سناریو
به عنوان DBA یک بانک که در ایران و اروپا دفتر دارد مشغول کار هستید. بانک شما ۲ تا دیتابیس اوراکل 12C مجزا بر روی دو container مجزا در دفاتر اصلی خود دارد. شما نیاز دارید که برخی از جداول را از اسکیمای IR به اسکیمای EURO ببرید برای رسیدن به این هدف میتوانید Oracle GoldenGate for Oracle 12c را امتحان کنید.
شما برای امتحان حتماً دارید از یه محیط توسعه و آزمایشی استفاده میکنید (جدا از نگرانیهای محیط عملیاتی) که این محیط آزمایشی میتونه روی یه PC هم باشه ولی یادمون باشه در محیط عملیاتی دیتابیس EURO و IR از هم جدا هستند.
دستهبندی
- DB = دیتابیس
- EDW = انبارهداده سازمانی (Enterprise Data Warehouse)
- ETL = فرآیند Extract, Transform, Load
- HW = سختافزار رایانهای (Intel 32-bit, Intel 64-bit, SPARC و خیلی محصولات دیگه)
- ODS = محل ذخیره گزارشهای عملیاتی بر روی EDW
- OLTP = دیتابیس تراکنشی
- OS = سیستمعامل (ویندوز، لینوکس و خیلی محصولات دیگه)
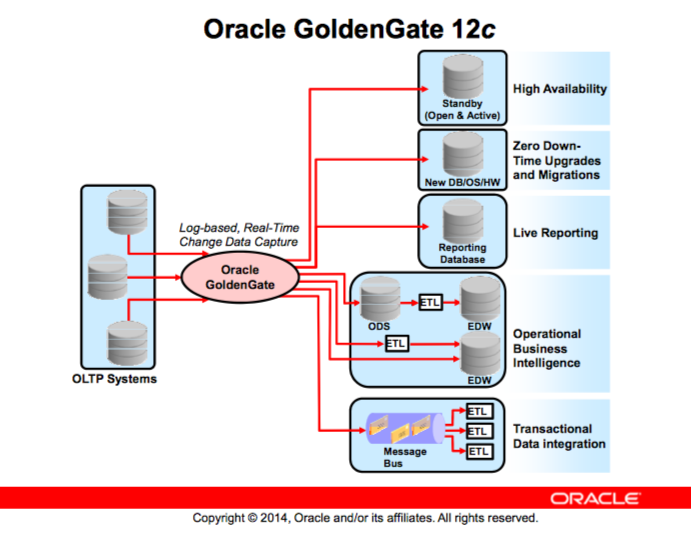
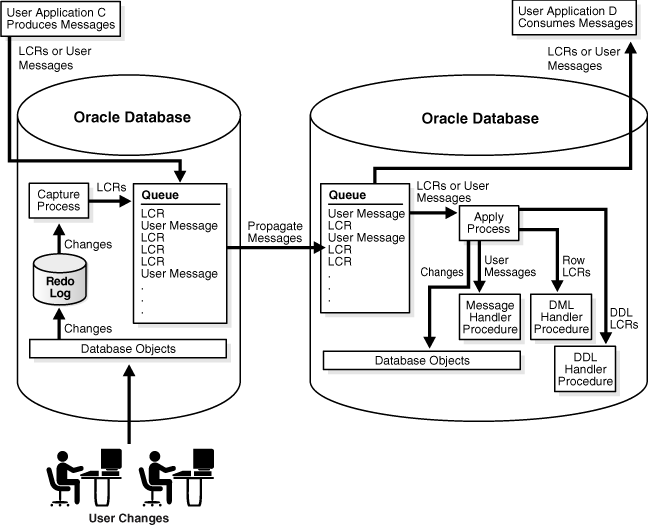
اوراکل گلدنگیت یکی از محصولاتیه که تاثیرات خیلی کمی موقع کپچر اطلاعات(capture)، مسیریابی(routing)، تفییر اطلاعات(transformation) و انجام تراکنشهای مختلف در پایگاهدادههای مختلف داره تقریباً زمانی نزدیک به زمان بیدرنگ
اوراکل گلدنگیت تبادل و تغییر دادهها رو در سطح پایگاهدادههای مختلف و سیستمعاملهای مختلف به صورت بیدرنگ انجام میدهد همچنین یکپارچگی تراکنشها رو با زمان تاخیر خیلی کم نزدیک به بیدرنگ انجام میدهد.
همچنین قابلیت پیادهسازی سولوشنهای high availability و zero down time برای انواع upgrades یا migrations و live reporting و operational business intelligence و transactional data integration را به ما میدهد.
