خلاصه تست اجرایی توسط شرکت Vmware
نتیجه گیری نهایی تست شرکت Vmware در مقایسه استفاده از VMFS یا RDM به شرح زیر مکتوب شده است:
- برای خواندن، نوشتن تصادفی (random) هر 2 تکنولوژی تقریبا نتایج مشابهی در عملیات های IO در ثانیه داشتند
- در خواندن، نوشتن ترتیبی (sequential) سرعت VMFS خیلی نزدیک به RDM بود (به غیر از مواردی که بلاک سایزها 4k در نظر گرفته شده بود). هر 2 تکنولوژی ها توان عملیاتی (throughput) بالایی رو داشتند به غیر از مورد نوشتن 300 مگابایت در ثانیه که VMFS به خوبی در آن عمل نکرد.
- در خواندن و نوشتن تصادفی (random) فایل سیستم VMFS نیازمند 5 درصد CPU بیشتر در هر cycle عملیات IO در مقایسه با RDM بود.
- در خواندن و نوشتن ترتیبی (sequential) فایل سیستم VMFS نیازمند 8 درصد CPU بیشتر در هر cycle عملیات IO در مقایسه با RDM بود.
جهت مطالعه کامل سناریو تست به داکیومنت زیر مراجعه گردد:
Performance Characterization of VMFS and RDM Using a SAN: ESX Server 3.5 (vmware.com)
محیط تست
مطالعه در محیط تست برای مقایسه VMFS و RDM در ESX Server 3.5 انجام شده است (آخرین مستند ارائه شده توسط شرکت VMware تا زمان نگارش مطلب) تست بر روی ماشین مجازی با یک سوکت با استفاده از ویندوز سرور 2003 نسخه EE SP2 به عنوان سیستم عامل ماشین مجازی انجام شده است. سرور ESX بر روی دیسک های لوکال SCSI پیکربندی شده است. 2 دیسک مجازی به ماشین مجازی متصل شده است یکی برای سیستم عامل و یکی برای محیط تست که بر روی آن عملیات های IO صورت می گیرد. لود ایجاد شده با استفاده از ابزار Iometer بوده که یک ابزار خیلی محبوب برای سنجش سرعت و کارایی IO سخت افزار است. لیست سخت افزارها و نرم افزارهای مورد استفاده در انتها آورده شده است.
برای تمام لود ها به غیر از تست لود 4K ترتیبی خواندن از کش پیشفرض با page size برابر 8K در لایه سخت افزار و raid controller استفاده شده است. در هر حال تست لود ترتیبی خواندن 4K با کش پیش فرض سرعت و کارایی خیلی پایینی هم در VMFS و هم در RDM دارد. شرکت EMC پیشنهاد می کند مقدار کش page size در ذخیره ساز (لایه کنترلر) برابر مقدا block size اپلیکیشن باشد (در این جا برای تست 4K باید کش را برابر 4K قرار دهیم.)
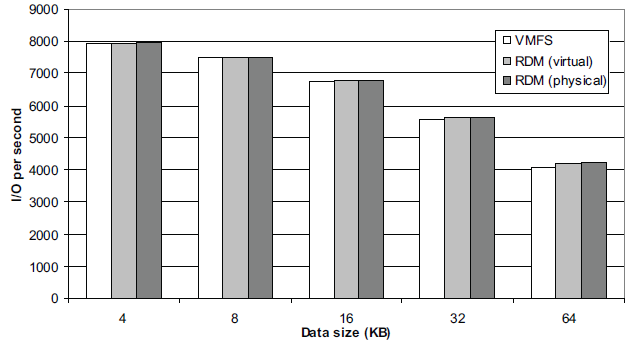
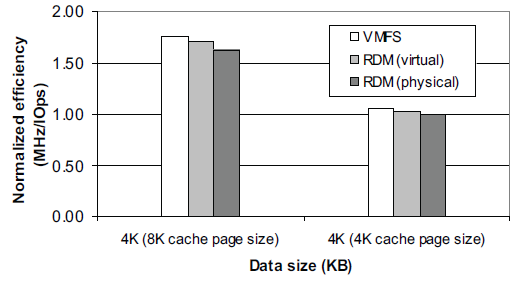
از این رو برای تست لود ترتیبی خواندن 4K با مقدار page size کش را برابر 4K میگذاریم. برای دیدن مقایسه در زمانی که مقدار کش برابر 4K و وقتی برابر 8K قرار داده شده است نمودارهای زیر را ملاحظه کنید.
