راهنمای کلی
جدول زیر توضیحاتی در رابطه با best practices های اعلامی توسط شرکت Vmware برای پایگاه داده اوراکل ارائه می کند:
|
ردیف
|
توصیه شده
|
علت توصیه
|
|
1
|
فعال سازی jumbo frames برای ذخیره ساز های مبتنی بر IP مانند iSCSI یا NFS
|
فعال سازی Jumbo frame ها بر روی بستر شبکه باعث افزایش ظرفیت بار ترافیک شبکه و بزرگتر شدن هر پکیج می شوند. این ویژگی همیشه برای افزایش پرفورمنس پیشنهاد می گردد.
|
|
2
|
ساخت یک datastore اختصاصی برا سرویس دهی مجزا به پایگاه داده
|
ایجاد datastore های اختصاصی همانند ایجاد LUNهای اختصاصی برای پایگاه داده در زمان استفاده از تکنولوژی VMFS است. با انجام این کار سرعت IO ورودی و خروجی افزایش خواهد یافت.
|
|
3
|
استفاده از تکنولوژی VMware RDM برای دیتابیس اوراکل
|
برای استفاده بهتر و بالا بردن سرعت استفاده از تکنولوژی RDM برای دیتابیسها با لود بالا توصیه میگردد.
|
|
4
|
استفاده از تکنولوژی Vmware vSphere VMFS برای دیتابیس اوراکل
|
برای مدیریت بهتر فضا و استفاده از تکنولوژی های Vmware HA استفاده از VMFS در دیتابیسهای تست و آزمون و با لود پایین توصیه میگردد.
|
|
5
|
تراز بودن سکتورهای VMFS با دیسک های سخت افزاری
|
مانند تمام فایل سیستم های رایج فایل سیستم VMFS نیز اگر در پارتیشن بندی پارتیشن align دیسک ها نشود می تواند مشکلاتی در ذخیره سازی (تا 40 درصد افت سرعت) و خواندن اطلاعات (تا 25 درصد افت سرعت) برایش رخ دهد. توصیه شرکت Vmware ساخت VMFSها تنها با استفاده از رابط VMware vCenter است تا به صورت خودکار پارتیشنهای ساخته شده align شوند.
|
|
6
|
استفاده از Oracle ASM
|
تکنولوژی Oracle ASM ادغام فناوری فایل سیستم های کلاستری و مدیریت فضای منطقی برای مدیریت فایلهای دیتابیس اوراکل است. ASM ساده سازی مثال زدنی جهت ذخیره سازی فایل های دیتابیس هنگام اضافه شدن یک سخت افزار جدید ذخیره سازی بدون پایین اومدن سرعت و یا قطعی دارد.
|
|
7
|
هنگام پیکربندی پایگاه داده اوراکل از مستندات فنی و best practice های شرکت سازنده ذخیره ساز استفاده کنید
|
تکنولوژی Oracle ASM نمی تواند محل مطلوب جهت ذخیره سازی داده ها را بر روی دیسک های خوب در لحظه مشخص کند. پس Oracle ASM جایگزینی برای عدم داشتن مشاور و کارشناس ذخیره سازی متخصص نیست.
|
|
8
|
استفاده از متخصص های ذخیره سازی در طراحی زیرساخت ذخیره سازی پایگاه داده
|
شما جهت طراحی مطلوب حداقل نیازمند افراد با تخصص های: مدیر پایگاه داده اوراکل، مدیر ذخیره سازی با تخصص بر روی تجهیزات مورد استفاده، مدیر شبکه، مدیر Vmware و مدیر محصول هستید.
|
|
9
|
استفاده از آداپتورهای پاراویرچوالیزیشن SCSI جهت ذخیره سازی دیتافایلهای پایگاه داده اوراکل با لود کاری بالا
|
این کنترل به صورت پاراویرچوالیزیشن جهت پشتیبانی از لود بالای ذخیره سازی IO و حداقل مصرف پردازش به خصوص برای محیط های دارای SAN طراحی شده است.
|
مفاهیم ذخیره سازی در VMware
ذخیره سازی مجازی در Vmware را می توان در 3 لایه خلاصه سازی کرد:
- لایه ذخیره ساز که در پایینترین بخش قرار دارد، شامل دیسک های فیزیکی است که به صورت دیسک های منطقی و یا LUNهای جداگانه به لایه بعدی داده شده اند.