بخشهای مهم برای یادگیری
- معماری گلدنگیت
- سناریوی گلدنگیت به صورت یکطرفه و سناریوی گلدنگیت به صورت دو طرفه با دستورات DDL و DML
- پارامترهایی که به صورت روتین به اونها احتیاج داریم
- ابزارها و روشهای نگهداری از گلدنگیت
نکات مهم
یکی از مسائل مهمی که معمولا در GG هستش نگهداری یا Maintense اون سخت تر از نصب و راهاندازیاش هستش
در حقیقت مشکلاتی که موقع کار با این ابزار میخوریم و trace انها و شناخت مشکلات و حل اونها معمولا یکم DBA ها رو بیشتر اذیت میکنه اما خوبیش اینه که این به صورت یک مهارت هستش و اگه ما به اون skill برسیم که بفهمیم از کدوم نقطه باید شروع بکنیم و تا کدوم نقطه باید برای رفع خطا بریم و کجاها رو باید سر بزنیم و چه نوع لاگهایی رو بخونیم کارمون بسیار راحتتر میشه و دیگه سختی قبل رو نداره
اگه هدف شما این باشه که از GG در شبکه داخلی خودتون استفاده بکنید به مراتب کار راحتتر هستش چون بخش بزرگی از مشکلات GG به خاطر مشکلات شبکهای هستش و زیرساخت شبکهای درکل بسیار حائز اهمیت هستش
ویژگیهای کلیدی اوراکل گلدنگیت

اوراکل گلدنگیت:
- به عنوان یه middleware برای طراحی و کار در یک محیط hetrogeneous با سیستمهای مدیریتی پایگاهداده رابطهای(RDBMS) مختلف
- انتقال دیتاهای commit شده در سیستمهای مختلف که به تاخیر لایه دوم معروف هست. (در پایگاه داده اوراکل بین دادههای commit شده نوشته شده در دیسک و commit نشده تفاوتهایی وجود داره که در redo log تاثیر میذاره)
- دادهها رو براساس پروتکل TCP/IP در شبکه منتقل میکنه و نیازی به پروتکل Oracle Net نداره
- با سیستم منحصر به فرد خودش نگهداری و یکپارچگی دادهها رو انجام میده و از مفاهیم چند منظوره مثل معماری پایگاهداده اوراکل استفاده نمیکنه.
- قابلیت انتقال سریع دادهها رو به یک پایگاهداده آماده به کار داره که این خود میتواند از فاجعههایی جلوگیری بکنه
- با استفاده از CSN تراکنشها رو شناسایی میکنه (Commit Sequnce Number) که بیس آن SCN پایگاهداده اوراکل است
نیاز به گلدنگیت
زمانی سازمانها دنبال پیادهسازی سیستمهایی بودن که به وسیلهی اون سیستم بیان فرآیندهای اداریاشون رو اتوماتیک انجام بدن (اتوماسیون، BPMS، ERP، CRM) هدف همهی این نرمافزارها اتوماتیک کردن یکسری از فرآیندهای سازمان به صورت تجمیعی هستش
اتوماتیک کردن این فرآیندها در یک سیستم و بستر نرمافزاری و قاعدتا این هدف ما رو به تجمیع اطلاعات میرسونه

نیازی که در آینده برای سازمانها به وجود اومد این بود که میخواستن در آینده این اطلاعات رو در باقی پایگاهدادهها توزیع بکنن (Distributed Data) فرضاً وزرات کشور به عنوان یک سازمان حکومتی داره دیتای تمام کشور رو به صورت تجمیع نگهداری میکنه حالا برای پاسخ به یک نیازی یکی از سازمانها نیاز به اطلاعاتی داره که در پایگاهدادههای وزارت کشور قرار گرفته یا استانداری هر استان نیاز به اطلاعات بروز از این دیتابیس دارند.

یا برعکسش رو فکر کنید ما یکسری سامانه در هر استان داریم که وزارت کشور به عنوان یک سازمان حکومتی باید اطلاعات این سامانهها رو داشته باشه و به صورت تجمیعی اونها رو نگهداری و دستهبندی کنه
پس نیازی به وجود اومده که ما دیتا رو توی دیتابیسهای مختلف توزیع کنیم حالا این توزیع میتونه به عنوان broadcat باشه یا به صورت integreaty باشه و بخوایم دیتای ما تجمیع بشه در کل به هر شکل این نیاز به وجود اومده
یکی از راهکارهایی که برای رفع این نیاز انجام میدن به این صورته که هر ۲ ساعت یکبار یا هر شبانه روز یکبار یا در طول روز ۳ یا ۴ بار ما اطلاعات رو بین دیتابیسها به صورت batch فایل یا با ابزارهای ETL توزیع دیتا رو انجام بدیم و دیتا رو جا به جا بکنیم
حالا نیاز ما هی داره پر رنگتر میشه مثلا ما میخوایم سامانهای بنویسیم که احتیاج به تغییرات آنلاین دیتا در دیتابیس مرکزی وزارت کشور هستش
خب وقتی ما میخوایم تغییرات رو به صورت آنلاین داشته باشیم نمیتونیم از ابزار یا راهکاری استفاده بکنیم که هر ۲ ساعت یکبار اینکار رو انجام بده
مثلا یکی از سامانههای من این هستش که میخوام براساس رفتار یکی از استانها مرزی SMS ای رو برای ضینفعان اون در وزارت کشور بفرستم پس اینجا نیازه من دیتا رو به صورت آنلاین در اختیار داشته باشم
تمام این نیازها در کنار هم قرار گرفت و یک نیاز دیگه به اونها اضافه شد اینکه تمام vendorهای دیتابیس من در سازمانها یکی نیست و از vendorهای مختلفی هستند (Oracle, Microsoft, DB2, ...) ولی من نیاز دارم دیتا رو بین همهی اینها همش به بازی و گردش دربیارم پس این نیاز هم به نیازهای دیگهی من اضافه شد
هر کدوم از این نیازها متناسب با زمان خودش توسط vendorهای مختلف تکنولوژی نظیر مایکروسافت و آیبیام و اوراکل راهکارهایی رو براش ارائه دادند.
