یک بکآپگیری درست و مطمئن باعث میشه که ما یک اطمینان بازیابی داشته باشیم و این اطمینان بازیابی هست که تو سازمانها بیشتر نیاز است. پس بازیابی خیلی اتفاق نمیافته و اطمینان به بازیابی خییلی مهمه. شما میتونید حتی مانورهاتون رو انجام بدید و ببینید که بازیابی به طور کامل انجام میشه یا نه
این قسمت شروع مقدماتی کارکردن با RMAN هستش که چجوری به محیط خط فرمان RMAN و پنجره EM RMAN متصل بشیم و بتونیم فرمانهای بکآپگیری رو صادر کنیم و بتونیم با محیطش کارکنیم. محیط EM محیط خیلی سادهای است برای کارکردن ولی تو این محیط شما با CONSEPTهای بکآپ آشنا نمیشید و درکشون نمیکنید چون کاملاً گرافیکیه همچنین مشکل TIME ZONE تهران رو داره که توسط محیط EM ساپورت نمیشه
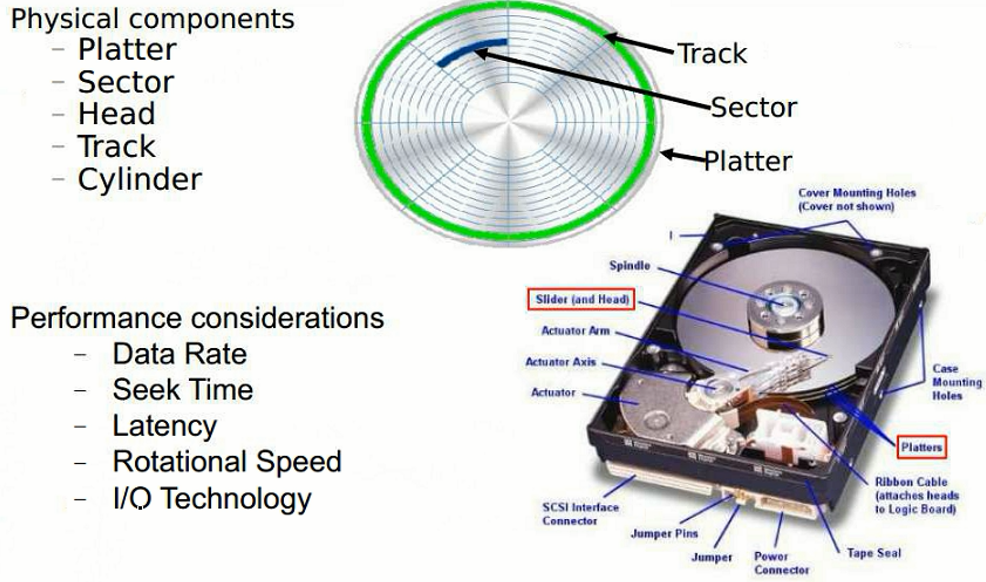
نکته: تو این سری از نوشتهها بکآپ گیری روی معماری filesystem رو بررسی میکنیم و با معماری ASM کار نداریم
یکی از مهمترین وظایف ادمینهای دیتابیس تعیین استراتژی بکآپه و در حقیقیت میتوان در ۵ لایه ادمینی دیتابیس را دستهبندی کرد: backupman, storageman, securityman, performanceman, clusterman و هر کدوم از اینها نیاز به یه تیم و تخصص بالا داره
تعیین استراتژی دست ادمین دیتابیسه و شما به عنوان ادمین دیتابیس باید تعیین کنید که کدوم استراتژی بیشترین کارایی رو در سازمانتون داره
استراتژی اول
بکآپ به صورت Backupset و از طریق Incremental Backupset در ۲ لول (لول ۰ و ۱) توصیه شده که بتونه بهینهترین نوع فضا رو استفاده کنه
نیازسنجی بکآپ
برای بکآپ نیاز داریم که دیتابیسها رو به archive ببریم بحث آرشیو کردن برای بکآپ نیازه
- فعالسازی حالت force logging (دیتابیس هر آنچه داخلش به وقوع میپیونده، تمام فرآیندهای نوشتن/ خواندن/ بروزشدن/ پاکشدن) با فعالسازی این قابلیت تمام این فعالیتها لاگ میشه و از redologها عبور میکنند در کل ما این امکان رو داریم که فرآیندها رو در دیتابیسمون از redolog عبور ندیم و ارزشش برای ما افزایش کارایی است. مثلاً داریم یک insert خیلی طولانی میزنیم و فرصت زیادی هم نداریم پس لاگ کردن رو برمیداریم و از redolog عبور نمیکنه
خطر این اتفاق برای ما اینه که اگه فراموش کردیم و بکآپامون رو گرفتیم اون بخشهایی از دیتا که عملیات غیر loging روش انجام شده قابل خوندن و بازیابی برای ما نخواهد بود و در واقع اصلا دیده نشده. به خاطر همین دیتابیس رو در وضعیت force loging قرار میدیم
وقتی دیتابیس در این وضعیت قرار میگیره یعنی همه چی به صورت اجباری باید در وضعیت loging قرار بگیره تا هیچچیز از گذر redologها نتونه عبور کنه و هرفرآیند بروزرسانی تو دیتابیس از این گذر عبور کنه
SQL> Alter database force logging
برای تنظیم پایگاه داده در وضعیت ARCHIVE LOG از یوزر sys استفاده میکنیم. برای فهمیدن اینکه دیتابیس ما تو وضعیت آرشیو هست یا نیست از دستور زیذ استفاده میکنیم:
SQL> archive log list
| Archive Mode |
Database Log Mode |
| Enabled |
Automatic Archival |
| USE_DB_RECOVERY_FILE_DEST |
Archive Destination |
| 5161 |
Oldest Online Log Sequence |
| 5162 |
Next log Sequence To Archive |
| 5163 |
Current Log Sequence |
اطلاعاتی که به ما میرسه
Database log mode = وضعیت فعال بود لاگ
Automatic archival = وضعیت گرفتن آرشیو به صورت اتوماتیک
Archive destination = یعنی فایلها در فضای پارامتر use_db_recovery_file_dest قرار میگیره که همون فضای fra هستش (میشه این مسیر و متغیر رو عوض کرد)
Oldest online log sequence = بحث redo log fileها هستش | شماره قدیمیترین sequence ای که رخ داده
