معماری اوراکل
خیلی مهمه برای درک معماری گلدن گیت معماری اوراکل رو خوب بلد باشیم، برای مطالعه معماری اوراکل 11g میتونید از لینکهای زیر استفاده کنید
نگاهی بر معماری Oracle Database 11g - قسمت اول
نگاهی بر معماری Oracle Database 11g - قسمت دوم
نگاهی بر معماری Oracle Database 11g - قسمت سوم
مهمترین بخش معماری که باید برای گلدنگیت خوب بلد باشید شکل زیر هستش:
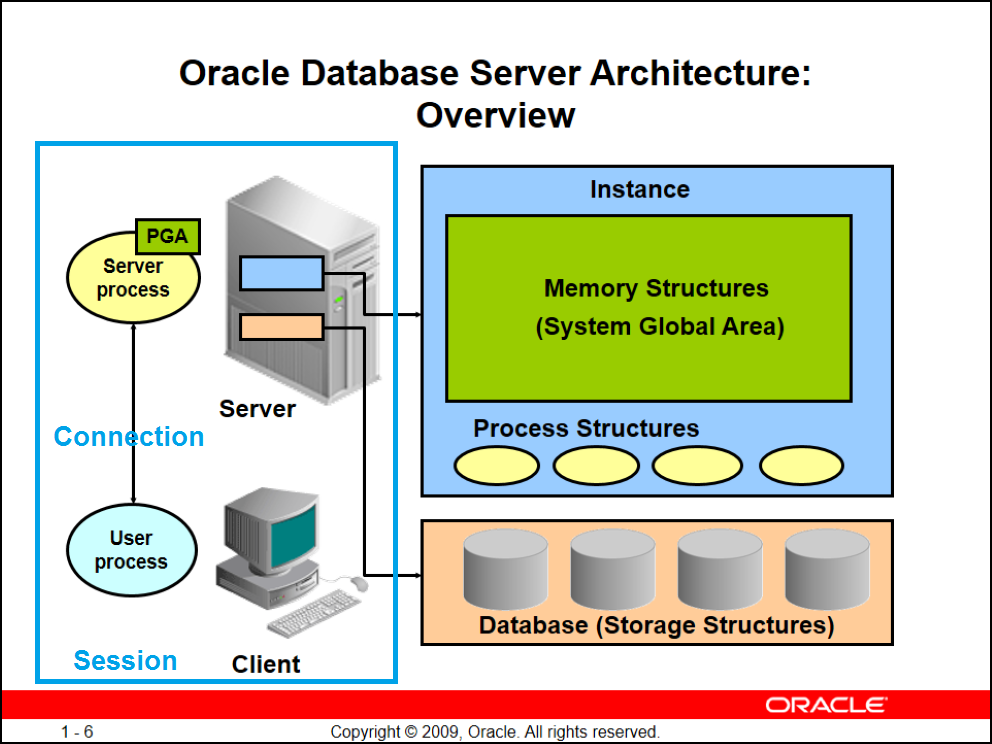
خب میخوام معماری اوراکل رو به صورت سناریو بیس و خلاصه دوباره دوباره تکرار کنم چون مسلط بودن به این معماری از ضروریات کاره
معماری اوراکل از اونجایی شروع میشه که شما پشت سیستماتون نشستید و میخواین به هر طریقی به دیتابیستون وصل بشید بعد از برقراری اتصال شما با نوشتن دستورات SELECT انتظار پاسخ از دیتابیس رو دارید حالا چه اتفاقی میافته؟ اول سمت شما که کاربر هستید یک پکیجی آماده میشه که تمام درخواستهای شما داخل این پکیج قرار میگیره این پکیج توسط پراسسی که ما بهش user process میگیم داره هدایت میشه حالا این پکیج قراره روی بستر شبکه هدایت بشه پس باید دیتابیس رو توی شبکه پیدا بکنه و درخواست رو بهش بده تا اتصال برقرار بشه الان کامپوننتهای Network اوراکل هم درگیر بازی ما میشن یه بخشی از این کامپوننتهای Networkای مثل لایههای شبکه TCP میمونن اونجایی که درخواست شما توسط user procees خونده میشه اولین کار باز کردن header پکیج هستش که داخلش ip, port, sid دیتابیسی که میخواد بهش وصل بشه هستش بعد از اینکه user process آیپی پکیج رو فهمید میره تو شبکه دنبال این ip و port میگرده تا مقصدش رو پیدا کنه
user process وقتی میتونه بفهمه مقصد رو پیدا کرده که با مشخصات همین header پکیج شبکه ما listener دیتابیس رو پیدا کرده باشه حالا پشت این listener یکسری process وجود داره(server process) که کارشون اینه که درخواستها رو از user process بگیرن و نتیجه درخواستها رو به user process از طریق listener تحویل بدن تو حالت dedicate هر server process فقط به یک user process سرویس میده و تا کار user process رو به انتها نرسونه به user process دیگهای سرویس نمیده
خب حالا این سناریو رو فرض کنید دیتابیس بالاست اپلیکیشن هم به دیتابیس وصل هستش و session ما برقراره حالا listener ما به هر دلیلی پایین میوفته(stop) تو این حالت چون session برقرار شده و اتصال بین server process و user process ما انجام شده، مدیریت این session یا با کاربر هستش یا با دیتابیس و listener هیچ نقشی تو این مدیریت نداره ولی اگه کسی بیاد درخواست جدیدی رو سمت دیتابیس بفرسته چون listener ای وجود نداره اتصال برقرار نمیشه و session جدیدی رو نمیشه ایجاد کرد
نکته: پشت listener یک یا چند process میتونه وجود داشته باشه
وقتی user procees بتونه listener رو پیدا کنه و server process بهش اختصاص پیدا کنه ایجاد مفهوم Connection در اوراکل میشه
حالا این connection باید یکسری ویژگیهایی بگیره و بیاد یک لول جلوتر و در نهایت به یک Session تبدیل بشه
زمانی Connection به Session تبدیل میشه که server process از instance ما یک مقدار RAM بگیره و متادیتای user process رو تو این قسمت قرار بده تا بدونه موقعی که میخواد پاسخ درخواست user رو بهش بده باید به کدوم user process مراجعه کنه همچنین زمانی که بتونه authentication روی user انجام بده connection ما تبدیل به session میشه