CDC
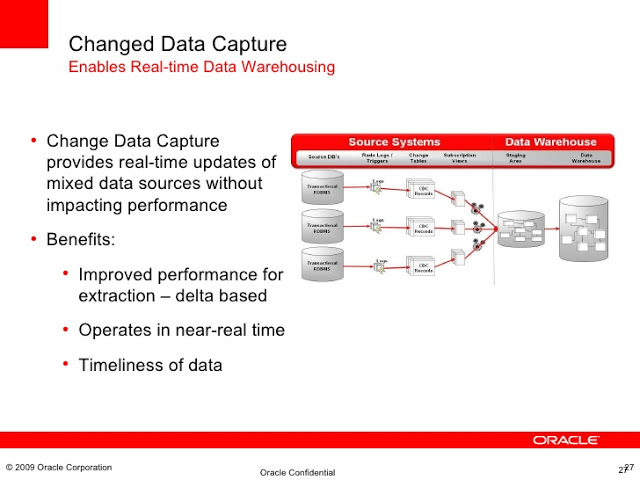
ما به تمام این راهکارها اصطلاحاً میگیم (CDC (Change Data Capture یعنی ما میایم تغییرات دیتا رو جا به جا میکنیم
یه موقع تغییرات ما ۰ تا ۱۰۰ دیتا هستش که در حقیقت Initial Load ما اتفاق میافته
یه موقع تغییرات روزانه ۱۰ هزار رکورد هستش که ما فقط میخوایم ۱۰ هزار تا رو جا به جا کنیم
سادهترین راه برای اینکار نوشتن اسکریپت SQL ای با mines هستش(آخرین وضعیت رو با وضعیت فعلی mines میزنیم و میفهمیم چه رکوردهایی تغییر کرده) که همین الان هم مرسوم هستش و در بسیار از DWها استفاده میشه
نکات مهم
- ایجاد فلگ روی آپدیتها خیلی کاربردی نیستش اونجاهایی که ما fact داریم خوبه میتونیم فلگ بذاریم که هر مرحله بفهمیم تا کجا دیتا رو آوردیم (timestamp یا sequnce یا id آخرین رکورد درج شده رو میتونیم ذخیره کنیم) ولی روی dim زیاد کاربردی برای ما نداره و نمیتونیم به راحتی اینکار رو انجام بدیم
- در dimها نیز SCD ها به همین شکل عمل میکنن و با typeها گوناگون و انواع اقسام در type 2 به همین شکل است یعنی اصل موضوع تغییرات روی اطلاعات پایه است و تغییرات روی اطلاعات تراکنشی اصلاً معنی ای نداره چون یک تراکنش که مثلاً پارسال خورده خیلی به ندرت آپدیت میشه (مثلاً حتی اگه در اتوماسیون ما نامهای رو به اشتباه زده باشیم قاعدتاً دیگه نباید به اون نامه دست بزنیم و اگه نیاز به ویرایش باشه باید یه نامه جدید بخوره)
- factهای ما که از جنس log هستن معمولاً هیچوقت نباید آپدیت بشوند
- در سیستمهای بانکی هر تراکنشی که میخوره یک سند مالی هستش و با توجه به دستور بانک مرکزی هیچ تراکنشی نباید آپدیت بشه و اگه بخواد سندی آپدیت بشه باید یک سند جدید بخوره و سند قبلی به هیچ عنوان نباید آپدیت بشوند
- در تمام اصلاحیات سندهای مالی باید فلگهای انقضای سند قبلی با time مربوطه باشه وگرنه اگه سندی برای سال ۹۰ در سال ۹۵ رکوردش آپدیت بشه چون سندهای سال ۹۰ از قبل حسابگری شدن و تراز مالی خوردن باعث اخلال در سیستم حسابداری معین و تفضیلی و جز میشه
هر vendor دیتابیسی معمولاً یک ابزار CDC معرفی میکنه و یا به صورت دستی برنامهنویسان CDC رو مینویسند (مثلا یک batch بنویسیم که با mines تغییرات رو پیدا کنه و insert کنه در دیتابیس مورد نظر)
مایکروسافت هم در ابزار SSIS امکان انجام دادن CDC رو مهیا میکنه یا تو خود دیتابیس Oracle ما فانکشنهای داخلی PL/SQL ای برای CDC داریم و میتونیم فرآیندهامون رو تعریف کنیم