مقایسه تست لود ترتیبی خواندن در هر ثانیه در زمان قراردادن مقدار 4K برای اپلیکیشن و قراردادن page size برابر مقدار پیش فرض و مقدار 4K (بالا بودن نمودار کارایی بهتری را نشان می دهد)

هزینه استفاده از CPU برای تست ترتیبی خواندن بلاک های 4K با بلاک های کش متفاوت (پایین بودن نمودار کارایی بیشتری را نشان می دهد)
لایه دیسک
در این مطالعه پیکربندی لایه دیسک و نحوه قرار گیری آن ها به دقت انتخاب شده است. ما سرور را به صورت مستقیم با فیبر نوری و HBA به یک دستگاه SAN با مدل CLARiiON CX3‐40 متصل کردیم. ما 2 گروه RAID 0 بر روی SAN ایجاد کردیم یکی دارای 15 دیسک و دیگری دارای 10 دیسک. ما یک LUN با حجم 10 GB بر روی هر گروه RAID ایجاد کردیم. بعد یک metaLUN با حجم 20GB با استفاده از این 2 LUN 10GB ای پیکربندی شده است.
ما از این metaLUN جهت دیسک تست استفاده می کنیم. (metaLUN امکان بهم پیوستن (Aggregate) جهت افزایش سایز و سرعت را نسبت به LUN اصلی، فراهم می آورد.) دیسک های استفاده شده برای این تست تنها برای این تست لود I/O مورد استفاده قرار گرفته اند. ما یک دیسک مجازی بر روی دیسک های تست ایجاد کردیم و اون رو برای ماشین مجازی ویندوز مورد استفاده قرار دادیم. به دلیل استفاده از زیرساخت ESX و ایجاد datastore ماشین مجازی از نوع و نحوه چینش این دیسک ها اطلاعی ندارد و اون رو به عنوان یک دیسک فیزیکی شناسایی می کند.
شکل زیر پیکربندی دیسک مورد استفاده را نمایش می دهد. در تست VMFS ما از یک دیسک مجازی با فرمت VMDK برای ذخیره سازی به عنوان پارتیشن VMFS به عنوان دیسک تست استفاده کردیم. ولی در تست RDM ما یک فایل پیکربندی RDM برای ماشین مجازی ایجاد کردیم و مپ این فایل را به دیسک تست انجام دادیم. ما پیکربندی دیسک مجازی محیط تست رو با یک LSI SCSI HBA انجام دادیم.
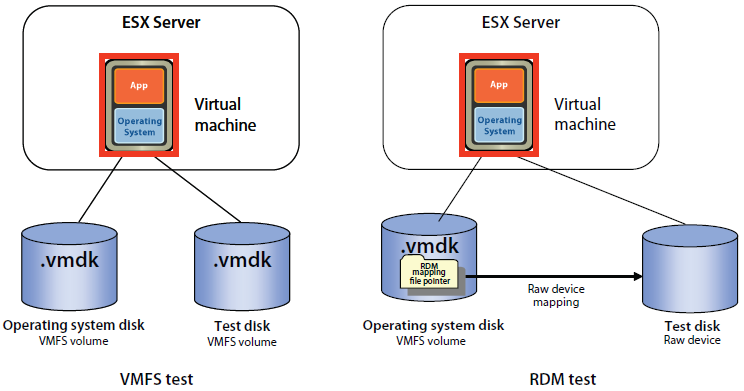
خوشبختانه ابزار Iometer قابلیت این را دارد که بدون ساخت پارتشین و فایل سیستم در سیست عامل بر روی یک raw دیسک تست خواندن، نوشتن را نیز انجام دهد. پس ما بدون استفاده از فایل سیستم و فرمت این فضاها تست لود کار را انجام دادیم.
پیکربندی
ما پیکربندی سیستم عامل مهمان را با استفاده از درایور و کنترلر LSI Logic SCSI انجام دادیم.در حالت استفاده از VMFS ما یک دیسک مجازی به صورت Thick Provisioned Eager Zeroed که به عنوان راهکار برتر به جهت استفاده از فضا برای دیتا در VMFS است ساختیم.
در پیکربندی ماشین مجازی تمام پارامترها از حالت پیش فرض خود تبعی کرده اند، مگر پارامترهایی که خلاف آن ها این مستند بیان شده باشد.