پس فهمیدیم تو مرحله تبدیل connection به session هستش که پسورد کاربر ما چک میشه
مثال:
شما دارید به دیتابیس وصل میشوید و پیغام خطای ORA-12541: TNS:no listener رو میبینید خب الان یعنی user process شما اصلاً نتونسته connection برقرار بکنه و ما باید به بررسی کامپوننتهای Networkای اوراکل بپردازیم مثلاً یا داریم ip رو اشتباه میدیم یا listener ما تو مدار نیست یا شبکه ما مشکل داره و ...
حالا فرض کنید به ما پیغام ORA-01017: invalid username/password; logon denied یا ORA-01031: insufficient privileges رو نمایش داده این یعنی connection ما درسته و نیازی نیست بیخودی ما TNS رو دست بزنیم یا با کامپوننتهای Network ای سر و کله بزنیم ای مشکل یه چیزی سمت سروره یا server process نتونسته RAM بگیره(PGA) یا واقعاً نامکاربری و پسورد ما مشکل داشته یا نتونستیم متادیتا رو منتقل بکنیم درکل این حالت یعنی ما نتونستیم از connection به session تبدیل بشیم
خب اولین چیزی که بعد از ایجاد session در PGA قرار میگیره متادیتای user process هستش
یک تصویر ذهنی از یک فروشگاه داشته باشید که شما به عنوان مشتری فقط میتونید تا دم درب فروشگاه برید و به محض رسیدن به درب فروشگاه یکی از کارمندان فروشگاه میاد و از شما لیست خریدهاتون رو میگیره حالا این کاربر همون لحظه دنبال یک سبد میگرده و اگه بتونه سبد خالی از فروشگاه بگیره مشخصات شما رو درون این سبد میندازه تا موقع برگشت بتونه پیداتون کنه
اوراکل کلاً معماریش به این شکله که میاد میگه سرور تخصیص یافته برای من شامل ۲ قسمت میشه یه بخشی رو بهش میگه instance که مثل یک پلی میمونه که شما رو واقعاً میتونه به دیتای فیزیکیتون برسونه این دیتای فیزیکی شما در اصل در بخش storage structures قرار داره (دیتافایلهای شما) در شکل بالا اگه دقت کنید اوراکل به این بخش Database میگه ولی منظورش مفهوم عامیانه دیتابیس نیست اینجا اوراکل به معنی لغتی دیتابیس اشاره داره یعنی جایی که واقعاً data قرار داره
-cpu + ram = instance
-storage media = database
حالا تمام این server processهایی که سبدهاشون رو از دم درب گرفتن وارد سالن اصلی فروشگاه میشن در اینجا همهچی قفسهبندی شده است پس server process تو این فضای مشترک میگرده تا نیازهای user processاش رو تامین بکنه
حالا چرا این فضا مشترکه چون باید یکسری کارها مشترک انجام بشه مثلاً فرض کنید یک server processای اومده و میبینه دیتایی که نیاز داره تو قفسهها نیست همونجا درخواستش رو بلند به مسئولش میگه اینجا اگه server process دیگهای بیاد و اونم درخواست همون دیتا رو داشته باشه دیگه درخواست دیتا رو ثبت نمیکنه چون میبینه که قبلاً یکی این درخواست رو ثبت کرده پس ما به یک فضای مشترک برای یکسری کارها احتیاج داریم(SGA)
حالا یه ذره ریزتر بشیم server process ما وقتی میخواد وارد سالن اصلی(SGA) فروشگاه بشه باید از یکسری غرفهها(checking) بگذره مثلاً یکی از چکها اینه که لیست درخواستهای داخل PGA بازنگری بشه که کاربر نهایی(مشخصاتش داخل PGA بود) دسترسیهای لازم برای این لیست رو داره یا نه؟ پس تو بافر اول privilege ها رو چک میکنه. توی SGA ما ۶ تا بافر داریم که ۳ تای اونها اجباری هستش یعنی تو همهی SGA ها باید باشه
اولین بافر که checkingها در اون انجام میشه shared pool هستش به صورت کلی از نظر syntax، semantic و privilegeای دستورات چک میشوند و اگه نیاز باشه ما میتونیم یکسری نتایج رو داخلش نگهداری کنیم.