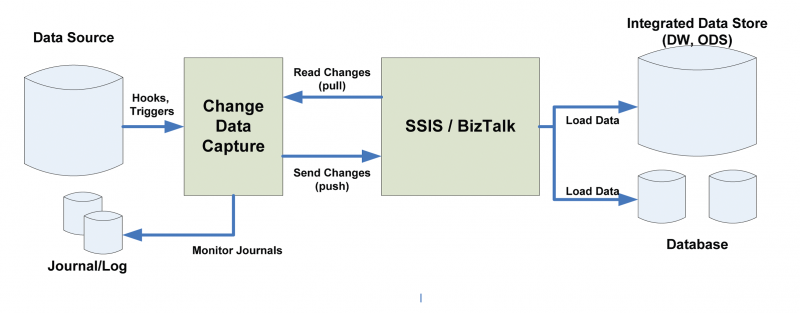
خب CDC نیازهای ما رو در بازههای زمانی مختلف برطرف میکرد ولی ما نیاز داشتیم به صورت لحظهای تغییرات دیتا رو داشته باشیم مثلاً همون موقعی که تو سیستم مالی سندی درج شد در سیستم دیگهای اون سند رو داشته باشم
پس نیاز به این بود که در Distrubuted دیتای ما دیتای تغییرات رو به سرعت داشته باشیم و آخرین وضعیت دیتا همیشه در اختیارم باشه
اینجا Online CDC رو مطرح کردند که تغییرات و کپچرها به صورت آنلاین اتفاق بیوفته به این صورت که ابزار یا اسکریپت CDC ما به صورت لحظهای ارا میشد و تغییرات رو پس از شناسایی به دیتابیس distrubuted منتقل کنه
مثلا اگه ما بخوایم یک Replication در سطح دیتابیس با CDC راه اندازی کنیم چه اتفاقی میافته؟
تو replication قرار بر این نیست که هر لحظه که یک رکورد دیتا تغییر کنه کل دیتا به سمت دیتابیس مقصد بره و اونجا تغییرات دوباره استخراج بشه و بیاد سمت دیتابیس مبدا
ما وقتی replication داریم اولاً هر ۲ دیتابیس ما آنلاین هستن و قابلیت read و write دارند ثانیاً ما باید یک مکانیزم یا ابزاری داشته باشیم که فقط تغییرات رو به صورت آنلاین از هر ۲ طرف بیاره و جا به جا بکنه از این سناریوی replication میشه برای سایتهای DR به صورت Hot Standby استفاده کرد و شما هر وقت اراده بکنید میتونید روی دیتابیس DR عملیات انجام دهید
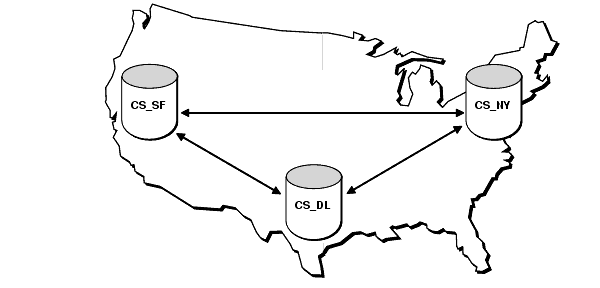
اولین ابزار و راهحل سناریوی replication شرکت اوراکل Advanced Replication بود که تا نسخه ۹ اکثراً با این کار میکردند. بعداً با توجه به مکانیزم سخت این سناریو و Overheadهایی که میذاشت و Maintenanceهای سختش اوراکل مکانیزم Streams رو معرفی کرد که ادمینها با این تولز راحتتر بودن و درکل عملکرد بهتری داشت حالا یک مسئلهای ایجاد شده که تمام دیتابیسهای سازمان از vendor اوراکل نبود که ما با streams بتونیم همهی نیازها رو برطرف کنیم گاهاً مجبور میشدیم از چند ابزار برای جا به جایی دیتا بین vendorهای مختلف استفاده کنیم پس نیاز این بود که ما بین vendorهای مختلف مثلاً MySQL, Sybase, DB2, SQL Server, ... یک replication راهاندازی کنیم.
ابزارهایی که اوراکل تا الان برای replication معرفی کرده بود نمیتونستن بین ۲ وندور مختلف دیتابیس قرار بگیرن و حتماً باید ۲ طرف اوراکلی میبودند. اگه هم ما یک سناریوی رینگ بیس راهاندازی میکردیم همهی دیتابیسها باید اوراکل میبودند.