Next log sequence to archive = شماره seq بعدی که رخ میده
Current log sequence = جدیدترین sequnce
اوراکل یه فایلی داره به نام parameter file این فایل برای set کردن پارامترهای شخصی در سیستم است. اوراکل ۲ جور فایل پارامتر داره:
1: system parameter file
2: parameter file
تفاوت بین این ۲ فایل
اوراکلهای قبلی parameter file فقط بود و شما به صورت آنلاین هیچ تغییری تو سطح پارامترهای سیستمی نمیتونستید بدید (نسخه ۸) از نسخه ۹ به بعد system parameter file رو معرفی کرد که شما برخی تنظیمات سیستمی رو میتونید به صورت آنلاین انجام بدید (این بهتون کمک میکنه availibility کارتون بالا بره) مثال:
lOG_ARCHIVE_DEST_1='LOCATION=X:\archive
VALID_FOR=(ALL_LOGFILES,ALL_ROLES)
DB_UNIQUE_NAME=eorg'
LOG_ARCHIVE_DEST_STATE_1=ENABLE
LOG_ARCHIVE_FORMAT=archive_%s_%t.%r
LOG_ARCHIVE_MAX_PROCESSES=9
control_file_record_keep_time = 60
lOG_ARCHIVE_DEST_1 = اگه location ندیم از مسیر پیشفرضمون استفاده میکنه
VALID_FOR = برای چه حالتی valid است. در اینجا برای تمام حالات و log fileها تنظیم شده است.
DB_UNIQUE_NAME = برای دیدن نام دیتابیس از show parameter db_unique_name استفاده میکنیم.
LOG_ARCHIVE_DEST_STATE_1 = برای اینکه کل این تنظیمات فعال باشه یا نه
LOG_ARCHIVE_FORMAT = فرمتی که برای فایلها درنظر میگیریم، این فرمت میتونه با یه prefix ای شروع بشه s به معنی شماره sequnce ای هستش که از redo log fileها خونده میشه(شماره sequnce الزامی و واجب هستش)، t شماره thread هستش و روی دیتابیسهای کلاستر معنا پیدا میکنه چون ممکنه چندتا دیتابیس دیتابیس داشته باشید که از یک share drive استفاده کنند، r در حقیقت reset log id هستش(برای جلوگیری از duplicate شدن فرآیندهای recovery هستش چون sequnce ریست میشه و با ریست شدن باعث میشه که فایلها duplicate شه پس یه پارامتر اضافه میکنیم تا تعداد دفعات reset شدن رو داشته باشیم و باعث unique شدن فایلهامون بشه)
نکته: تخصیص sequnce از redo log file انجام میشه، درسته sequnce خود redo log file عوض نمیشه اما sequnce ای که داخل redo log file هست داره تغییر میکنه و حتی اگه شما دیتابیس رو روی mode آرشیو هم نبرید این sequnce عوض میشه و شما همیشه seqهای redo log fileهاتون در حال تغییر است. وقتی که شما ۳ تا redo log file دارید وقتی اولی، دومی، سومی پر میشه دیتابیس باید سوییچ کنه روی اولی پس چه مولفهای برای شناسوندن هستش که باید سوییچ انجام بشه؟ یه seq مسلماً به صورت Internal هستش که روی این درج میشه(این seq توی فایل redo ذخیره نمیشه و هر وقت ما بخواهیم این redo رو جایی ذخیره کنیم این seq خودش رو نشون میده) ما برای حفظ ریکاوریمون میایم redo log file ها رو که تغییرات دیتابیس هستند رو نگهداری میکنیم.
نکته: برای این که بفهمیم تو حالت force logging هستیم یا نه با viwe ه v$database میتونیم لیست رو بگیریم و هم میتونیم بزنیم Alter database force logging و وقتی باشه میگه من تو مد لاگگیری هستم. دقت کنید اگر loging فعال نباشه ممکنه برخی از دیتای شما نیاد. (این به وضعیت ادمینی بستگی داره ممکنه دادههایی که میخواین restore بشه یا نشه)
نکته: Alter database force logging بر روی performance تاثیر زیادی میگذارد. وقتی حجم دادهها از 10, 15 T میگذره این چیزها خودشون رو نشون میدن حتی فرآیندهای بکآپگیری ما تاثیر زیادی بر روی سرعت و کارایی دارد مثلاً یک جدول 50T رو با چه استاتژی بکآپ بگیریم و کمتر به مشکل بخوریم
v$ = یک dynamic viwe از data dictionary هستش که از طریق view متادیتاهای اوراکل رو خروجی میده