وقتی چکهای shared pool تموم میشه server process ما وارد بافر بعدی یا همون database buffer cache میشه(اوراکل به صورت بلاک بلاک این بافر رو تشکیل میده و دیتای خام شما از datafileها میاد و وارد این بافر میشه و به صورت بلاکی نگهداری میشه این به این مفهومه که وقتی شما از update استفاده میکنید یکبار دیتای شما از دیسک خونده میشه و وارد این بافر میشه و وقتی شما تغییرات رو روی رکوردهاتون میدید در حقیقت تغییرات رو روی این بافر انجام دادید و مستقیم با دیسک درگیر نشدهاید) این بافر شامل تمام غرفههایی که تو سطح سالن ما وجود داره و ما میتونیم دیتا رو از این غرفهها برداریم اگه دیتای ما تو این بافر بود که نتیجه رو وارد PGA میکنیم.
چرا اوراکل اصرار داره که به صورت buffer cache ای عمل کنه؟ همش به خاطر بالا بردن سرعت و performance انجام کارها هستش چون بزرگترین bottlenecks ما همیشه I/O هستش چون هر وقت سرور شما بره سراغ هارد ما دچار bottlenecks I/O میشیم پس اوراکل برای اینکه خودشون کمتر درگیر I/O کنه پس تا جایی که بتونه میاد از RAMاستفاده میکنه و مواقعی که نیاز باشه خودش تشخیص میده که کی باید RAM رو بر روی دیسک بنویسه اصطلاحاً میگن اوراکل دیتابیس deferrable هستش یعنی با تاخیر عملیاتها رو انجام میده ولی کاربر از این تاخیر کاملاً tranparent هستش
حالا اگه دیتای ما در این بافر نباشه server process درخواست کننده باید بره از انبار(datafile) دیتاها رو به صورت بلاکی بیاره بذاره در database buffer cachce پس چون داره به صورت بلاکی کار میکنه نمیتونه فیلترینگ داده رو تو این قسمت انجام بده بعد از اینکه داده رو از بافر کش برداشت تغییرات مورد نیاز user رو داخل PGA انجام میده و نتیجه رو ذخیره میکنه
بلاکها در database buffer cache در حقیقت ۳ حالتی هستند:
- dirty = یعنی ما یک بلاکی رو آوردیم داخل database buffer cache و اون رو آپدیت کردیم به مقدار جدید پس مقدار قبلی dirty هستش
- free = هیچ دیتایی داخل این بلاک نیستش
- pin = یعنی ما یک بلاک رو از دیسک آوردیم داخل database buffer cache و هنوز بهش احتیاج داریم و داریم باهاش کار میکنیم
اگه اوراکل برای آوردن دیتای جدید در database buffer cache فضا کم بیاره اول میره داخل بلاکهای free دیتای جدید رو مینویسه و اگه خیلی فضا کم بیاره شروع به خالی کردن بلاکهای dirty براساس LRU میکنه
خب تا الان باهمدیگه مرور کردیم که همه چی ما داخل RAM اتفاق میافته حالا فرض کنیم یکهو برق بره و یا سرور کرش کنه به نظرتون اوراکل چیکار میکنه؟ اوراکل برای اینکه با این موارد مقابله کنه یک بافر اجباری دیگه داخل SGA داره
به این صورت که هر تغییری که داخل database buffer cache اتفاق بیافته (مثل آپدیت) دستورات اون تغییر رو باید بذاره داخل این بافر این دستورات همون redo entry ها هستن اوراکل برای این موضوع که Zero Data Loss رو تضمین بکنه این بافر رو ایجاد کرده این بافر همون Redo log buffer هستش
حالا هر دیتای که وارد Redo log buffer بشه به صورت sequential write و به سرعت در دیسک نوشته میشوند فرق این کار با نوشتن مستقیم دیتا در دیتافایل اینه که موقع نوشتن دیتا در دیتافایل باید خیلی دقیق فضاهای خالی در دیسک پیدا بشوند و دیتاها به صورت بلاکی قرار بگیرن (در حقیقت random write باید انجام بشه) و عملاً کندی کار بیشتر هستش (اگه موقع write به صورت random write عمل نکنه کلی فضای بیهوده در دیسک ما ایجاد میشه)