بعد از اینکه اوراکل دید نیازی به گونهای شده که باید راهحل جامعتری پیادهسازی بشه دست به تولید ابزار GoldenGate زد
Oracle GoldenGate تمام اون قابلیتهای قبلی که نیاز ما بوده رو داره و امکان پیادهسازی بین دیتابیسهای ناهمگون از vendorهای مختلف دیتابیسی رو داره با کلی فیچر جدید و performance بالاتر از باقی ابزارها
ما در Oracle GoldenGate میتونیم بالاترین سطح تغییرات رو داشته باشیم و قابلیت کار به صورت passive رو نیز داره یعنی زمانبندی برای انجام هر کدوم از وظایفش تعیین کنیم
- بهترین ابزار ETL آنلاین اوراکل GG هستش در راهکارهای کنونی در دنیا داشتن یک انباره داده که به صورت passive نباشه به شدت مورد نیاز هستش چون دیتابیس انباری که شبانه یا روزانه مثلا ۲ بار آپدیت میشه دیتابیس خیلی کارایی برای ما نمیتونه باشه پس ما نیاز به realtime datawarehouse داریم که به صورت لحظهای ساختار OLAP با ساختاری OLTP ما SYNC باشه یا با زمانی خیلی اندک
گلدن گیت این امکان رو به سادگی به شما میده شما میتونید با ابزارهای ETL دیگه بیاین و سناریوی ETL اتون رو طراحی کنید و از گلدن گیت به عنوان زیرساخت کار استفاده کنید و اون رو مدیریت بکنید یا اگه با PL/SQL اسکریپتهای ETLاتون رو نوشتید با ترکیب گلدن گیت میتونید یک سناریوی آنلاین داشته باشید
حالا به نظرتون realtime datawarehouse دقیقاً چه کاربردهایی داره و کجاها واقعاً به درد میخوره؟
توی تحلیلهای از جنس خطا شناسی شما هر چقدر دیتاتون به لحظه باشه خیلی سریعتر میتونید تصمیمسازی کنید مثلا در BI موقع تحلیل دیتاها و پیدا کردن علت معلولها و آیندهنگری شما وقتی میتونید از نتیجه این گزارش استفاده کنید که به لحظه تحلیل اون رو انجام داده باشید و بعد از چند ماه یا با اختلاف زمانی با این خطا برخورد نکنید (مثلاً یک پولشویی یا اختلاسی یا ...)
وقتی میخوایم خطا شناسی کنیم و fraudها رو پیدا کنیم باید سراغ Operational Intelligence بریم مثلاً وقتی یک عمل انجام شده در لحظه با عملهای دیگه ترکیب بشه احتمال وقوع یک fraudای رو بالا میبره پس اگه همون موقع بتونیم جلوی عمل رو بگیریم باعث win ما میشه
اینجا دیگه ما با passive datawarehouse نمیتونیم fraud رو شناسایی کنیم و باید با تعریف گرافهایی در OI که هر گراف مثلاً ۱۰ گام داره و اگه تا گام ۸ کسی پیش بره یعنی fraud ما در حال تکمیله دیگه نباید بذاریم به گام بعدی انتقال پیدا کنه
ابزار GoldenGate یکی از بهترینها برای پیادهسازی OI در سطح vendorهای مختلف دیتابیسی هستش
ابزارهای مشابه با Oracle GoldenGate هم زیاده مثلاً یک درایوری هستش که روی SSIS هم سوار میشه به اسم attunity که اینم مثل گلدن گیت میتونه براتون Online CDC رو پیادهسازی کنه
https://www.attunity.com/content/microsoft-connectors-attunity/
https://www.microsoft.com/en-us/download/details.aspx?id=52950
اما بهتره تو سازمانی که اکثر دیتابیسهاش اوراکل هستش از گلدن گیت استفاده بکنیم البته گلدن گیت محدودیتی نداره و میتونید از گلدن گیت برای ریپلیکیشن بین DB2 و SQL Serevr استفاده بکنید و یا بین ۲ دیتابیس SQL Server و درکل هیچ مسئلهای نداره
شعار اوراکل برای گلدن گیت ابزار platform less هستش یعنی هیچ وابستگی به هیچ سیستمعامل و دیتابیسی وجود نداره گلدن گیت نسبت به تمام ورژنها و سیستمعاملها transparent هستش
پس ابزاری که به هیچ سیستمعامل و پلتفرمی وابسته نیست و امکان راهاندازی انواع سناریوهای ریپلیکیشن رو با بهترین سرعت و کارایی بین وندورها و ورژنهای مختلف دیتابیس با سیستمعاملهای مختلف داره بسیار برای ادمین در دیتاسنتر میتونه مفید و ضروری باشه
حالا گلدن گیت فقط به درد ریپلیکیشن نمیخوره شما میتونید از گلدن گیت به هر شکلی که نیازتونه استفاده کنید در حقیقت بیشتر شبیه به یک فریمورک هستش که شما میتونید از اون به هر شکلی در سازمان برای رفع نیازهای متفاوت استفاده کنید
کاربردهای گلدن گیت
ما تصمیم گرفتیم دیتاسنترمون رو جا به جا کنیم یا قراره ورژن دیتابیسها عوض بشه و آپگریدی صورت بگیره مثلاً از ورژن 11.2.0.3.0 قراره بریم به دیتابیس 12.2.0.1.0 (یا میخوایم وندور دیتابیسهامون رو عوض کنیم) الان هم حجم دیتابیسهای دیتاسنتر زیاده و کارکرد اپلیکیشنها هم بالاست کلی هم پلن توجیهی برای آپگرید دیتابیسها داریم ولی نمیتونیم قطعی داشته باشیم (Zero Downtime) خب پس از یک طرف مجبوریم آپگرید کنیم و از طرفی نمیتونیم Downtime براش بدیم
حالا باید سراغ راهحلهای migrate و upgrade به صورت Zero Downtime بریم

یکی از راهحلها استفاده از GoldenGate هستش به این صورت سایت جدید رو بالا میاریم ریپلیکیشن یکطرفه بین ۲ سایت ایجاد میکنیم و تو یه مقطع زمانی که پیک کاری خیلی پایینه یه downtime چند ثانیهای میگیریم و tnsها رو جا به جا میکنیم و اتصال به دیتابیس جدید انجام میشه دیتابیس جدید هم تا آخرین لحظه با دیتابیس قبلی sync بوده، پس بدون هیچ downtime ای ما این کار رو انجام دادیم
