نگاهی بر معماری Oracle Database 11g - قسمت اول
KEEP buffer pool
اگه جداول base ما در محاسباتمون زیاد استفاده میشه (موقع join ها) و گزارشگیریهای زیادی ازشون انجام میشه برای اوراکل نمیصرفه هر دفعه اطلاعات شما رو بیاره تو database buffer cache پس اوراکل جدول رو KEEP میکنه یعنی جدول base رو میخونه میاره تو حافظه تو محفظهی KEEP buffer pool پس دیتایی که دائما توی گزارشهامون مورد استفاده قرار میگیره و تغییراتی روش انجام نمیشه رو اوراکل به صورت KEEP نگه میداره مگر اینکه دیتابیس بیاد پایین یا برق سرور بره
همچنین این کار موقع ساختن جدول یا بعدش با دستور alter امکان پذیره همچنین میتونید برای اینکار اسکریپت هم بنویسید
Alter table emp storage (buffer_pool Keep);
یه نمونه اسکریپت
Oracle Automating Script for KEEP Pool Caching Tables & Indexes db_keep_cache_size
BEST PRACTICE اینه که فقط جداول پایه با حجم کم رو KEEP کنید در کل جداولی با داده کم و کاربرد زیاد مثل اطلاعات: شهرها، فرمولهای مالی، نرخ سود، نام دپارتمانها و ...
نکته: هیچوقت یک جدول بالای 1 میلیون رکورد رو KEEP نکنید چون بیخودی حافظه رو میگیره
نکته: اگه دیتا زیاده و تغییرات داره بهتره از TimesTen استفاده بشه (این محصول دیتا رو کلاً میخونه میذاره تو حافظه بعد خودش دیتابیس رو مدیریت میکنه که اگه دیتا تغییر کرد دیتای حافظه هم تغییر کنه و ...)
RECYCLE buffer pool
حالتهایی که شما نمیخواین اوراکل از الگوریتم LRU استفاده بکنه یعنی تا از حافظه خوندی از بینش ببر و تو database buffer cache نگهش ندار (تا جدول رو از حافظه میخونه(SELECT) حافظه خالی میشه)
nK buffer cache
شما وقتی دیتابیس رو نصب میکنید فقط ۱ بلاک سایز میتونید داشته باشید (۸ ،۱۶ و ...) ولی فکر کنید ما یه پروژهای داریم که میخوایم تمام اطلاعات شناسنامه مخصوصا عکس رو نگهداری کنیم پس باقی فیلدهای ما متنی هستن و یک فیلد عکس
شما وقتی میخواین عکسها رو ذخیره کنید از data typeهای زیر استفاده میکنید
- LOB
- LONG RAW
- BLOB
- CLOB
- NCLOB
- BFILE
- SECUREFILES
LOB, LONG RAW
البته قبل از همه اینها از LONG استفاده میشد که حداکثر تا ۲ گیگ دیتای باینری، تکس و ... استفاده میشد، مشکل این data type اینه که اگه جدولی درست کنیم که بگیم میخوایم تو یه فیلدش عکس رو نگه داریم و تو یه فیلدش متن رو از جنس long نمیتوان ۲ فیلد long و long raw در یک جدول نگه داشت (مثلا یه فیلد عکس یکی رزومه)
اشکال بعدی تو performance ه یعنی دقیقاً مثل cd و tape یعنی نوع دسترسیها متفاوته
مثلا ما متن یه کتابی رو تو Long میذاریم بعد مثلا بخوایم یه جمله از وسط کتاب یا یک صفحه از وسط کتاب رو پیدا کنیم تو long باید از کاراکتر 1 تا کاراکتر موردنظر رو بگرده (دسترسی به صورت serial)
بزرگترین مشکل LOB, LONG RAW اینه که تو replication شرکت نمیکنن (sync کردن اطلاعات بین ۲ سرور یا با replication انجام میشه یا با streams)
CLOB
مشکل دسترسی LOB رو نداره (دسترسی به صورت random) یعنی میتونید با پکیج dbms_lob بگید از کارکتر ۱۰۰۰۰ به بعد رو بخون مثلاً:
حداکثر حجم ۴ گیگ
CLOB فقط برای کاراکتر استفاده میشه
NCLOB
ذخیره کارکترها به صورت National با همون مزایای BLOB
BLOB
یادتون باشه به هیچ عنوان نمیشه روی فیلدهای BLOB ایندکس معمولی گذاشت روی BLOB باید از oracle text اسفاده کنیمکه بهش context index میگیم تو این حالت شما میتونید یک فایل txt, doc, docx, rtf حجیم رو بریزید تو دیتابیس مثلا ۵۰۰ صفحه و context index میاد لغت به لغت براتون index میکنه و بعدش هم میتونید به راحتی توش جستجو کنید (هیچ مشکلی هم با فارسی و زبانهای دیگه نداره)
اگر فایلی که تو BLOB میریزید pdf باشه context index تمام انگلیسیها رو ساپورت میکنه ولی فارسیها رو نمیتونه ساپورت کنه
خب اگه ما خواستیم متن کتاب رو بعد از ذخیره بخونیم و نمایش بدیم خوبه که بلاکهامون رو بزرگ بگیریم یعنی multiblock sizing راه بندازیم چون نباید به اون 8k پیشفرض دست بزنیم چون تراکنشهاتون به مشکل میخوره