- لایه بعدی توسط vSphere برای ماشین مجازی تعریف میگردد. LUNهای قابل دسترس برای هاست ESX / ESXi به صورت datastore رزرو شده اند و پارتیشن های ایجادی به صورت فایلهای VMFS در اختیار ماشین مجازی قرار میگیرند.
- لایه بعدی پارتیشن های ایجادی در سیستم عامل ماشین مجازی مهمان هستند که بر روی فایلهای VMFS یا به صورت مستقیم بر روی لایه اول قرار دارند.
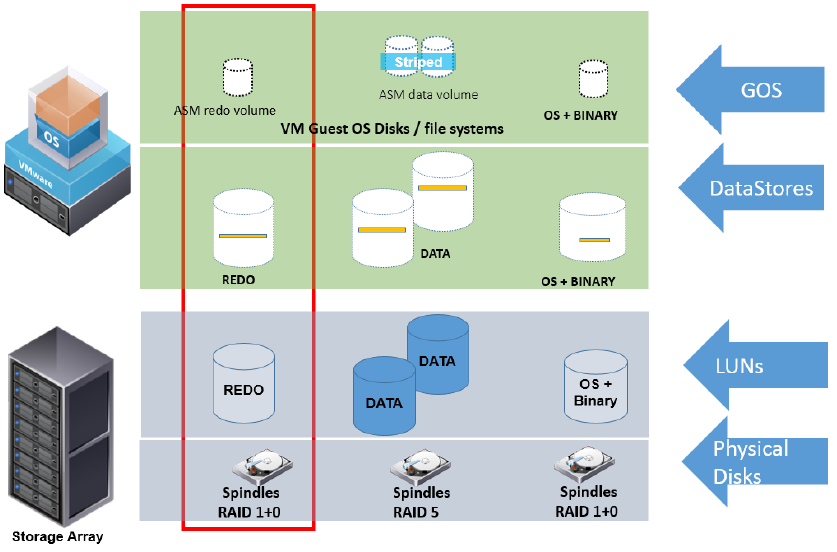
هایپروایزر شرکت Vmware یا همان VMware ESXi دارای 2 روش ایجاد دسترسی جهت ذخیره سازی بر روی دیسک های Local یا SAN است.
Virtual Machine File System (VMFS)
VMFS یک فایل سیستم کلاستر است که برای ذخیره سازی دیسک های ماشینهای مجازی بهینه شده است. ساختار هر ماشین مجازی به صورت یک مجموعه فایل کپسولی است و فایل VMFS برای دیسک این ماشین ها بر روی کنترلرهای مجازی SCSI مورد استفاده قرار می گیرد.
مزیت فایل سیستم کلاستر VMFS پشتیبانی از تکنولوژی های ESXi نظیر vSphere vMotion, DRS و vSphere HA جهت مدیریت حداکثر پایداری ماشینهای مجازی در سطح Host است.
سیاست پیشفرض شرکت Vmware استفاده از VMDK به صورت صفر شده thick provisioned lazy zeroed است که در آن بلاک های پدر VMFS با هر بار درخواست write با مقدار 1 مگابایت گرفته میشوند.
در اینجا با توجه به درخواست گرفتن فضا بعد از هر درخواست سرویس یک نوع پنالتی جهت جریمه write برای vmdk وجود دارد که میتواند بر عملیاتهای پایگاه داده در زمان پیک اثر منفی بگذارد، مثل عملیاتهای write و read که ازtablespace یا tempdb های موقت استفاده میکنند و یا بارگذاری بالک از جداول و ایندکس ها.