یکی دیگه از راهحلهای اوراکل برای اینکار راهاندازی سایت DR (اکتیو دیتا گارد) به صورت logical standby هستش چون به صورت logical شما دارید از معماری streaming استفاده میکنید ولی توی physical standby شما دارید از معماری recovery استفاده میکنید
سناریوی recovery یعنی چی: وقتی شما یه RMAN رو میاین restore میکنید برای اینکه به اون نقطه زمانی خاص مدنظرتون برسید میاد لاگها و incremental backupها رو به صورت توالی ریکاور کردن
physical standby هم با این سناریو برای شما سایت DR رو راهاندازی میکنه یعنی redo entry ها رو که تو ۳ حالت میتونن باشن (توی RAM یا توی Online Redo Log یا توی Archive Redo Log) رو برمیداره میاره و روی سایت DR ریکاور میکنه درکل برای همین هستش که سرعت خوبی داره و شما هر تغییر توی ساختار primary اتون میدید همیشه توی standbyاتون هست
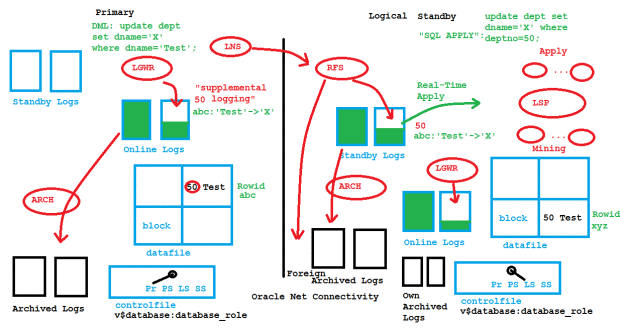
توی logical این اتفاق نمیافته یعنی میگه redo entry رو بگیر و با logminer بیا این redoها رو به sql statment تبدیل کن و روی سایت standby اعمال کن دقیقاً مثل کسی میمونه که دوباره داره sql statementهای شما رو توی دیتابیس دیگهای به همون شکل میزنه این راهکار streaming اوراکل هستش که میاد دستورات رو apply میکنه
توی این حالت نیازی نیست تمام دیتابیس sync باشه شما میتونید فقط چند schema رو sync نگه دارید و یا schemaهای مختلف در سمت standby داشته باشید و schemaها رو map کنید
یکی از کاربردها اینه که میتونیم فقط یک schema مثلا دولوپ رو sync نگه داریم
یکی دیگه از کاربردهای logical standby اینه که شما schemaهای اپلیکیشنتون رو میارید و sync نگه میدارید اما نسخه دیتابیس سایت standby آپگرید شده باشه و اینجوری migration رو انجام بدید
یکی دیگه از نیازهایی که میتونیم با گلدن گیت اون رو برطرف کنیم این هستش که مثلاً مدیر شما ازتون هرماه ریپورت ماهانه میخواد و شما تو اوج کاری هستید و اگه بخواین ریپورتها رو ایجاد بکنید باعث بالا رفتن مصرف CPU میشید چون قراره کلی دیتا رو با همدیگه محاسبه و تفکیک بندی کنید.
یا مثلاً اصلا ماهیت structure data جواب این ریپورتها رو نمیده و ما باید از دیزاین OLAP استفاده کنیم تا trends reportهای سریعتری بگیریم البته میتونیم با تریگر تو مدت کار اپلیکیشن یک schem dwh مجازی در دل OLTPامون ایجاد کنیم (VDWH)
لزوماً DWH ما نباید جدا باشه و ماهیت DWH برمیگرده به OLAP ساختار یعنی ما ساختاری بچینیم که برای select مناسب باشه، ایندکسها مناسب select باشه(index هرچقدر برای select خوبه موقع update, insert, delete عملکردش رو از بین میبره و سرعتتون رو کند میکنه - چون عملاً وقتی یک جدول آپدیت میشه باید جدول ایندکسها هم دادههاش آپدیت بشوند) پس ساختار OLAP به صورت Denormalization هستش
ما وقتی سرور OLAP رو جدا میکنیم که ببینیم ریپورتهای ما مصرف بالایی از CPU و RAM سروردارن و به خاطر این مصرف بالا اپلیکیشن OLTP ما به مشکل کندی بر خورده خب اگه فقط کندی ما تو سطح منابع CPU, RAM, Disk باشه با راهاندازی اکتیو دیتاگارد ما سرور امون رو جدا میکنیم و ریپورتهامون رو روی standby میندازیم و از نظر سرور از OLTP جدا میشیم ولی مسئله اینه که باز ساختار این ۲ دیتابیس کاملاً یکی هستش(در سناریوی physical) و اگه ما ایندکسی روی سرور standby نیاز داشته باشیم برای ریپوتمون باید در primary امون این ایندکس رو ایجاد کنیم پس در کل دست ما برای ایجاد تغییرات در دیتابیس standby بسته است چون همه تغییرات از سمت primary خونده و اعمال میشه
حالا اگه ما از سناریوی logical استفاده کنیم میتونیم تغییرات دلخواهمون رو روی سرور standby بدیم چون میتونیم توی حالت read/writr دیتابیس رو بالا بیاریم
یه ابزار دیگه هم که تو این ضمینه خیلی دست ما رو باز میذاره، سرعت فوقالعادهای داره و بهمون کمک میکنه اوراکل گلدن گیت هستش ما میتونیم یه سرور دیگه با یه structure data دیگه آماده کنیم ریپلیکیشن یکطرفه راهاندازی کنیم و روی این دیتابیس به طور کامل کنترل داشته باشیم تا ساختار اون رو به شکل OLAP در بیاریم

بازیابی حادثه و محافظت از داده
فکر کنید اتفاقی افتاده و دیتاسنتر استان تهران به مدت یک هفته قطع شده خب فکر کنید وزارت کشور که فقط به استان تهران نباید سرویس بده باید به کل کشور سرویس بده حالا تهران برقش قطع شده ولی اصفهان باید سرویس بگیره تو این مواقع به عنوان یک DBA تو دیتاسنتر و زیرساختمون باید به فکر disaster recovery site باشم که از نظر محل فیزیکی با سایت اصلی دیتاسنترش مجزاست . خب پس هر وقت سایت تهران از دسترس خارج شد ما از سایت اصفهان یا کرمان سرویسدهی رو انجام میدیم.