نکته: برخی برنامهها موقع نمایش اطلاعات تمام فیلدها رو همراه با عکس رکورد نشون میدن خب این دسته از برنامهنویسان به خاطر عدم آگاهی از ساختار دیتابیس کار رو برای خودشون راحت میکنن ولی یادتون باشه به عنوان یک DBA برای بحث performance باید با تیم برنامهنویسی تبادل نظر داشته باشید و حتماً تاکید کنید که از lazy loading برای نمایش اطلاعات تکمیلی فرد استفاده کنند اینکار به این خاطره که اگه همه اطلاعات رو باهم بخواین نشون بدین اطلاعات باید بره با همون بلاک سایز پیشفرضتون (مثلا 8k) تما ماطلاعات رو io بزنه و بیاره
(nK buffer cache)Multiblock Sizing
توی multiblock sizing اولین چیز اینه که بین database buffer cache و بلاکهای دیسک تناظر ۱ به ۱ وجود داره
نکته: اگه خواستید اطلاعات تکمیلی فرد رو نگهداری کنید (عکس، اسناد و ...) به هیچ عنوان جزو فیلدهای همون جدول نگیرید بهتره یک جدول بگیرید اطلاعات شخص (نام، نام خانوادگی، نام پدر،شماره کارمندی و ...) و یک یجدول دیگهای بگیرید و شماره کارمندی رو pk - fk کنید و اطلاعاتی مثل عکس و اسناد و ... رو تو این جدول بذارید که بتونیم multiblock sizing رو راه بندازیم همچنین وقتی اپلیکیشن بخواد اطلاعات اضافی رو برای اون رکورد بیاره فقط یک رکورد رو از جدول دوم میخونه
- برای جدول اطلاعات پایه شخص = 4k
- برای جدول اطلاعات تکیلی فرد = 32k
نکته: اگر دیتابیستون ۳۲ بیتی باشه و سیستمعاملتون هم ۳۲ بیتی باشه اوراکل از 32k برای بلاک سایزهاتون پشتیبانی نمیتونه بکنه و حتما باید سیستمعامل و دیتابیستون ۶۴ باشه
این همون nK buffer cache ه یعنی میتونید بگید هر جدول چه بلاک سایزی داشته باشه
SECUREFILES
دقیقا مثله BLOB ه ولی اوراکل performance رو بالاتر برده
سناریوی Delete
دیتا اگه توی database buffer cache نباشه میره io میزنه و توی database buffer cache قرار میده و tag مربوط به delete و lock رو برای رکورد میزنه اطلاعات قبلی رو هم در undo segment قرار میده اینجوری اگه کاربر rollback زد میره io میزنه و از undo segment میخونه و میاره تو database buffer cache و رکورد رو آپدیت میکنه و tagهای delete و lock رو برمیداره ولی اگه commit بزنیم فقط tag lock برداشته میشه و اطلاعات در database buffer cache موجوده و هنوز io نمیزنه که تو دیسک بنویسه ولی Undo segment رو پاک میکنه
Redo Log Buffer
یک بافر چرخشی SGA که همه تغییرات SGA رو (قبل commit, rollback بعد commit, rollback) نگهداری میکنه
به هر تغییری که توی Redo Log Buffer ثبت میشه هم یک redo entries گفته میشه
مثلا ۱۰ تا کاربر همزمان باهمدیگه insert, delete, update بزنن تمام کارهاشون تو redo log buffer به صورت یک redo entries نگهداری میشه (تمام دستورات DDLای و DMLای)
یادتون باشه فرمت redo log buffer دیگه LRU نیست و اولین تغییری که شما بدید توی redo log buffer ریخته میشه حتی وقتی update میزنید خود update میره تو log buffer و میره select میزنه و دیتا رو تو database buffer cache میذاره
redo log buffer کارش فقط برای اینه که بشه بافرها رو توی redo log file نوشت اونم فقط واسه instance recovery
Redo Log File
وقتی Redo Log Buffer از روی حافظه بر روی Redo Log File ها نوشته بشه (Redo Log File یک فایل باینری است که تمام بافر از روی حافظه بلافاصله بهش منتقل میشه)
مثلا شما insert, delete, update بزنید بلافاصله در این فایل نوشته میشه اگه بزنید commit اون هم تو این فایل نوشت میشه همه اینها با تاریخ دقیق در فایل نوشته میشن
معمولا Redo Log File ها گروهیاند و حداقل ما نیاز به ۲ گروه داریم چون Log Writer سریعتر از database buffer cache مینویسه به خاطر اینکه ما با یک فایل باینری سر و کار داریم تا اینکه database buffer cache بره تو data file بنویسه (محاسبه بلاکها، پیدا کردن rowid، ایندکسبندی و ...)
