیتابیس قرار میگیرند و دادههای بیش از ۱ ماه (۲ماه، ۳ماه، ۱سال، ۱۰سال و ...) میان تو D.W قرار میگیرند پس شما باید بیاین این تعریف رو برای سازمان خودتون ببینید چجوری میتونید پیادهسازی بکنید. سازمان شما به دادههای موجود تو دیتابیسش تا چه زمانی نیاز داره آیا کفایت میکنه که فقط اطلاعات مربوط به ۱ماه اخیر ما توی دیتابیس باشه یا نه سازمان ما مثلاً به نامههای ۲سال پیشش هم نیاز فوری داره پس نمییایم همچیم تعریفی برای دیتابیس و D.W داشته باشیم درست این تعریف اینه که: دادههایی که مربوط به D.Wاند مربوط به تاریخچه سازماناند مثلاً خیلی کم پیش میاد که توی یک سازمان بخوایم به نامههای ۱۰ سال پیش دسترسی داشته باشیم پس میتونیم این نامهها رو بایگانی کنیم و اطلاعات مربوط به نامهها رو توی D.Wامون ذخیره کنیم و بدونیم که فرضاً سازمان ما با سازمان x ۱۰ سال پیش یکسری مکاتبه داشته ولی حالا جزئیات این مکاتبات نیاز نیست تو دیتابیس ما قرار بگیره حالا اگه قراره باشن باید نیازهای سازمان بسته به نوع فعالیتش بررسی بشه و این قضیه مستند بشه که اطلاعات مربوط به دیتابیسش ماله چه بازهی زمانی باشند و ماقبل اون داخل D.W قرار بگیرند.
تعریف Data Mart
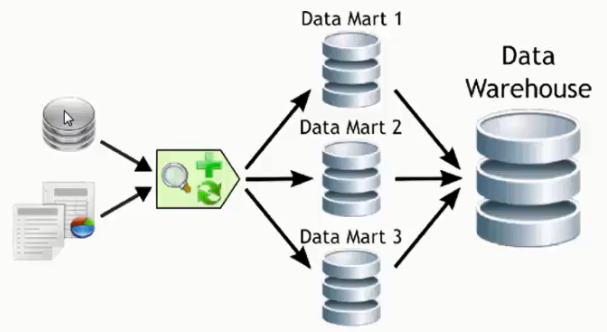
D.W به مجموعهای از دادهها گفته میشه که از منابع مختلف اطلاعاتی سازمان جمعآوری، دستهبندی و ذخیره میشه فرضاً اومدیم گفتیم که باید تو ویژگیهاش موضوعگرا بودن باشه یعنی تمام دادههایی که مثلاً تو واحد فروشمون هستند باید توی D.Wامون قرار گرفته بشه
وقتی که ما میایم Scale D.W امون رو کوچیکتر میکنیم یعنی بیایم اطلاعات هر بخش رو تخصصیتر بکنیم فرضاً بیایم بگیم واحد فروش من یک D.W داره حالا اطلاعات مالیاش میخوام جدا باشه و اصلاً نمیخوایم بدونیم تو بازاریابی چه خبره پس فقط میایم دادههای مربوط به فروشمون رو درمیاریم
به D.Wای که Scale کوچیکتری داشته باشه و فقط به یک فعالیت خاص اشاره داشته باشه مثلاً بحث مالی، مثلاً بحث جذب پرسنل (ببینید واحد پرسنلی خیلی فعالیتها میکنه مثلاً میاد فعالیتهای جذب نیرو میکنه، بازنشستگی رو انجام میده، فرضاً احراج رو انجام میده و ...) ولی ما میخوایم یک D.Wای داشته باشیم فقط برای جذب نیرو به این D.W دیگه میگیم D.M
طریقه تشکیل D.M مشابه D.W ه و هیچ تفاوتی نداره داده از طریق فعالیت ETL منتقل میشه و توی یک مخزنی نگهداری میشه و چون این دادهها همه از یک نوع جنس و یک فعالیت خیلی خاص هستند بهش میگیم D.M
حالا این D.Mها وقتی کنار هم قرار بگیرند تشکیل D.W رو برای سازمان ما میدن
انواع پایگاهداده
یه بحثی که داشتیم انواع دیتابیسهایی که روشون ETL انجام میشن و دادههایی که از دیتابیسهای مختلف چه از نظر نوعی چه از نظر سامانهای خونده میشن میاد توی D.W ذخیره میشه. انواع دیتابیس:
- Online analytical processing: OLAP
- Online transaction processing: OLTP
ما از دیتابیسهای OLAP میایم برای طراحی سیستمهای هوشتجاری (D.W) امون استفاده میکنیم و از سیستمهای OLTP زمانی استفاده میکنیم که میخوایم یک سیستمی داشته باشیم که فرضاً توش تراکنش زیاد انجام میشه (تراکنش شامل: Delete, Update, Insert)
پس آیا نمیتوان توی دیتابیس نوع OLAP بیایم Update, Insert, Delete داشته باشیم؟