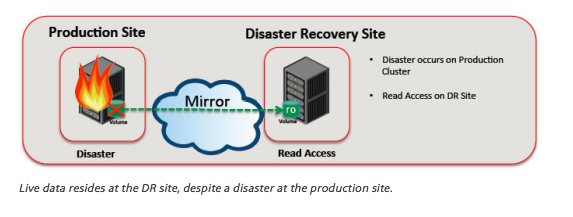
سایتهای DR به ۳ دسته تقسیم میشوند:
- HOT = یعنی به صورت آنلاین و لحظهای سایتها با هم SYNC هستند (دیتاگارد، گلدن گیت و ...)
- COLD = یعنی توی یکسری بازههای مشخص(مثلا هرماه) ما بکآپ گیریهای لازم(از دیتابیس و فایلهای فیزیکی) رو به صورت دستی و مطمئن انجام میدیم و میبریم روی سایتهای DR اعمال کنیم
- WARM = زمان انتقال دیتای COLD رو کمتر میکنیم و معمولاً به صورت ریموت بکآپها رو منتقل و ریستور میکنیم
برای استارتژی HOT ما نیاز داریم دیتابیسها رو لحظهای باهم SYNC نگه داریم یکی از بهترین راهحلهای اوراکل اینجا اوراکل دیتاگارد هستش اما اگه بنا به دلایلی (مثلاً بیزنس بانکی که شبها بچها کار میکنند و سندها جا به جا میشوند ما کلی دیتای TEMP از جنس Uncomited ایجاد میشه که در نهایت میخواد یک فیلد رو آپدیت کنه) خب اینجا اگه ما گارد physical داشته باشیم همیشه دیتابیسها باهم SYNC هستند پس باعث میشه TEMPهای من در standby هم ساخته بشه و کلی network, cpu, ram, disk مصرف شده و در نهایت این داده TEMP میخواد پاک بشه پس از standby هم پاک میشه
اینجا پیشنهاد من اینه که ریپلیکیشن یکطرفه با گلدن گیت راهاندازی بشه و هیچکدوم از این مشکلات رو به خاطر معماریاش ایجاد نمیکنه در گلدن گیت میشه فقط نتیجه به سمت دیتابیس مقصد بره تا اینهمه پهنای باند و محاسبه دوباره در DR ما اتفاق نیوفته
پس برای DR Site گلدن گیت یکی از راهحلهای بسیار خوب ما میتونه باشه
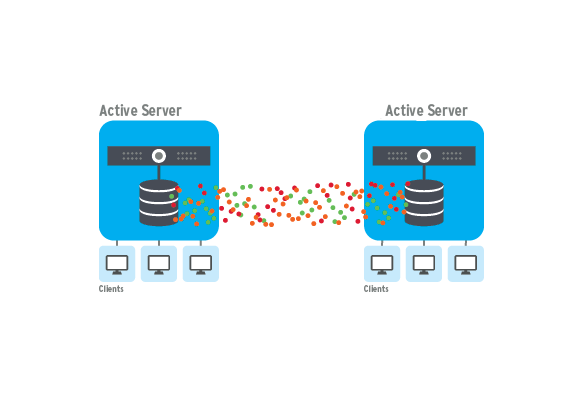
همسانسازی پایگاهداده دو طرف فعال (Active-to-Active)
یکی دیگه از نیازهای دیگهای که گلدن گیت برای ما رفع میکنه ریپلیکیشن ۱ طرفه و ۲ طرف فعال هستش
گلدن گیت به طور کامل HandleCollisions رو انجام میده، یادمون باشه مکانیزم lock در دیتابیس باعث میشه همیشه دیتابیسconsistent باشه و تا وضعیت ولید بودن دیتا بهم نخوره ولی تو این لایه چون چندتا دیتابیس جلوی هم قرار میگیرن باید به صورت Master/Slave بیاد و برخورد کنه
وضعیت Master/Slave رو ما خودمون میتونیم انجام بدیم مثلاً به صورت فیزیکی بیایم بگیم یکی Master ه و یکی Slave و اگه یه اتفاق همزمان تو ۲ دیتابیس باهم رخداد اولویت با Master باشه یا به صورت زمانی مشخص کنیم مثلا اونی که سریعتر رخداد
با اکتیو اکتیو بودن دیتابیسها ما میتونیم در دسترسپذیری مداوم دیتابیسمون رو بین مناطق جغرافیایی مختلف تضمین کنیم
مثلاًدر یک اتوماسیون اداری ما ۴۰۰ تا کاربر در ستاد تهران ۷۰۰ تا کاربر در عسلویه و ۳۰۰ تا کاربر در اصفهان داریم نوع اپلیکیشن هم کلاینت/سروری هستش خب ما بگیم دیتابیسمون تهران باشه و باقی کلاینتها از طریق شبکه به تهران وصل بشن و دیتا رو بخونن با فرض اینکه یه پنهای باند قوی mpls ای هم داریم پیادهسازی میکنیم بعد از پیادهسازی میبینیم کاربرها خیلی کند هستن اونم به دلیل ماهیت درایور این اپلکیشنهاست که میگن یه پکیج باید به طور کامل بیاد بعد پکیج بعدی رو بفرسته و حتی اگه ما بهترین پهنای باند رو هم داشته باشیم زمان اتلافی بالایی برای ریدن پکیجها داریم