پس Redo Log Buffer به سرعت تو Redo Log File خالی میشه پس اگه commit کرده باشید یا نکرده باشید میریزه توی این فایل پس هر crache ای اتفاق بیوفته و هنوز تغییرات توی data file نوشته نشده باشه توی ریستارت بعدی اوراکل instance recovery میکنه
انواع recovery
- instance recovery = در حقیقت DBA هیچ نقشی در آن ندارد و اوراکل خودش کارها رو انجام میده
- media recovery = یعنی یک فایل بپره، data file پاک بشه، control file براش اتفاقی بیوفته اینجا DBA میاد وسط
زمان خالی شدن Redo Log File
- اگر به 1/3 ظرفیت خودش برسه مثلا اگه ۹ مگ باشه به محض اینکه ۳ مگ پر بشه خالی میشه
- هر ۳ ثانیه یکبار اتفاقی بیوفته
- اگه commitای اتفاق بیوفته
- checkpoiint اتفاق بیوفته
- اگر Log Switch اتفاق بیوفته
هر کدوم از اینها زودتر اتفاق بیوفته Redo Log File خودشو خالی میکنه رو دیسک
مثلا هنوز ۱ مگ از Redo Log File ما پر شده ولی کاربر commit زده پس دیگه منتظر پر شدن 1/3 نمیشه
هر گروهی در Redo Log File میتونه یک یا چند عضو داشته باشه مثلا گروه اول ۳ فایل داره و گروه دوم ۵ فایل
موقع نصب و بعد از نصب میتونید گروه جدید بسازید و گروههای دیگه رو پاک کنید، عضو اضافه کنید، عضو کم کنید و ...
یادتون باشه اعضا mirror هم هستند یعنی اگه تو یک گروه یک فیال ۵۰ مگی دارید حتما باقی فیالهای اون گروه هم ۵۰ مگ هستند
چرا میگیم ۲ گروه یکی کافی نیست؟ اولاً ما میخوایم redundance ای ایجاد کنیم ثایاً وقتی اعضای یک گروه پر شوند اوارکل یا باید overwide کنه حالا فرض کنید همون موقع سرور بخوابه یا کرش کنه پس ما رکرودهامون رو از دست دادیم
پس ما حداقل ۲ گروه نیاز داریم که روی خودش ننویسه و redo log fileهامون هنوز activeباشن و به درد instance recovery بخورن
Log Switch = حالتی که از فایل اول به فایل دوم switch میکنه سیگنالی به database buffer cache میره که حالا توی دیسک بنویس و اون redo log file در حقیقت deactive میشه
پس شما چه rollback کنید، commit کنید یا هیچ کاری نکنید اوراکل میگه یکدونه رکورد رو هم از دست نمیدم
نکته: عضوها رو زیاد کنید و هر عضو رو توی یک آدرسی بذارید تا اگه یه دیسک کرش کرد بتونید از باقی عضوها استفاده بکنید
نکته: فضای redo log file رو زیاد کنید تا به سرعت log switch اتفاق نیوفته که بخواد سریع از database buffer cache روی data file بنویسه اگه حجم redo log fileهاتون کم باشه waiting اتفاق میوفته به خاطر log switch پس نباید بذارید هر ۵ ثانیه بره تو data file بنویسه شما باید alert log رو نگاه کنید و جوری تنظیم کنید که به نفع پروژه باشه
best practice برای اینکار هر نیم ساعت یکباره
(مثلا ۲۵۰ مگ)

Large Pool
بیشترین استفاده اوارکل ازش موقع بکآپ گیری با RMAN ه
همچنین موقعی که دیتابیس رو به صورت shared نصب میکنیم و از حالت dedicated استفاده نمیکنیم
dedicated = به میزان هر user process ما یک server process داریم (پس هر کاربری که با دیتابیس connection برقرار میکنه یک server process مخصوص براش بالا میاد و به غیر از اون کاربر به هیچ کاربر دیگهای سرویس نمیده) این حالت ram, cpu زیادی رو مصرف میکنه