در حقیقت تونستنش میتونیم ولی یکی از ویژگیهای D.W اینه که دادههاش از بین نرفتنیاند یعنی update انجام نمیدیم (insert داریم و حتی update رو هم بنابه نیازمون ممکنه داشته باشیم ولی update, insert از طریق فرآیند ETL انجام میشوند و کاربر نمیاد به صورت دستی اینکار رو انجام بده)
خاصیتی که دیتابیسهای OLAP دارند اینه که ارتباط بین جداول یا خیلی ضعیفاند یا وجود ندارند، یعنی ممکنه ما تو D.Wامون و سیستم OLAP اصلاً کلید خارجی نداشته باشیم برای همین کوئری گرفتن توش خیلی راحته یعنی نیاز نیست که وقتی ما یه کوئری میزنیم فرضاً join داشته باشیم پس این ارتباطها میتونه کلاً وجود نداشته باشه
پس هرچی ارتباطها بین جداول ما وجود نداشته باشه سرعت کوئری گرفتن در سیستم بالاتر میره ولی وقتی بخوایم تو همچین سیستمی insert کنیم از اونجایی که ما هیچ کلیدی بین ۲ جدولمون نداریم اگه بخوایم یه کوئری insert بنویسیم که فرضاً یه رکورد خاصی رو به جدول ما اضافه بکنه حالا این رکورد اگر ارتباط داشته باشه با جداول دیگه باید دوباره یه insert بنویسیم که دوباره بره اون کار رو انجام بده پس همین فرآیند transactionای ما توی insert در سیستم OLAP خیلی زمانبر و طولانی میشه
اگه شما یه سیستم D.W راهاندازی کرده باشید میبینید که توی سیستمهای D.W ما ماهی یکبار شاید فرآیند ETL رو اجرا کنیم و این فرآیند ETL که در نهایت insert کردن توی D.W رو انجام میده خیلی زمانبر میشه
از اونطرف ما سیستمهای OLTP رو داریم که با توجه به روابطی که بین جداولش وجود داره و constraintهایی که براش تعریف کردیم این مناسب برای انجام transactionه مثل insert, update, delete روی این سیستمها هم ما میتونیم کوئری بزنیم و گزارشگیری کنیم ولی اگه شما یه گزارش سنگین روی این سیستم بذارید متوجه میؤید که زمان پاسخدهی خیلی بالا میره
پس این ۲ نوع دیتابیس در مقابل هم هستند
تفاوت OLTP و OLAP
|
پارامترهای ارزیابی |
OLAP |
OLTP |
|
کاربران |
کارکنان دانش |
کارکنان فناوریاطلاعات |
|
کارکرد |
پشتیبانی تصمیم |
عملیات روزانه |
|
طراحی پایگاهداده |
موضوعگرا |
کاربرد گرا |
|
داده |
سابقه، خلاصهشده، چندبعدی، سر جمع، یکپارچه |
جاری، بهروز، با جزئیات، رابطهای، منفرد |
|
کاربرد |
خاص منظوره |
عملیات تکرار شونده |
|
دسترسی |
پویش سراسری و گسترده |
خواندن، نوشتن، اندیسگذاری یا درهمسازی بر روی کلید اصلی |
|
واحد کاری |
پرس و جوهای پیچیده |
تراکنشهای ساده و کوتاه |
|
تعداد رکوردهای مورد دسترسی |
میلیونها رکورد |
دهها رکورد |
|
تعداد کاربران |
هزاران کاربر |
صدها کاربر |
|
اندازه پایگاهداده |
گیگابایت - ترابایت |
مگابایت - گیگابایت |
|
معیار سنجش |
بازده پرس و جو (جامعیت، همبستگی، سرعت و Throughput) |
بازده تراکنش (سرعت و Throughput) |
- ازنظر کاربران: توی سیستم OLAP کاربران، کارکنان دانش میان و از سیستم استفاده میکنند یعنی افرادی که قراره یه تحلیلی رو به دست بیارند یا بیان یه گزارش خیلی سنگین رو بگیرن و درنهایت روی اون تصمیمگیری انجام بدن ولی توی سیستم OLTP کاربران، کارکنان فناوریاطلاعات هستند یعنی هرکسی که میشینه پشت کامپیوتر و فرضاً نامه ثبت میکنه پس اطلاعاتش میره رو سیستمی که از نوع OLTP هست ذخیره میشه
