در مطالب پیش گفتیم که در بحث Active Data Guard ما ۲ حالت Sync و Async برای سرویس Apply داریم.
حالا میخوایم ببینیم که ما Protection Mode مون رو یا حالت محافظت از دیتامون رو تو چند حالت میتونیم قرار بدیم؟
در این حالت شما براتون کارایی و Performance بیشتر براتون اهمیت داره حالا ممکنه براتون سوال پیش بیاد که Performance دقیقاً چه ارتباطی با Active Data Guard داره؟
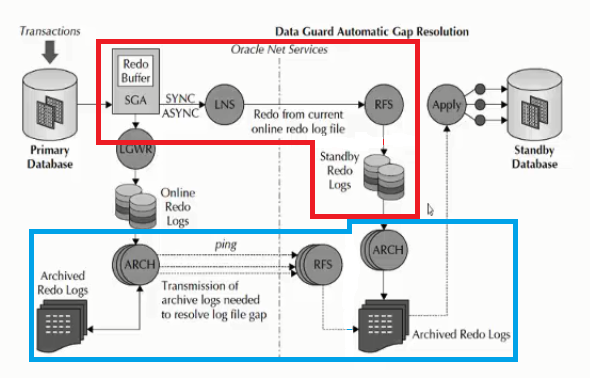
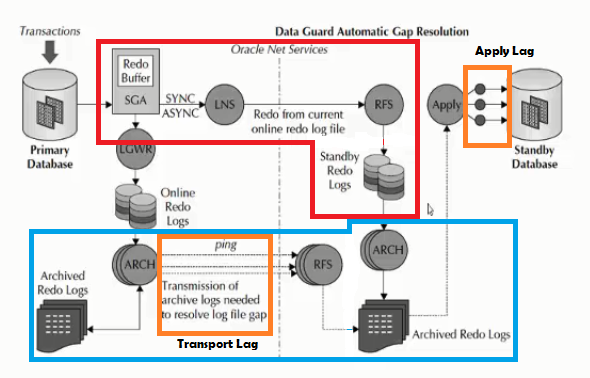
در حقیقت ارتباطش تو قسمتی معنی پیدا میکنه که شما منتظر apply بودید یعنی تا زمانی که اطلاعات روی سرور standby به صورت apply شده نبود این تغییرات بر روی سرور اصلی commit نمیشد.
نکته: همین حالت ممکنه تو حجم Transaction های بالا باعث کندی بشه
خب اگه ما بخوایم این موضوع در نظر بگیریم که نخوایم سرور primaryمون بدون commit باشه تو این حالت apply service امون رو Async در نظر میگیریم و تو Maximum Performance میگیم که دیگه لازم نیست منتظر apply بمونی شما دیتا رو commit کنن و هر زمانی که RFS تغییرات رو دریافت کرد و روی standby log file ها نوشت بعد دیتا رو sync کن
پس تو این وضعیت برای ما فقط Performance اهمیت داره
این موضوع برعکس موضوع Maximum Performance هستش در این حالت برای ما دیتا اهمیت داره یعنی ما نمیخوایم هیچ دیتایی از دست بره خب تو مطالب قبل راجع به sync و async به اندازه کافی گفتیم. در حقیقت تو قسمتی که sync بود گفتیم که تا زمانی که apply service روی سرور standby تغییرات رو apply نکرده تغییرات در سرور اصلی commit نمیشود یعنی acknowledge که برای commit میره اونور منتظر apply میمونه.
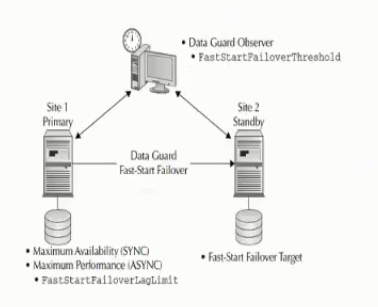
خب ما توی پیکربندی protection mode یه حالتی هستش که وضعیت protectionمون یا از دست ندادن دیتامون برامون اهمیت داره که تو این حالت حتماً باید apply serviceمون تو وضعیت sync باشه
خب توی این حالت یه پارامتری داریم به اسم Timeout که اینو در نظر میگیره که شما یک مقدار زمانی رو صبر کن اگر دیدید سرور standbyتون نتونسته apply کنه سرور primary رو بیا shutdown کن
پس به علت اینکه ممکنه تغییرات روی سرور standby انجام نشه و شما دیتا رو از دست بدید به همین دلیله که یک مدت کوتاهی رو صبر میکنه اگه ببینه رو سرور standby شما apply انجام نمیشه میاد دیتابیس اصلی شما رو shutdown میکنه
خب در برخی مواقع در حالت قبلی ما نمیخوایم سرورمون shutdown بشه یعنی اینکه ممکنه سرور اصلی ما دیسکهای خودشو داشته باشه همچنین سوای اینکه کاربرها دارن کار میکنن و حالا ممکنه طول بکشه تا دیتاها روی standby اعمال بشه میگیم که این قضیه که سرور اصلیمون shutdown نشه برامون خیلی اهمیت داره
در حقیقت solution اوراکل برای این قضیه Maximum Availability است.
Maximum Availability میاد میگه که من Maximum Protectio رو به طور کامل تو حالت عادی دارم یعنی Sync رو تو حالت عادی انجام میدم و دیتا رو تا زمانی که توی سرور standby من apply نکردم تغییرات رو commit رو روی سرور اصلی انجام نمیدم.
اما همچنین اگه اختلالی بین ارتباط primary و standby به وجود اومد دیگه منتظر apply نمیمونم دیتا رو commit میکنم و زمانی که این ۲ تا ارتباطشون باهم برقرار شد از طریق apply log که در مرحله قبل توضیح دادم دیتا رو میاد روی سرور standby با استفاده از Archive Redo Log فایل apply میکنه