هایپروایزر VMware قابلیت ساخت 3 نوع دیسک مجازی را دارد که برای آشنایی بیشتر به آن پرداخت میگردد:
روش اول Thin Provisioned
از مزایای ایجاد کردن Thin Provisioned می توان به سرعت بالای ایجاد (Faster Provision) و اشغال فضای دیسک بر اساس بالا رفتن میزان فضای مورد نیاز VM اشاره کرد. در کنار این مزایا ، معایبی نیز به Thin Provisioned وارد است که از جمله آنها می توان به کاهش کارایی VM با توجه به Overhead ای که Metadata ها بر روی VM دارند و همچنین Overhead ای که فرآیند های نوشتن بر روی دیسک برای این ساختار ایجاد می کنند اشاره کرد از طرفی اگر ظرفیت VM شما به اندازه ای بالا برود که از Provision در نظر گرفته بیشتر شود باعث ایجاد Downtime و اشغال زیاد منابع VM خواهد شد.
از همه مهمتر اینکه شما اگر دیسک های مجازی خود را در حالت Thin Provisioned قرار دهید دیگر نمی تواند از امکانات Clustering در ساختار مجازی سازی خود استفاده کنید. زمانیکه VSphere یک دیسک Thin Provisioned ایجاد می کند فقط مقدار کمی Metadata در Datastore ذخیره می کند.
در این حالت هیچگونه فضایی بصورت یکباره از Datastore گرفته نمی شود ، زمانیکه فرآیند نوشتن بر روی دیسک انجام می شود ، VSphere ابتدا اطلاعات مربوط به Metadata ای که مربوط به فایل VMDK است را بروز می کند و در نهایت بلوک های جدیدی از داده را از Datastore دریافت و در آن اطلاعات را می نویسد. این عملیات در محل هایی که فرآیند های نوشتن و خواندن زیادی انجام می شود باعث بالا رفتن Overhead می شود.
Thin Provision ها دارای پایینترین کارایی از نظر سیستم در بین سه حالت و قالب دیسک هایی هستند که در VMware وجود دارد. البته در کنار همین معایب در محیط هایی که محدودیت استفاده از فضا دارند این نوع دیسک بسیار کاربردی است، دیسک های Thin Provisioned قابلیتی دارند که شما می توانید تا زمانیکه فضای واقعی دیسک شما پر نشده است از فضای مجازی موجود بر روی دیسک استفاده کنید.
برای مثال شما اگر 10 عدد VM داشته باشید که هر کدام از آنها به 50 گیگابایت فضا نیاز داشته باشند اما فضای Datastore شما تنها 100 گیگابایت باشد شما می توانید هر 10 عدد VM را با ظرفیت 50 گیگابایت ایجاد و راه اندازی کنید. در این حالت به یکباره فضا از Datastore دریافت نمی شود
و به مرور زمان با اضافه شدن حجم داده ها به VM ها تا مرز 100 گیگابایت شما می توانید از همه VM های خود همزمان استفاده کنید. اینکار باعث کاهش هزینه ها می شود ، برعکس Thick Provision که به یکباره با در نظر گرفتن فضا ، همه فضا را به یکباره از Datastore می گیرد.
روش دوم Thick Provision Lazy Zeroed
از مزایای ایجاد کردن Thick Provisioned Lazy Zeroed سرعت بیشتر ایجاد (Faster Provision) نسیت به Thick Provision Eager Zeroed است. این نوع دیسک های مجازی کارایی بهتری نسبت به Thin Provisioned دارند اما به نسبت سرعت ایجاد شدن آنها از Thin Provision کمتر است.
همچنین از دیگر معایب این نوع دیسک های مجازی کارایی و سرعت پایینتر نسبت به Thick Provisioned Eager Zero می باشد ، این نوع دیسک های مجازی همانند Thin Provisioned قابلیت Clustering از نوع FT را پشتیبانی نمی کنند اما کلاسترینگ از نوع HA را پشتیبانی می کنند.
زمانیکه VSphere یک دیسک از این نوع ایجاد می کند ، حداکثر اندازه ای که می تواند به فایل VMDK اختصاص دهد را به یکباره به آن می دهد اما دیگر هیچ کاری انجام نمی دهد. با دسترسی پیدا کردن به هر قسمت از بلاک های دیسک VSphere ابتدا بلاک را آماده و داده ها را در آن می نویسد.