- از نظر کارکرد: کارکرد OLAP پشتیبانی سیستمه یعنی ما هیچ عملیات روزانهای روش انجام نمیدیم و فقط یکسری گزارش ازش میگیریم و پروسه تصمیمگیری رو طی میکنیم ولی توی عملیات روزانه ما داریم به صورت روزانه فرضاً نامه ثبت میکنیم، سند حسابداری ثبت میکنیم پس ما نمیریم توی D.W یا هر سیستمی که OLAPه این دیتا رو وارد کنیم میایم توی یک سیستم OLTP (ساختار دیتابیسی به صورت OLTP) که ارتباط بین جداول تعریف شده باشه اطلاعات رو وارد میکنیم چون اگه بخوایم مثلاً یک سند حسابداری رو توی یک سیستم OLAP بزنیم خیلی زمان میبره ولی توی یک سیستم OLTP این خیلی سریع انجام میشه یا برعکسش اگه بخوایم اسناد حسابداری ۲۰ سال اخیر رو ازش یه گزارش بگیریم هیچوقت نمیام تو یک سیستم OLTP این کار رو انجام بدم چون اگه یه سازمانی باشه با یک دیتای خیلی زیاد ممکنه یک گزارش خیلی سنگین حتی براش ۶-۷ ساعت هم زمان ببره
- از نظر طراحی پایگاهداده: توی OLAP سیستمها موضوعگرا هستند ولی توی OLTP کاربردگرا هستند مثلاً من یک سامانهی حسابداری که طراحی میکنم هیچوقت دادههای مربوط به اتوماسیون درونش قرار نمیگیره پس این سیستم یک سیستم OLTP ه و کاربردش مثلاً برای حسابداریه | ولی توی سیستم OLAP ممکنه دادههای من از انواع مختلفی باشه من اگه یه OLAP ای برای واحد حسابداری درست کنم ممکنه یکسری از دادههای مربوط به حسابداری توی سامانه اتوماسیون اداری باشه و یکسری دیگه تو سامانه حسابداری باشه پس همه اینها همون Extract ما است و درنهایت یکجا جمعآوری میشه Aggregationو اینها توی یک D.W قرار میگیره
- از نظر داده: هیچوقت متن نامه در D.W قرار نمیگیره و فقط اطلاعات کلی که این شماره نامه بوده و تاریخ ارسالش این بوده و تاریخ ثبتاش این بوده و شخص فرستندهاش این بوده و گیرندهاش هم فلان شخص بوده و درکل همینطوری ولی توی OLTP ما تمام چیزها از جمله پیوست، سابقه، گردش، پاداش و ... رو قرار میدیم پس یک دیتابیسیه با جزئیات خیلی بیشتر نسبت به دیتابیس OLAP
- از نظر کاربرد: خاض منظوره توی OLAP یعنی میایم ازش گزارش میگیریم ولی توی OLTP یعنی مثلاً هر روز ما نامه داریم و گزارش خاصی ازش نمیگیریم.
- از نظر دسترسیها: OLAP گسترده و سراسریه یعنی میتونیم بیایم دیتا رو به صورت گسترده بخونیم و بگیریم گزارشها رو ولی توی OLTP اینجوری نیست خواندن، نوشتن و کارهای روزمره رو انجام میدیم
- از نظر واحد کاری: در OLAP پرس و جوها پیچیده است و گزارشگیریها سنگین است ولی توی OLTP تراکنشها ساده و کوتاه هستند مثل: insert, delete پس دیگه نمیایم یک گزارش سنگین از سیستم بگیریم
- از نظر تعداد رکوردهای مورد دسترسی: به صورت ذهنی OLAP میلیونها رکورد داره و OLTP دهها رکورد (البته این از لحاظ ذهنیه وگرنه الان سیستمهای OLTP داریم که طرف با یک تراکنشی که انجام میده یهو ۱۰۰ تا رکورد رو تغییر میده توی یک سیستم (یا ممکنه من از ورودی فقط یک شماره نامه گرفته باشم ولی برای دادن اطلاعات ۱۰ها جدول رو درگیر کرده باشم)) از اونطرف در OLAPما میلیونها رکورد داریم و البته ممکنه ما یک گزارشی بزنیم که بیشتر از میلیونها رکورد رو برای ما برگردونه
- از نظر تعداد کاربران: به صورت فرضی OLAP هزاران کاربر و OLTP صدها کاربر رو شامل میشه
- از نظر اندازه پایگاهداده: به صورت فرضی در OLAP گیگابایت - ترابایت و در OLTP مگابایت - گیگابایت توجه کنید این به صورت فرضیه مثلاً الان ما سیستمهای OLTP داریم که چندین ترابایت حجم دارند و کمتر سازمانی هست که از یک ساختار مشخصی برخوردار نباشه و روال کاریش درست نباشه پس یک دیتابیس OLTP میتونه چندین ترابایت هم باشه ولی چون ما از چند دیتابیس OLTP میایم OLAP درست میکنیم قطعاً حجم OLAP ما بیشتر از یک دیتابیس OLTP است.