نکته: فرق بین sequential write و random write
پس وقتی redo log buffer داره در دیسک خالی میشه به صورت sequential write عمل میشه و کافیه اولین آدرس برای نوشتن مشخص بشه تا بدون در نظر گرفتن پارامتری به سرعت دیتاها نوشته بشوند
در نهایت شما وقتی دستور commit رو در اوراکل میزنید changeهای شما به سرعت در دیسک نوشته شدهاند اما database buffer cache شما که دیتا رو به صورت بلاکی نگهداری کرده هنوز بلاک جدید رو به دیتافایل شما انتقال نداده تو این وضعیت درسته database buffer cache وارد دیتافایل شما نشده ولی به شما پیغام موفق بودن commit رو میده حالا فرض کنید همین لحظه سرور کرش میکنه یا برق کشور میره خب دیتابیس شما هم کرش میکنه و نکته اینجاست که وقتی هر زمانی بخواد دوباره بالا بیاد و ارتباط instance و database رو برقرار بکنه شروع به انجام عملیات crache recovery میکنه چون باید خودشون به اون نقطهی ثابت که آخرین commit رو به شما داده بود برسونه
حالا چجوری crache recovery رو انجام میده؟ به راحتی چون دیتای اولیه که روی دیسک و دیتافایلها بوده دستوری که باعث شده بود دیتاها تغییر بکنند رو هم روی دیسک بوده خب دوباره تمام این دستورات تغییرات اعمال میشه و به اون نقطه قبلی میرسه
پس اوراکل با این مکانیزم Zero Data Loss رو تضمین کرده
۳ تا بافر اختیاری دیگه هم داریم که براساس کامپوننتهایی که شما بر روی اوراکل راهاندازی میکنید میتونید اینها رو ایجاد بکنید و ازشون استفاده بکنید.
- Large pool = موقعی که شما معماری دیتابیس رو از dedicate به shared منتقل میکنید احتیاج به یکسری استخرها دارید که یکیش Response Queue هستش و یکیش Request Queue یعنی یه جا همه درخواستهاشون رو وارد میکنند و از یه جا همه درخواستهاش رو برمیدارن خب این فضاها در large pool ساخته میشه
- Streams pool = ما اگه از سولوشن streams اوراکل استفاده بکنیم از این فضا برای راهاندازی این سولوشن استفاده میشه
- Java pool = ما اگه از کدهای جاوا داخل اوراکل استفاده بکنیم و به نوعی JVM داخلی دیتابیس اوراکل رو درگیر بکنیم میتونیم از این فضا استفاده بکنیم
نکته: اگه این ۳ بافر اختیاری راهاندازی نشوند و ما کامپوننتی رو تعریف کرده باشیم ولی بافر مربوطه رو تخصیص نداده باشیم اوراکل خود فضایی رو از Shared pool به صورت پیشفرض اختصاص میده
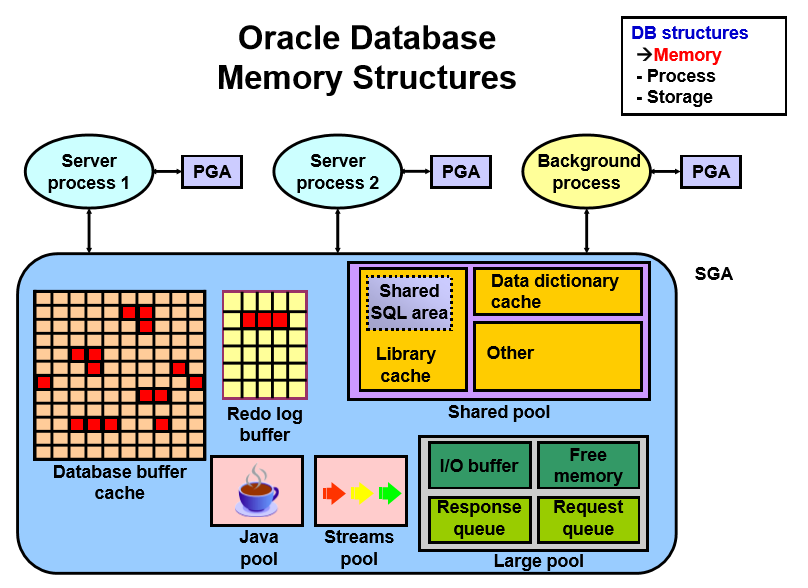
حالا سرور پراسس ما رفت دیتا روپ از database buffer cache ما خوند ولی درخواست کاربر گذاشتن order by روی دیتاها بود اوراکل میگه سرور پراسس ما حق نداره در shared pool یا فضای دیگهای بیاد اینکار رو انجام بده تنها فضایی که مجازه این عملیات رو در اون انجام بده فضای PGA یا همون سبد کاربر هستش و اگه برای انجام این کارها فضای کافی در PGA نداشته باشه باید از temporary tablespaceها استفاده بکنه و درکل حق نداره order by یا hash join رو در SGA انجام بده