shared = اگه به شکل بالا دقت کنید ما یک قسمتی در large pool داریم به اسم request queue که درخواستهای کاربران مختلف رو گرفته و برای پردازش تو صف قرار داده این کار توسط dispatcher انجام میشه که میاد کار رو از user process میگیره و برای پردازش تو صف قرار میده و بعد server process از صف میاد کارها رو برمداره و انجام میده پس تو shared یک server process به چندین کاربر سرویس میده server process بعد از انجام هرکاری جواب رو توی response queue قرار میده
اینجا دیگه server process کاری به کاربر نداره و فقط dispatcher وظیفه پاسخ به کاربر رو داره
dispatcher وقتی داره درخواستها رو از user proceess میگیره قبل اینکه توی request queue درخواست رو قرار بده به response queue نگاه میکنه و اگه درخواستی آماده باشه جواب رو به کاربر مربوطه تحویل میده
وقتی تعداد کاربران زیاد باشه dispatcher ها هم باید زیاد باشن و به نسبت باید server processهامون نیز به اندازه کافی باشند (به اندازه max ای که ما تعیین میکنیم اوارکل server process و dispatcher بالا میاره)
شما حتی میتونید initilize کنید dispatcherها رو یعنی مثلا همیشه ۲ تا server process یا 4 تا dispatcher باشه
(مدیریت server processها و dispatcherها با خود اوراکله)
نکته: یادتون باشه اگه به اندازه کافی حافظه نداشته باشید و max رو برای server processها یا dispatcherها زیاد بذارید جوری که بیشتر از مقدار حافظتون باشه چون هر server process و dispatcher ای حافظه اشغال میکنه اگه اوارکل dispatcherها و server processهای زیادی رو بالا بیاره باعث پایین اومدن performance میشه

Java Pool
از ورژن 8i اوراکل کلاً JVM رو به صورت embed درون دیتابیس قرار داد
پس به جای pl/sql میشه از جاوا استفاده کرد
شما اگه برنامه جاوایی رو داخل دیتابیس اجرا کنید قسمت اجراش میاد توی Java Pool میشینه
Strams Pool
تو ورژنهای جدید اوراکل به جای replication از streams استفاده میکنه که archive logها رو میفرسته سمت سرور دوم
با streams شما میتونید ۲ یا چند دیتابیس رو باهم sync بکنید البته لزومی نداره sync رو به صورت %100 بکنید ممکنه شما بخواین ۱۰ تا جدول رو بخواین sync کنید یا هر ۱۰ تا رو هم تو سرور اول و هم تو سرور دوم داشته باشید و بخواین بگید فقط یک جدول sync دائم باشه قطعاً به صورت برعکس هم sync قابل انجامه یعنی هر اتفاقی رو این سرور افتاد رو سرور دوم هم بیوفته و البته این حالت میتونه یکطرفه و دوطرفه باشه
تو این حالتها اوراکل از streams pool برای کارهای sync استفاده میکنه

گفتیم که هر کاربری که به دیتابیس وصل میشه یک session ایجاد میشه و وقتی session برقرار شد یک server process سمت سرور بالا میاد و یک PGA برای اون session ایجاد میشه
PGA در حقیقت ۲ تا کامپوننت داره:
- Stack Space
- User Global Area
اینو یادتون باشه خود User Global Area قسمتهای مختلفی داره
- Cursor State
- User Session Data
- SQL Working Areas
