تست لود تصادفی
در این تست لود تصادفی برای تکنولوژی VMFS و RDM به جهت دسترسی به سرعت و کارایی بالا مد نظر است:
لود تصادفی ادغامی (50 درصد تست دسترسی خواندن و 50 درصد تست دسترسی نوشتن) (بالا بودن نمودار عملکرد بهتر را نشان می دهد)
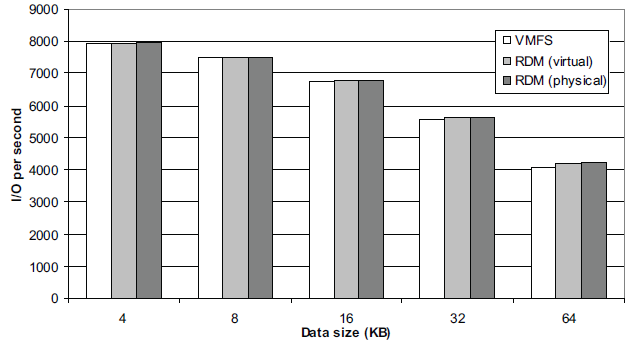
دسترسی تصادفی خواندن برای عملیات I/O در هر ثانیه (بالا بودن نمودار عملکرد بهتر را نشان می دهد)

دسترسی تصادفی نوشتن برای عملیات I/O در هر ثانیه (بالا بودن نمودار عملکرد بهتر را نشان می دهد)

تست لود ترتیبی
برای خواندن ترتیبی با بلاک سایز 4K ما تغییراتی را در مقدار بلاک سایز کش در سخت افزار خود (CLARiiON CX3‐40) به مقدار 4k انجام داده ایم. البته برای باقی تست ها از همان مقدار پیش فرض 8K در بلاک سایز کش استفاده کرده ایم.
در سرور ESX 3.5 سرعت و کارایی لود ترتیبی تکنولوژی VMFS خیلی نزدیک به RDM برای تمام بلاک سایزهای تولیدی به جز 4K بود.اغلب اپلیکیشن ها با لود ترتیبی از بلاک سایزهایی با مقادیر بیشتر از 4K استفاده می کنند. هر 2 تکنولوژی های VMFS و RDM تقریبا عملکردی مشابه در سرعت و کارایی داشتند.
هر 2 تکنولوژی های VMFS و RDM توان کاری (throughput) بالایی را از خود نشان دادن به جز مواردی که باری نزدیک 300 مگابایت در ثانیه در حال اجرا بود.
تست لود خواندن ترتیبی عملیاتهای I/O بر حسب ثانیه (بالا بودن نمودار عملکرد بهتر را نشان می دهد)

تست لود نوشتن ترتیبی عملیات های I/O بر حسب ثانیه (بالا بودن نمودار عملکرد بهتر را نشان می دهد)