موقعی هست که شما میبینید I/O سرور بالا رفته و همش هم به خاطر SELECTهای کاربرها هستش و UPDATE/INSERT/DELETE در سرور انجام نمیشه بعد از بررسیهای بسیار و سخت به این موضوع میرسید که کلی write دیتا در سرور دارید ولی هیچکدوم از statementها این عملیات write رو انجام ندادن و فقط ما SELECT داریم که توقع ما از SELECT اینه که READ داشته باشیم اینجاست که باید به فیلترهای SELECTهاتون توجه کنید مثلاً اگه یک ORDER BYای روی یک دیتای سنگین داشته باشید که روی PGA جا نشه اوراکل شروع به write داده در temp datafileها میکنه تا بتونه داده رو مرتب کنه و بعد از این temp داده رو به صورت مرتب شده read کنه اینجاست که باید PGA اتون رو افزایش بدید
شما حتی اگه به memory advisor اوراکل در OEM سری بزنید یه قسمتی به اسم heat ratio برای PGA داره (نسبت کارهایی که در PGA اتفاق میافته رو به صورت درصدی میده) اگه این عدد زیر ۹۰ باشه در OLTP به درد کار نیمخوره چون داره مقدار زیادی از کارهای PGA رو در tempها انجام میده
نکته: خیلیها این موضوع رو اشتباه برداشت میکنن که اوراکل به ازای هر کاربر یک PGA میسازه در اصل به این شکل نیست و اوراکل به ازای هر Session یک فضای PGA به اون Sessionاختصاص میده پس موقع تخصیص فضای PGA حواستون باشه اگه ۱۰ تا Session از ۱ کاربر دارید باید جوری عدد PGA رو TUNE کنید که مشکلی از نظر منابع ایجاد نشه
نکته: رابطهی process با session یک رابطهی ۱ به ۱ هستش و شما فقط امکان این رو دارید که مشخص کنید حداکثر چه تعداد process روی سرور ما ایجاد بشود به طور معمول ۵۰ تا پراسس برای کارهای خود دیتابیس اوراکل در نظر میگیریم و اگه روی سرورمون نیازه ۱۰۰ تا session باز بشه من کل پراسسهای این سرور رو روی ۱۸۰ تا تنظیم میکنم یادتون باشه این موضوع هم خطرناکه که تعداد processها رو عدد بالایی در نظر بگیریم چون اینجوری سرور ما به جایی میرسه که کلاً OS اون هنگ میکنه (چون هر کرنلی تا ایجاد یک تعداد process ای تنظیم شده)
نکته: یکی از نکاتی که در راهاندازی دیتاگارد معمولاً فراموش میشه راهاندازی OEM هستش اگه ما روی سرور گارد OEM راهاندازی کنیم خود این سرور کلی process ایجاد میکنه و باعث میشه پراسسهای ما بالا بره
نکته: دیتابیس از idle شدن session شما خبردا نمیشه تا وقتی که اپلیکیشن شما session رو از بین ببره یا براساس تنظیمی که بر روی پروفایل کاربر در دیتابیس شده sessionهای idle از بین بروند
یکی از مواردی که بهش برخوردم این بود که ما یک اپلیکیشنی داشتیم که روی وبلاجیک بود و دوستان اپلیکیشن ورژن رو ارتقا دادن و بعد همش دیتابیس ما پایین میومد یکی از موارد پیشنهادی بچههای اپلیکیشن این بود که سرور منابع کم میاره و باید بره روی معماری shared (یکی از حالتهایی که ما از dedicate به shared میریم کمبود منابع هستش چون ما دیگه نمیایم به ازای هرکس یک server process اختصاص بدیم و با مثلا ۲۰ تا shared server ما کار ۱۰۰ تا server process رو به صورت رندومی انجام میدیم) چون دیتابیس ما داشته کار میکرده من گفتم که نیازی نیست به معماری shared بریم یکی از دلایلیش اینکه ما تعداد کاربرهامون زیاد نشده بود و با همون تعداد کاربر فقط نسخه اپلیکیشن ارتقا یافته بود من این تضمین رو دادم که وبلاجیک TUNE نیست و بعد از TUNE کردن وبلاجیک و بستن processهای idle بعد از اتمام کارشون مشکل حل شد.