User Session Data
وقتی یک select میزنیم و میخوایم hash کدش یکسان باشه از bind variable ها استفاده میکنیم که از کامپایل شدن syntax برای هربار جلوگیری کنیم
خب اون متغیر ما ممکنه تو هر session ای توسط کاربر متفاوت وارد بشه و مقادیر مختلفی بگیره
این مقادیر توی user session data میشینه
خود sql هم بعد کامپایل شدن توی library cache قرار میگیره
Cursor State
وقتی شما cursor مینویسید اوراکل pointerها و متغیرهاش رو توی Cursor State نگهداری میکنه
Sort Area
ممکنه که شما به کوئریتون order by اضافه بکنید تو این مواقع موقع خوندن دیتا هیچ اتفاقی نمیافته یعنی میاد بلاک رو میخونه و physical read ها رو میزنه بعد میاد دیتا رو توی database buffer cache قرار میده
وقتی میخواد از database buffer cache بخونه sort میکنه و sort رو توی Sort Area از قبسمت SQL Wiorking Areas هر PGA قرار میده
پس هر کاربری sortاش مخصوص خودشه و توی حافظه سرور اینکار انجام میشه و درکل sort به صورت share شده نیست
اینو هم یادتون باشه ۹۰ درصد sorting باید توی حافظه انجام بشه و اگه یه وقت دیدید داره از دیسک استفاده میکنه باید Sort Area رو تو حافظه زیاد کنید
Hash Area
توی joinها یک مکانیزمی برای محاسبات هستش که optimizer ممکنه بیاد ازش استفاده بکنه
اوراکل وقتی از Hash Join استفاده میکنه محاسباتش رو توی Hash Area قرار میده
Create Bitmap Area
وقتی index bitmap میسازید از این قسمت برای محاسبات استفاده میکنه
نکته: تو سیستمهای oltp اگه bitmap index بذارید باعث کندی سیتسم میشوید
Bitmap Merge Area
موقع merge کردن ستونهای index شده bitmap و نمایش نتیجه به کاربر از این قسمت برای انجام کار استفاده میشه

پروسسهای اوراکل به بخشهای مختلفی تقسیم میشن:
- User process
- Database processes
- Deamon / Application processes
User process
User process همون tools و اپلیکیشنیه که سمت کلاینته مثل SQLPlus, SQLdeveloper, PLSQL Developer
Database processها
Database processها به ۲ قیمت تقسیم میشن:
- Server process
- Background process
- گفتیم که هر کاربری که یک session ایجاد میکنه یک server process بالا میاره
- به پراسسهایی که بعد از بالا اومدن Instance به طور خودکار اجرا میشن و کارهای مشخصی انجام میدن Background process میگن
Daemon / Application processها
- برای اتصال اپلیکیشنها به دیتابیستون شما ممکنه از وبسرورها مثل (IIS, Weblogic, ...) استفاده کنید
- یا ممکنه شما بخواین RAC Oracle راه بندازید تو این مورد شما باید Grid infrastructure رو نصب کنید که بعد از نصب grid پراسسهایی به سیستم اضافه میشوند
- یا خود listener که یک پراسسه
به این جور پراسسها دیمون میگیم

همونطور که تو شکل بالا میبینید یکسری از Background processها اجباری و یکسری اختیاریه
background processهای اجباری
DBW = Database Writer
CKPT = Checkpoint
LGWR = Log Writer
SMON = System Monitor
PMON = Process Monitor
RECO = Recover
نکته: n به معنی اینه که میتونه تعدادش زیاد باشه از ۱ تا ...