سرعت و کارایی دیسک های مجازی که از نوع Thick Provisioned Lazy Zeroed هستند به دلیل ایجاد کردن Overhead در دیسک ها از Thick Provisioned Eager Zeroed کمتر است. بصورت خلاصه بعد از اینکه دیسک بصورت Lazy Zeroed ایجاد شد فضای متناسب با آن از Datastore گرفته می شود اما فضا پاکسازی نمی شود.
به محض اینکه شما بخواهید داده ای به این دیسک اضافه کنید فضا نیز ابتدا پاکسازی می شود و سپس داده های شما نوشته می شود که این به نوعی دوباره کاری برای VSphere ایجاد خواهد کرد.
پیشنهاد شرکت Vmware جهت راه اندازی پایگاه داده RDBMS اوراکل بر روی هایپروایزر ESXi در صورت استفاده از تکنولوژی VMware vSphere Storage APIs و تمایل به VMFS استفاده از این نوع دیسکThick Provision Lazy Zeroed است.
مزایای VMware vSphere Storage APIs
- افزایش سرعت کلون گیری با Hardware-accelerated (کلون گیری از بلاک ها به صورت Full Copy/XCOPY)
- قابلیت مدیریت بهینه سازی لاک ها (این همان Atomic Test and Set [ATS] است)
- صفر کردن نوشتن بلاک ها همانند صفر کردن فیزیکی دیسک ها
- قابلیت دوباره گرفتن فضای دیسک ها برای استفاده از بلاک هایی که دیگر نیازی به آنها نیست
- قابلیت پاک کردن بلاک ها برای استفاده از بلاک هایی که دیگر نیازی به آنها نیست
روش سوم Thick Provisioned Eager Zeroed
در این روش تمام فضای درخواستی با Overwrite شدن با 0 باعث کاهش ریسک های امنیتی بر روی این نوع دیسک های مجازی می شود.
با استفاده از این نوع دیسک شما می توانید از قابلیت های Clustering ای VMware Fault Tolerance استفاده کنید تنهای عیبی که می شود به این نوع دیسک گرفت زمان طولانی تر نسبت به سایر دیسک ها برای ایجاد شدن یا Provision Time بالاتر می باشد.
زمانیکه VSphere یک دیسک از نوع Provisioned Eager Zeroed ایجاد می کند ، حداکثر مقدار فضای ممکن برای دیسک را به یکباره به فایل VMDK اختصاص می دهد سپس تمامی فضاهایی که بر روی دیسک وجود دارند را صفر می کند. برای مثال اگر شما یک فایل VMDK را بصورت Thick Provisioned Eager Zeroed ایجاد کنید و 80 گیگابایت فضا برای آن در نظر بگیرید.
VSphere بلافاصله از دیسک شما 80 گیگابایت می گیرد و به فایل VMDK اختصاص می دهد و تمامی فضای 80 کیگابایت را با صفر پر می کند.زمانیکه تمامی فضاهای خالی با صفر پر شدند، Thick Provisioned Eager Zeroed مطمئن می شوند که در هنگام نوشتن اطلاعات داخل دیسک هیچگونه ریسک امنیتی به وقوع نمی پیوندد. Thick Provisioned Eager Zeroed Disk ها از بهترین کارایی در تمامی فایل های VMDK برخوردارند.
زمانیکه قرار است داده ای بر روی دیسک های Eager Zeroed انجام شود VSphere تنهای کاری که باید بکند نوشتن اطلاعات است و هیچ کار اضافی لازم نیست انجام شود ، همین امر باعث برتری این نوع دیسک نسبت به Thin Provisioned و Lazy Eager شده است.
پیشنهاد شرکت Vmware جهت راه اندازی پایگاه داده RDBMS اوراکل بر روی هایپروایزر ESXi در صورت عدم استفاده از تکنولوژی VMware vSphere Storage APIs و تمایل به VMFS استفاده از این نوع دیسک است.
|
نکته: در زمان راه اندازی Oracle RAC بر روی VMFS جهت شبیه سازی ذخیره سازی اشتراکی استفاده از Thick Provisioned Eager Zeroed الزامی است.
http://kb.vmware.com/kb/1034165
|