- از نظر معیار سنجش: توی سیستمهای OLAP معیار سنجش بازده پرس و جو است همون سرعت پاسخگویی روی کوئریهای سنگین ولی توی OLTP بارده تراکنش است یعنی کابر ما نباید برای ثبت یک تراکنش معطل بشه ولی توی OLAP اگه برای اجرای یک گزارشی کاربر ما ۵ دقیقه هم معطل شد این اصلاً مهم و قابل شکایت نیست و این طبیعت سیستمه و فرضاً مطمئن باشید اگه یه کوئری توی سیستم OLAP ۵ دقیقه طول میکشه خیلی بیشتر توی OLTP طول میکشه.
روش بدستآوردن و تبدیلداده در روش سنتی
ما در کلیکویو از ابزار مدرن برای اینکار استفاده میکنیم ولی امکان تلفیق سنتی و مدرن هست
روش سنتی بر پایهی OLAP است.
بهتره بدونید دیتابیسهای OLAP دارای ۳ نوع مختلف هستند:
- ROLAP(Relational Online Analytical Processing)
- MOLAP(Multidimensional Online Analytical Processing)
- HOLAP(Hybrid Online Analytical Processing)
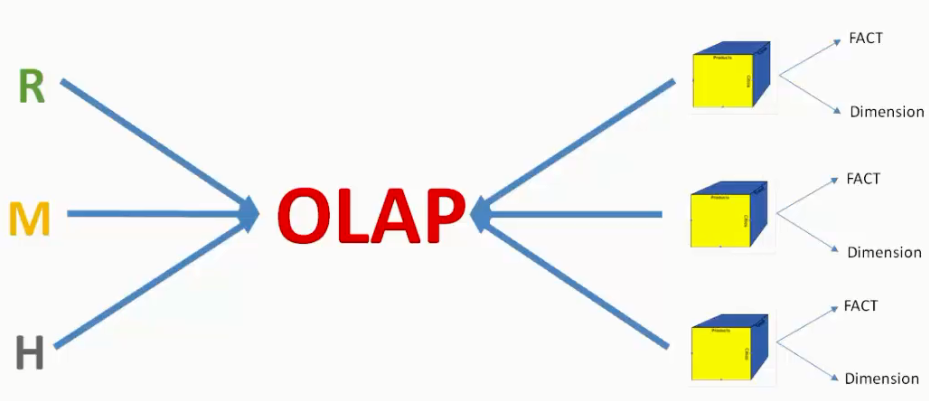
هر OLAP برای ما تشکیل یک مکعب رو میده و هر مکعب هم تشکیل شده از Fact و Dimension مربوط به خودش
منظور از مکعب: وقتی میگیم مکعب منظورمون اینه که مثلاً کاربر من احتیاج داره که بدونه تعداد نامههای سازمانش چقدره برای اینکار ما باید بهش یک مکعب بدیم و مکعب ما fact و dimension داره و fact ما میشه تعدادنامه و اگه بخوایم تعداد نامههای سازمان رو براساس واحد/ فرستنده/ گیرنده خاصی بخوایم و به همین ترتیب هرکدوم از این شرطها رو براش تعریف کنیم میشه dimenstion ما
مثال:
تعداد نامههای سال ۱۳۹۰: پس این میشه یک بعد زمان
تعداد نامههای سال ۱۳۹۰ واحد IT: این میشه یک بعد واحد
پس تو روش سنتی به این شکله که ما میایم یک دیتابیس OLAP رو انتخاب میکنیم و مکعبهایی رو تشکیل میدیم و هر مکعب نیز تشکیل شده از یک Fact و یک Dimension
Fact = اصل =>مثال: تعداد نامه
Dimenstion = بُعد
مثالی برای مکعب
کاربر ما احتیاج داره که یک گزارشی از مبلغ فروش بهش بدیم.