Process Structure
انواع پراسسهای اوراکل
- user process: سمت کاربر هست
- server process: سمت سرور
اپلیکیشنهایی که بر روی دیتابیس process ایجاد میکنن مثل application server weblogic خودش یک process بر روی دیتابیس ایجاد میکنه
همچنین ما ۲ نوع server process داریم:
- foreground process = که همون server processای هستش که PGA رو تشکیل میده و به استقبال user process میره
- background process = که server processهایی هستن که ارتباط RAM رو با DISK برقرار میکنن
۵ تا bg اجباری در اوراکل شامل:
1- Lgwr = که redo entryهایی که در بافر redo log buffer هستند رو در online redo logها مینویسه، online redo logهای ما حداقل باید ۲ تا گروه باشند و هر گروه هم حداقل یک عضو داشته باشه (به این علت میگه ۲ تا گروه چون به صورت sycle ای مینویسه وقتی گروه ۱ پر میشه باید یک cycle بزنه اگه ببینه گروه دیگهای وجود نداره دوباره باید بیاد روی همون گروه بنویسه که چون این گروه هنوز خالی نشده باعث ایجاد وقفه میشه پس برای همین میگه حداقل باید ۲ تا گروه وجود داشته باشه که یه فرصتی برای خالی کردن گروه قبلی داشته باشه)
lgwr هر ۳ ثانیه یکبار و هر commit ای که اتفاق میافته و هر وقتی که ۱/۳ بافرش (redo log buffer) پر بشه و هر وقتی که dbwn بخواد کارش رو شروع بکنه عملیات flush رو به صورت sequential انجام میده (خالی کردن اطلاعات از RAM بر روی Disk)
این bg همهی دستورات رو چه به صورت commit شده و چه به صورت uncommit شده رو میاد روی دیسک قرار میده
2- DBWn = هرجا شما در هر bg ای یک n دیدید یعنی میتونید ازشون چندتا داشته باشید کار این bg اینه که بلاکهای database buffer cache رو روی دیتافایلها به صورت رندوم flush بکنه
زمانهایی که dbwn فراخوانی میشه: ۱- هر ۳ ثانیه یکبار ۲- موقعی که فضاهای dirty در database buffer cache زیاد شده باشند ۳- مواقعی که checkpoint رخ میدهد (این خودش یک bg به اسم CKPT هستش)
3- CKPT = ایجاد checkpointها و کنترلشون رو برعهده داره ما در اصل ۲ نوع checkpoint داریم: 1- partial -2 full or advance
partial رو کاربر نمیتونه بزنه و زمانهایی میخوره که مثلاً یکی از tablespaceهای شما آفلاین یا آنلاین بشه یا شما دیتافایلی رو پاک کردید و یکی جدید ساختید و یا یه اتفاق خاص روی یک tablespace بیوفته یک checkpint فطق روی همون tbs میخوره
advanceها یا fullها موقعی که شما دیتابیس رو shutdown میکنید (در حالتهای normal, transactional, immediate) یک checkpint full میخوره تا نقطه stable بودن دیتابیس ثبت بشه و دیگه نیازی به crache recovery نیستش
همچنین مکانیزم checkpoint در اوراکل با SCNها هستش(system change number) همونطور که میدونید ما یکسری فایلهای مهم در دیتابیس اوراکل به اسم control file داریم که محل فیزیکی تمام فایلهای روی دیسک رو بهمون نشون میده (مسیر pfile, spfile, datafile, online redo log fileها و ...) خب به ازای هر دیتافایل هم آخرین SCN ثابت و stable اش رو نگهداری میکنه یعنی اگه ما ۱۰ تا دیتافایل داشته باشیم ۱۰ تا رکورد در controlfile داریم و آخری وضعیت stable این scnها اینجا نگهداری میشه خب خود هر دیتافایل هم یک header ای داره که scn جاری دیتافایل اولش نوشته شده یعنی ممکنه scn داخل controlfile با scn داخل header دیتافایل ما بهم خوره پس موقع startup میاد این ۲ scn رو باهم چک میکنه و ریکاوری رو از روی online redo log fileها شروع میکنه حالا وقتی ما checkpoint میزنیم در حقیقت میخوایم این ۲ تا scn رو باهم یکی کنیم و آخرین scn دیتافایل رو ببریم بنویسیم داخل controlfile امون