جداول پایین میزان توان کاری (throughput) بر حسب ثانیه را برای VMFS و RDM مکتوب کرده اند. میازن توان کاری(throughput) بر حسب (عملیات های IO * سایز دیتا) با نمایش مقدارهای متناظر است:
جدول میزان توان کاری برای لود تصادفی بر حسب مگابایت بر ثانیه
|
Random Write |
Random Read |
Random Mix |
|||||||
|
RDM (P) |
RDM (V) |
VMFS |
RDM (P) |
RDM (V) |
VMFS |
RDM (P) |
RDM (V) |
VMFS |
Data Size (KB) |
|
45.87 |
46.1 |
46.38 |
23.27 |
23.27 |
23.41 |
31.15 |
30.98 |
30.96 |
4 |
|
88.74 |
89.22 |
90.24 |
44.35 |
44.43 |
44.67 |
58.68 |
58.68 |
58.8 |
8 |
|
159.42 |
158.25 |
161.2 |
80.58 |
80.72 |
80.14 |
105.09 |
106.03 |
105.22 |
16 |
|
242.05 |
241.12 |
241.4 |
138.11 |
138.53 |
135.91 |
176.69 |
176.1 |
173.72 |
32 |
|
310.15 |
311.13 |
309.6 |
214.59 |
215.49 |
215.1 |
263.98 |
262.92 |
256.14 |
64 |
جدول میزان توان کاری برای لود کاری ترتیبی
|
Sequential Write |
Sequential Read |
|||||
|
RDM (P) |
RDM (V) |
VMFS |
RDM (P) |
RDM (V) |
VMFS |
Data Size (KB) |
|
93.36 |
93.8 |
93.76 |
153 |
142.13 |
137.21 |
4 |
|
187.84 |
188.45 |
188.45 |
188.56 |
284.41 |
272.61 |
8 |
|
278.91 |
281.17 |
281.17 |
280.95 |
338.75 |
341.08 |
16 |
|
352.89 |
354.86 |
354.86 |
352.17 |
364.23 |
363.86 |
32 |
|
386.81 |
385.36 |
384.02 |
377.09 |
377.6 |
377.35 |
64 |
هزینه CPU
هزینه CPU براساس تعداد سایکل های CPU برای انجام یک عمل واحد I/O برای استفاده از توان کاری (به بایت) محاسبه میگردد. ما محاسبه سایکل های CPU را براساس استفاده ماشین مجازی از CPU فیزیکی برای اجرای تست لود کاری گرفته ایم. ما برای محاسبه لود کاری سربار مجازی سازی را نیز جهت مجازی سازی ماشینهای متفاوت براساس پراسس های سرور ESX حساب کرده ایم. توان CPU براساس MHz و تمام coreهای درگیر در سیستم رنک بندی میگردند. در این مطالعه معیارهای هزینه CPU براساس تعداد سایکل های CPU بر حسب واحدهای عملیاتی I/O در هر ثانیه دیده شده است.
نتیجه هزینه CPU عادی برای لودهای کاری متفاوت در شکل های زیر نمایش داده شده است. ما هزینه CPU را برای RDM (مپ کردن فیزیکی دستگاه ذخیره ساز به ماشین مجازی) برای هر تست لود کاری با مقایسه آن با تکنولوژی VMFS مشخص کرده ایم.
در تست لود تصادفی هزینه CPU تکنولوژی VMFS حدود 5 درصد بیشتر از هزینه CPU در تکنولوژی RDM بوده است.
همچنین در تست لود ترتیبی هزینه CPU تکنولوژی VMFS حدود 8 درصد بیشتر از هزینه CPU در تکنولوژی RDM بوده است.
مانند هر فایل سیستم دیگه ای VMFS نیز ساختمان داده را برای مپ شدن دیتا بر روی دیسک فیزیکی در خود ذخیره می کند.هر درخواست I/O برای دستسری به دیتای ذخیره سازی شده ابتدا باید یک درخواست برای لود متادیتا ارسال کند تا مپ بلاک های دیسک قبل از هر عملیات خواندن یا نوشتن در حافظه لود گردد. هربار انجام اینکار سایکل CPU را تعدادی بالاتر می برد. پس طبیعی است برای دسترسی به داده های زیاد در زمان کم ما نیاز به سایکل های خیلی بیشتری داریم. بر عکس VMFS تکنولوژی RDM نیازی به این مپ ندارد. وقتی دیتا به صورت مستقیم بر روی دیسک شما نوشته می شود سربار اضافه حذف میگردد و سایکل های CPU اضافه ای رخ نخواهد داد پس از نظر CPU تکنولوژی RDM خیلی بهتر از VMFS عمل می کند.
هزینه CPU عادی برای دسترسی تصادفی به صورت خواندن/نوشتن در انواع بلاک سایزها (نمودار کم بهتر است)

هزینه CPU عادی برای دسترسی تصادفی به صورت خواندن در انواع بلاک سایز ها (نمودار کم بهتر است)

هزینه CPU عادی برای دسترسی تصادفی فقط نوشتن در انواع بلاک سایزها (نمودار کم بهتر است)

هزینه CPU عادی برای دسترسی تصادفی فقط خواندن در انواع بلاک سایزها (نمودار کم بهتر است)

هزینه CPU عادی برای دسترسی تصادفی فقط نوشتن در انواع بلاک سایزها (نمودار کم بهتر است)
