Partitioning تو ۹۰ درصد مواقع به درد ما نمیخوره ولی زمانی که روی (Very Large Database (VLDB کار میکنیم که یک جدول ممکنه ۱ گیگ باشه اونوقت باید از تکه تکه کردن یا همون Partitioning استفاده کنیم.
چرا از Partitioning استفاده میکنیم؟
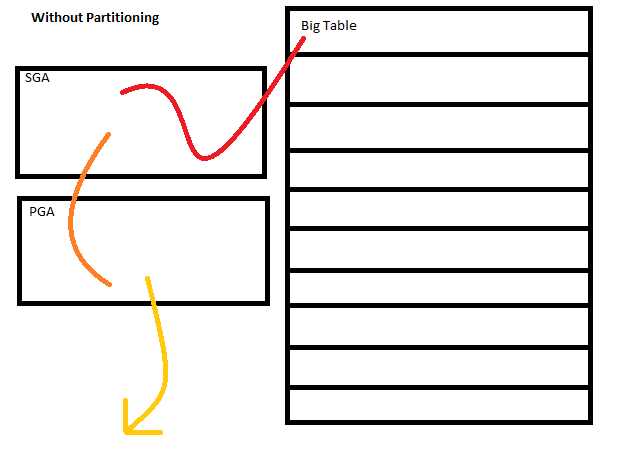
یه جدول ۱۰۰ گیگی رو در نظر بگیرید برای کش جدولی که به صورت فیزیکی ۱۰۰ گیگه تقریباً حداقل ۱۶ گیگ رم نیاز داریم، اما وقتی ما ۲ گیگ بیشتر رم نداریم باید چی کار کنیم؟ تو این شرایط اوراکل نمیتونه کش رو یکجا انجام بده پس به صورت پیشفرض اوراکل کش را تکه تکه انجام میده یعنی قسمتی را وارد SGA میکند و پردازش میکند و بعد از پردازش قسمتی دیگر را وارد SGA میکند و پردازش میکند. حتی اگر where هم گذاشته باشید این اتفاق بازهم میافته کل جدول رو تیکه تیکه میاره تو فضای SGA و توسط PGA پردازش میکنه و به همین ترتیب تا پایان پردازش کل جدول ادامه میده.
توی ۹۰ درصد مواقع شاید من لازم داشته باشم به این روش عمل کنم:
خب اوراکل میگه با table ای که خیلی سنگینه مثل چندتا table برخورد کن این مبحص رو از قبل از Partitioning هم داشتیم توی سیستمهایی که very larg data بودن (یا همون huge databaseها) به عنوان مثال یه جدول به اسم person نمیگرفتیم توی این دیتابیسها ۳ تا table میگیرم اونایی که بالای ۲۰ سالاند اونایی که ۲۰ سالاند و اونایی که زیر ۲۰ سالاند. پس ۳ تا table خودم ایجاد میکردم و زمانی که میخوام کوئری بگیرم چون میدونم چی رو میخوام فقط از رو همون table کویری میگیرم.
به این مبحث میگن Distributed Table یعنی جداول توزیع شده
ولی اوراکل تو ورژنهای جدید مفهومی رو ارائه کرده به نام Partitioning که خودش این کار رو برامون انجام میده در حقیقت بعد از Partitioning ما از لحاظ منطقی با یک جدول کار میکنیم ولی از لحاظ فیزیکی چند جدول وجود داره، پس وقتی Partitioning میکنید به تعداد هر پارتیشن ایجاد شده توسط شما انگار یک جدول ایجاد شده واسه همینه where توی SGA و توی Partitioning تاثیر گذاره (توی جداولی که Partitioning نشدن where تو کش اولیه تاثیر گذار نیست)
حالا چون جدولمون Partitioning شده انگار من با چند جدول سر و کار دارم پس اوراکل قبل از اینکه where رو توی PGA روی دادههای SGAپردازش کنه میاد از where استفاده میکنه و اون جدولی که مربوط به اون where است رو فقط توی SGA کش میکنه.
نکته: به این موضوع دقت بکنید که Partitioning بر مبنای چه فیلدی انجام شده است. بهتره بر مبنای اون فیلدی Partitioning رو انجام بدید که بر مبنای اون فیلد میخواهید کوئری بگیرید.
نکته: برای راحتی در یادگیری میتوانید where را نام جدول در Partitioning در نظر بگیرید و نه یک دستور پردازشی
نکته: کنترل Distributed Table سخت است و Partitioning خیلی راحتتر از جداول توزیع شده است.
نکته: توی اوراکل فقط table partitioning داریم و database partitioning نداریم چون توی sqlserver شما database datafile دارید ولی توی اوراکل ما table datafile داریم و اینا باهم فرق دارند. (در اوراکل جداول به datafile ها وصل هستند نه کل دیتابیس به datafileها)
نکته: هر دیتابیسی دارای یک tablespace default است و بستگی به یوزر داره که datafileها جدا باشند یا نه
س: Partitioning فقط برمبنای یک فیلد جدول انجام میشه؟
ج: بله
نکته: Partitioning هر جدول با فیلد همان جدول انجام میشه ولی وقتی دارید ضرب دکارتی به شرط تساوی بین ۲ جدول انجام میدید(Join) یکی از جداول بر مبنای address پارتیشنبندی شده و یکی بر مبنای age پارتیشنبندی شده ابتدا میره شاخص بزرگتر رو درنظر میگیره بعد دنبال شاخص کوچیکتر میگرده یعنی تو لود تاثیر گذاره ولی اول هم یادتون باشه میره دنبال شاخص بزرگتر (index گذاری بر مبنای شاخص بزرگتر است)، اگر میخواست بر مبنای شاخص کوچیکتره باشه یکسری اطلاعات از جدول دوم لود نمیشد.
نکته: بعد از Partitioning جدولتان اگر در کوئری خود where به کار نبرید انگار از همه جداول select گرفتید.