حالا وقتی میخواد شروع به checkpoint زدن بکنه میاد به دیتافایل میگه آخرین scn ثابتت رو بده دیتافایل میاد میگه من دوست دارم آخرین scn ثابتم رو بهت بدم اما الان یکسری بلاک روی ram هستند که من از وضعیت اونها خبر ندارم اول یه کار کن که وضعیت اون بلاکها stable بشه و من ازشون خبردارد بشم بعد آخرین scn رو بهت میدم خب اینجا ckpt میره پیش dbwn و بهش میگه سلام خوبی؟ اونم میگه خوبم تو چطوری خخ خب حالا ckpt میگه عزیزم تو یسری بلاک روی database buffer cache داری نمخوای تکلیفشون رو مشخص کنی ما رو آواره کردی تو رو خدا اینها رو flush کن روی دیتافایل دیتافایل جوابم رو سربالا میده حالا dbwn که زورش زیاده میگه باشه خیالت راحت من کلی سعی میکنم این کار رو بکنم اما من یه داداشی دارم که خیلی احترامش برام واجبه هر وقت بخوام آب بخورم میرم بهش میگم lgwr کاری نداری اول اون کارهاش رو انجام بده بعد من آبم رو بخورم چون اگه وسط کار workerهای من کرش بکنن اوارکل اگه lgwr کارش رو نکرده باشه نمیتونه crache recovery کنه پس اول dbwn میره به lgwr میگه که flush اش رو انجام بده و بهش خبر بده بعد از اینکه فلاش lgwr تموم میشه dbwn هم بلاکهاش رو هم داخل data fileها فلاش میکنه و تو رو خبر میکنیم که بری از دیتافایل scn ثابتش رو بگیری و ببری بذاری داخل controlfile این عملیات که بدون مشکل انجام بشه یه advance checkpoint یا full checkpoint اتفاق افتاده
خب این ۳ bg از ۵ تا bg اجباری ما هر ۳تاشون به صورت single task هستن یعنی یک کار فقط انجام میدن
4- SMON = یا Server Monitoring این bg عزیز ما به صورت multi task کار میکنه یکی از کارهاش اینه که فکر کنید کلی server process اومدن و کارها رو انجام دادن و کلی temp segment ایجاد کردن وظیفه برگردوندن این temp ها به عهده server processها نیست چون باید سریع برن به باقی user processها سرویس بدن اینجاست smon عزیز میاد وظیفهی برگردوندن temp segmentها رو داره تا منابع آزاد بشه یکی دیگه از کارهای این عزیز اینه که وقتی دیتابیس شما shutdown abort میشه یا برق قطع میشه یا سرور کرش میکنه و دیتابیس دوباره میخواد بالا بیاد اولین کاری که میکنه اینه که scn ها رو از ctlها با دیتافایلها چک کنه پس smon میفهمه که سرور کرش کرده پس حالا باید عملیات crache recovery انجام بشه مسئول این عملیات recovery با smon هستش
5- PMON = یا همون process monitoring این bg هم به صورت multi task هستش یک پراسس وقتی اجرا میشه کلی lockبر روی آبجکتهای مختلف ایجاد میکنه وقتی کاری server process تموم میشه دست به این lockها نمیزنه اینجاست وظیفه PMON نمایان میشه که به سرعت این lockها رو از حالت lock دربیاره یکی دیگه از کارهای PMON یانه که وقتی سرور بالا میاد به listener بگه که instance بالا اومده و حالا میتونی بهش سرویس بدی
درکل listener به ۲ حالت میفهمه که داره به یک instance سرویس میده یا نه:
- ما به صورت استاتیک register کرده باشیم که listener همیشه به فلان instance سرویس بده (حالا میخواد instance ما بالا باشه یا پایین)
- به صورت داینامیک register کنیم که اینکار وظیفه PMON هستش به محض بالا اومدن instance بره registerای رو انجام بده
Database - Storage Structures
خب ما توی دیسک یکسری فایل داریم که به صورت فیزیکی هستند:
- controlfile = فایل خیلی مهمی که وظیفهی ارتباط بین instance و storage رو برقرار میکنه، وقتی instance ما از mount میخواد به open بره از روی controlfileها میفهمه که فایلهای فیزیکی کجا قرار دارند و اندازه هر کدوم چقدره و چه scnهایی براشون خورده
- parameter file = وقتی دیتابیس بالا میاد اول از همه میره instance رو تشکیل میده یعنی به os میگیم که ما به این اندازه cpu, ram نیاز داریم اوراکل از روی این پارامتر فایلها اندازه cpu, ram اختصاص یافته بهش رو میفهمه مثلا میگه من یه SGA بیست گیگی میخوام و یه PGA پنج گیگی و میخوام اینها رو بدم به یه db unique name ای به فلان اسم
این فایل ۲ نوع داره: pfile و spfile که pfileها به صورت text هستن و شما میتونید editاش کنید ولی spfile یا server parameter fileها به صورت باینری هستن و ترتیبش هم اینجوریه که وقتی instance ما میخواد بالا بیاد اول میره سراغ spfile و اگه گیرش نیاره میره سراغ pfile