background processهای اختیاری
ARC = Archiver Processes
ASMB = ASM Background Process
RBAL = Rebalance Master
باقی background processh رو برای کانفیگهای پیشرفته مثل راهاندازی RAC میتونید در دیتادیکشنری V$BGPROCESS ببنید
اگه Grid رو نصب کنیم Background processهای ما شامل لیست زیر میشه:
- ohas = وقتی که RAC Oracle اجرا میشه Oracle High Availability Service daemon بالا میاد
- ocssd = Cluster Synchronization Service daemon
- diskmon = برای مانیتور کردن input و output توسط ASM یا در Oracle Exadata Storage Server ها این دیمون بالا میاد Disk Monitor daemon
- orarootagent = یک پراسس سفارشی شده برای کمک به مدیریت منابع سختافزاری و شبکه root
- oraagent = عملیاتهایی رو برای افزایش راندمان و پشتیبانی RAC Oracle از سختافزارهای بیشتر و پیچیده انجام میده
- cssdagent = استارت و استاپ و چککردن وضعیت دیمون ocssd
نکته: اوراکل ASMlib رو تا ورژن ۵ توزیعهای ردهتبیس ارائه داد، برای ورژنهای ۶ بسته رو به طور رسمی فقط برای اوراکل لینوکس ارائه داد و برای باقی توزیعها ارائه نداد تا نسخه ۶.۴ به بعد
برای اطلاعات بیشتر به این مستند اوراکل مراجعه کنید:
http://docs.oracle.com/cd/B28359_01/server.111/b28318/process.htm
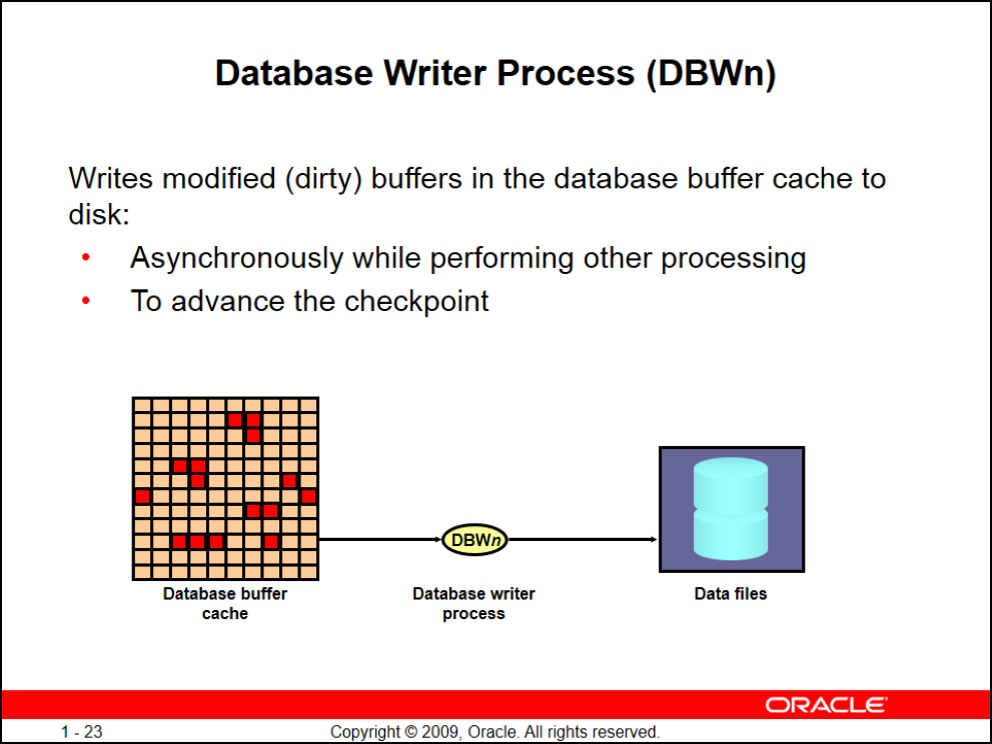
کار این background process اینه که database buffer cache رو روی دیسک بنویسه (فقط دیتای dirty رو روی دیسک مینویسه و اصلاًبه دیتای pined شده کاری نداره)
تعدد وجود DBW برای اینه که اوراکل به طور خودکار همیشه داره از دیتابیس آمارگیری میکنه و نیاز داره این آمارها رو تو دیسک بنویسه
پس حداقل تعداد DBW میتونه ۲ و حداکثر ۳۲ تا باشه
همچنین این background process نمیتوه دیتا رو از روی دیسک بخونه و فقط میتونه بنویسه و مسئلویت خوندن دیتا از دیسک با server process هز session است
یادتون باشه DBW به محض این که دیتا dirty بشه اونو تو دیسک نمینویسه و با یه delay اینکارو میکنه که از کندی جلوگیری کنه
نکته: DBW شدید به LGWR وابسته است
- DBW ممکنه به صورت asynchronous بعد از اجرای باقی پراسسها اجرا بشه
- یا موقعی که checkpoint اتفاق بیوفته (مثلاً موقع log switch که به طور خودکار checkpoint اتفاق میوفته)
گاهی اوقات ممکنه checkpoint به این صورت اتفاق بیوفته که شما select زدید و database buffer cache پر میشه حالا یکی دیگه یه select دیگه میزنه اوراکل وقتی میبینه database buffer cache جا نداره سریع DBW میاد و database buffer cache رو خالی میکنه

ممنون از مطالب خوب و متن صریحتون