پس ما میایم ازش میپرسیم که مبلغ فروش رو بر چه اساسی میخوای پس الان fact ما مشخص شده (مبلغ فروش)
حالا کاربر ما میاد و بعدهای لازم رو به ما میده و برای ما یکسری شرط تعیین میکنه فرضاً میگه از نظر زمان (مبلغ فروش سال ۱۳۹۲)، نوع محصول (شرکت من چندین نوع محصول داره پس مبلغ فروش برای بعد زمان ۱۳۹۲ و نوع محصول x رو به من بده)، شهر (توی شهرهای مختلفی محصول فروش میره پس مشخص میکنه که برای کدوم شهر رو میخواد)، نماینده (توی هر شهری فرضاً ما یکسری نماینده فروش داریم پس مبلغ فروش برای فلان نماینده رو میخواد)
ما وقتی بیایم این مکعب رو برای کاربرمون تشکیل بدیم از اون به بعد هر وقت کاربرمون بخواد گزارشی بگیره که براساس زمان، نوع محصول، شهر و نماینده باشه فقط کافیه بیاد زمان مورد نظرش رو تعیین بکنه بعد محصولش رو بعد شهر و نمایندهاش رو تا به نتیجه دلخواهش برسه

معایب روش سنتی
خب چرا ما میریم سراغ روش مدرن و چه دلیلی داره که از روش سنتی استفاده نکنیم.
خب نمیشه گفت که روش سنتی بلا استفاده است و رد میشه و به هیچوجه کاربردی نداره و روش مدرن تنها روش درست برای استفاده کردنه
در حقیقت چون من بیشتر روی روش مدرن تمرکز کردم پی معایب روش سنتی رو لیست میکنم که چرا تصمیم گرفتم برم سراغ روش مدرن
محدودیت کاربران = یکی از معایب روش سنتی محدودیت کاربرانشونه یعنی کاربر محدوده که از مکعبهایی که براش طراحی شده استفاده بکنه ولی ما تو روش مدرن این محدودیت رو نداریم چون تمام روابط موجود در دیتابیس رو میخونیم و میاریم بنابراین کاربر هر گزارشی که بخواد رو میتونه بهش برسه
(فرضاً تو مثال قبل اگه بعدهای تعریفی ما برای کاربر فقط زمان، شهر و نماینده بود کاربر ما مجبور بود فقط از اون استفاده بکنه و نمیتونه بیاد یه فیلتر دیگهای بر اساس فرضاً نوع محصول داشته باشه و اگه مثلاً همچین چیزی رو میخواست باید درخواست میداد تا من براش این مکعب رو تغییر میدادم)
پیچیدگی طراحی Cube جدید = فرضا کاربر درخواست داده من براساس گزارشی که میخواد یه فیلتر خاصی براش ایجاد بکنم پس باید این Cube طراحی بشه پس چون طراحی Cube راحت نیست و احتیاج به تخصص داره ولی چون تو روش مدرن من همه روابط رو آوردم و دیتام موجوده پس تا چند مرحله بعد نیاز کاربر رو دیدم
سرعت کم = نسبت به سیستمهای مدرن سرعتش کمتره
هزینه بالا = هزینه پیادهسازی و راهاندازی چه از نظر فنی و سختافزاری و منابع بالاتره
معرفی روش مدرن
روشی که توی کلیکویو استفاده میشه روش AQL ه
AQL = Associated Query Logic
در حقیقت تمام اتفاقاتی که توی روش سنتی میوفته توی روش مدرن هم میوفته ولی بدون اینکه کاربر خیلی درگیر طراحی DW به صورت جزئی بشه
در حقیقت کاربر فقط کوئری مزینه و DW تشکیل میشه
نکته: خیلی جاها بهتره از روش سنتی استفاده کنیم و خیلی جاها بهتره از روش مدرن استفاده کنیم. خیلی جاها هم هست بهتره این ۲ تا رو باهم ترکیب کنیم یعنی مثلاً از روش سنتی برای تسشکیل DW و ETL امون استفاده کنیم و برای طراحی سیستم از روش مدرن
توی روش مدرن ما دیگه بحث DW و تشکیل مکعب رو نداریم و هردوی اینها به صورت منطقی و خودکار تشکیل میشه
ما کوئری موردنظرمون رو میزنیم دیتا خونده میشه از دیتابیس و دیتا میاد توی RAM قرار میگیره یا مخزنی که نرمافزار برای اینکار درست کرده حتی اگه دیتا رو توی دیتابیسی ذخیره کنه دائمی نیست و هر دفعه که ما از سیستم استفاده میکنیم دیتای درخواست من منتقل میشه به RAM پس توی سیستمهای مدرن ما نیاز به RAM بالایی داریم که تو خیلی از موارد این مشکل بزرگیه

 سهیل
سهیل