خب پس بیایم یک دیتابیس برای هر سازمان بذاریم تا به صورت لوکال همه بتونن از اپلیکیشن استفاده کنن
چون هر جایی که اپلیکیشن و دیتابیس تو یه شبکه باشن و بهم نزدیک باشن کاربرها خیلی سرعت خوبی دارند و جایی که اپلیکیشن و دیتابیس نزدیک هم نباشن و کاربرها بخوان ریموتی کار کنن کندی رو مشاهده میکنن
حالا عمق فاجعه اینجا میشه که بستر ارتباطی ما به هر دلیلی مشکل دار بشه و قطعی ایجاد بشه تو این حالت تمام کاربرهایی که به صورت ریموتی با دیتابیس کار میکردند حتی دیگه تو اداره خودشون هم نمیتونن نامهنگاری کنن
بهترین راهکار برای این مواقع راهاندازی ۲ دیتابیس هستش یکی مثلا تهران یکی تو مرکز هر استان و اینها رو باهم ریپلیکیشن اکتیو اکتیو کنیم اینجوری هرکی تو هر استانی هست با دیتابیس خودش در سازمان استان خودشون کار میکنن و تا موقعی که شبکه برقرار باشه همه نامههای هم رو میبینند و میتونن باهم نامه نگاری کنن
فرضاً هم اگه شبکه قطع بشه ارتباط هر استان با استانهای دیگه قطع شده و میتونن تو استان و سازمان خودشون همچنان نامهنگاری داشته باشن یا اگه نیاز به ریپورت گیری از دیتای قدیمی باشه میتونن اینکار رو انجام بدن
گلدن گیت یه خوبی دیگه هم داره اونم اینکه بعد از اینکه این دیتابیسها از مدار رینگشون خارج شدند مثلا به خاطر مشکل شبکهای دوباره بعد از برقراری شبکه بدون راهاندازی مجدد میتونه دیتابیسها رو به حالت سینک باهمدیگه برسونه
گزارشدهی عملکردی و انبارش داده لحظهای
یکی از عملکردهای دیگه که میتونیم با گلدن گیت بهش برسیم realtime dwh هستش گفتم که میتونیم به صورت آنلاین تغییرات رو کپچر بکنیم و فقط change ها رو به سمت انبارهداده ببریم و انبارهداده رو به صورت لحظهای بدون نیاز به ETL شبانه و BATCH بروزرسانی بکنیم اینجوری تغییرات به صورت لحظهای در STAGE IO هستش و اونجا دیگه میتونیم تصمیم بگیریم مثلاً با نوشتن یک تریگر CUBE ما بروزرسانی بشه
حجم: 245 کیلوبایت
توضیحات: Best Practices for Real-Time Data Warehousing
توزیع داده برای سیستمهای OLTP
توزیع داده یکی از کارهای اصلی گلدن گیت هستش
مثلا ما توی وزارت بهداشت کلی دیتا به صورت تجمیعی داریم و میخوایم اطلاعات مراکز سلامت استانهای مختلف رو بهشون به صورت تفکیک شده بدیم خیلی راحت میتونیم این توزیع دیتا رو با گلدن گیت انجام بدیم یا اصلاًبرعکس این موضوع ما میخوایم اطلاعات تمام مراکز سلامت رو در دیتابیس وزارت بهداشت تجمیع کنیم تا ریپورتهای تجمیعی بگیریم خب ما میتونیم از گلدن گیت برای این موضوع استفاده کنیم تا به صورت آنلاین اینکار رو انجام بدیم