- datafileها = محل فیزیکی دیتای جداول در این فایلها قرار دارند شما وقتی یک جدولی دارید و رکوردهایی داخل اون هستش فضای واقعی که در اونها این دیتاها قرار دارند این فایلها هستند
- online redo log fileها = این فایلها به صورت گروهی هستند که lgwr میاد redo entry ها رو اینجا مینویسه
- backup file
- trace file = هر bg ای که کار میکنه یکسریلاگ از عملکرد خودش میذاره خب این لاگها در trace فایل خاص منظوره خودش قرار میگیره
- alert log file = لاگهای کلی دیتابیس در این فایلها قرار میگیره در این فایلها برخی مواقع اشارههایی به فایلهای trace انجام میشه برای همین ما کلی trace file داریم و یک فایل alert log
- password file = پسورد کاربرهایی که role های sysdba و sysoper رو دارند داخل این فایل قرار میگیرند چون این کاربرها موقعی که instance هم پایین باشه میتونن عملیاتهایی رو انجام بدهند پس نیاز به اعتبارسنجی دارند که با این فایل انجام میشه به علاوه لیست کاربرهای osای که به صورت os auth تعریف شدهاند(هر کاربر سیستمعاملی که عضو گروه os ای dba باشه و در صورتی که os auth دیتابی فعال باشه(غیرفعال کردن این حالت با تنظیم فایل sqlnet و قرار دادن مقدار all یا nts به صورت دستی))
نکته: وقتی bgهای اجباری شما نتونن کارهاشون رو انجام بدن مثلا lgwr نتونه فلاش کنه instance شما shutdown میشه حالا شما به عنوان dba باید اولین کاری که انجام بدید این باشه که alert log رو باز کنید حالا بازش کردید میبینید که خط آخر گفته shutdown abort به این دلیل که lgwr نتونسته در دیسک عملیات write اش رو انجام بده حالا تو خط بعد آدرس یه traceفیال رو داده که میگه لاگ این bg اینجاست بعد شما میرید و این trace فایل رو باز میکنید و میفهمید lgwr دیسکهای online redo log fileها رو نتونسته ببینه و به همین دلیلی نتونسته عملیات رو انجام بده
structure datafile
معماری که در دیتافایل هستش از نظر اوراکل ۲ لایه هستش: ۱- معماری منطقی ۲- معماری فیزیکی
یادمون باشه instance اوراکل به طور مستقیم با فایلهای داخل دیسک درگیر نمیشه و تنها چیزی که instance میشناسه tablespaceها هستند
در حقیقت tablespaceها هستند که دیتافایلها رو در دیسک میشناسند، تو هر tbs میشه یک یا چند دیتافایل قرار داد و یک دیتافایل نمیتونه بین چند tbs مشترک باشه (یک datafile حتماً به یک tablespace تعلق داره)
در معماری فیزیکی اوراکل کارها رو به چند لایه تقسیم کرده:
- سگمنت = در هر tbs یک یا چند سگمنت وجود داره اما هر سگمنت که میگیم یعنی چی؟ به هر چیزی در instance ما یک آبجکت میگیم مثلا فانکشن، پکیج، پراسیجر، جدول، ایندکس و ... یک آبجکت هستن هر آبجکتی که دیتا داخل دیتافایل بخواد ذخیره کنه باید دیتا رو تبدیل به سگمنت بکنه (مثلا view دیتایی ذخیره نمیکنه پس سگمنتی تولید نمیکنه) پس یک سگمنت متناظر با یک جدول هستش
- extend = هر سگمنت تشکیل شده از چند extend هستش تا کارهای ذخیرهسازی راحتتر و سریعتر انجام بشه مثلاً یک سگمنت یک inital extend, next extend, other extend داره
- oracle block = هر extend از oracle blockهای پشت سرهم تشکیل شده وقتی میگیم پشت سرهم یعنی یک extend ما حتماً روی یک دیتافایل قرار میگیره چون اجزای تشکیل دهندهاش پشت سرهم هستن پس حتما باید داخل یک دیتافایل باشند
نکته: یک جدول میتونه بین چند دیتافایل توزیع بشه چون یک segment تشکیل شده از چند extend هستش و این extendها میتونن از دیتافایلهای مختلف oracle blockهاشون رو گرفته باشن
همهی این مرورها رو کردم که بگم این redo entryها (چه در redo log buffer یا online redo log fileها) هستن که تو GoldenGate اهمیت بالایی دارند و GoldenGate با اینها کار میکنه در حقیقت با استفاده از redo entryهای موجود در online redo log file میاد capture اش رو انجام میده
 شماره بر خلاف سن کم بسیار با تجربه هستی و با دانش هستی مهندس عزیز.مطالب وبلاگت عالیه9
شماره بر خلاف سن کم بسیار با تجربه هستی و با دانش هستی مهندس عزیز.مطالب وبلاگت عالیه9