ما در هر test case قبل از شروع به انجام آزمایش با استفاده از برنامه های خط فرمان تمام مقادیر دیسک مجازی را 0 کردیم. (VMkfstools با آپشن w)
مشخصات لود I/O
اپلیکیشن های سازمانی (Enterprise) به طور معمول و عمومی لود I/O با پترن های متفاوت تولید می کنند. پس ندازه blockهای انتقال داده شده در سرور هاست اپلیکیشن و ذخیره ساز ممکن است به طور متناوب تغییر یابد. نحوه طراحی و شیوه چینش دیسک ها و لایه فایل سیستم برای دسترسی به سرعت و کارایی بالا در لودهای کاری بسیار بسیار مهم است.
اپلیکیشن های کمی هستند که یک پترن دسترسی مشخص برای سایز block ها دارند. یک مثال برنامه های بک آپ هستند که از یک پترن برای خواندن ترتیبی بلاک ها استفاده می کنند. دیتابیس های OLTP برخلاف این اپلیکیشنها اکثرا بسیار random کار میکنند. به صورت طبیعی اپلیکیشنها بر روزی اندازه blockهای در حال انتقال تاثیر می گذارند.
Test Caseها
در این مطالعه، مشخصات لود سرعت و کارایی برای 2 تکنولوژی VMFS و RDM برای یک رنج از بلاک ها با پترن های متفاوت را مشخص می کنیم. سایز بلاک های انتقال داده شده بین 4KB, 8KB, 16KB, 32KB و 64KB انتخاب شده اند. پترن دسترسی مشخص شده توسط ما به صورت تصادفی عملیات خواندن و نوشتن و به صورت ترتیبی عملیات خواندن و نوشتن یا ترکیبی از خواندن و نوشتن را انجام می دهد.

ایجاد لود آزمایشی
ما از Iometer که یک benchmarking tool معروف و محبوب است و به طور گسترده برای سخت افزارهای Intel جهت تست های سرعت و کارایی(performance) استفاده می گردد، برای ایجاد لود آزمایشی استفاده کردیم. Iometer توانایی تهیه و اجرای انواع تست های طراحی شده I/O را دارد. به این دلیل که ما طراحی یک تست مشخص برای سنجش سرعت و کارایی دیسک ماشین مجازی در یک دیوایس خام (raw) و VMFS را داریم از شبیه ساز لود basix برای تست های زیر استفاده می کنیم:
- ابزار Iometer با مقادیر زیر جهت تست پیکربندی شده است:
- انتقال بلاک ها با سایز: 4KB, 8KB, 16KB, 32KB و 64KB
- درصد توزیع تصادفی یا ترتیبی برای هر سایز بلاک از 0 درصد تا 100 درصد توزیع
- درصد توزیع میزان خواندن و نوشتن برای هر درخواست I/O از 0 درصد تا 100 درصد توزیع و یا حتی 50 درصد توزیع برای خواندن و 50 درصد توزیع برای نوشتن
- پارامترهای زیر برای تمام حالات test case ثابت است:
- تعداد عملیات های I/O ورودی و خروجی: 64
- زمان اجرا: 5 دقیقه
- زمان افزایش شیب: 60 ثانیه
- تعداد workerهای خودکار: 1
نتایج تست سرعت و کارایی
در این بخش نتایج آنالیز تست سرعت و کارایی بر روی ماشین مجازی با یک پردازنده منتشر شده است:
معیارها
معیارهای مورد استفاده برای مقایسه بین VMFS و RDM برای I/O براساس تعداد عملیات ها در هر ثانیه، مقدار توان عملیاتی (برحسب MB بر ثانیه)، و هزینه CPU بر حسب MHz بر ثانیه است.
در این مطالعه ما گزارش معیارهای I/O را توسط معیارهای گفته شده با ابزار Iometer انجام دایدم و مقایسه را در هر بخش برای VMFS و RDM انجام دادیم. این معیارها با هزینه CPU برای هر واحد I/O با استفاده از فرمول زیر محاسبه شده اند:

تمام وضعیت های I/O و CPU جمع آوری شده توسط 2 نرم افزار Iometer و esxtop بوده اند:
- Iometer – جمع آوری عملیات های I/O در هر ثانیه و مقدار توان عملیاتی در MB بر ثانیه
- Esxtop – جمع آوری میانگین مصرف CPU از طریق محاسبه میزان CPU استفاده شده در ماشین مجازی در CPU فیزیکی
سرعت و کارایی
این بخش مقایسه سرعت و کارایی با مشخصات توضیح داده شده برای Test case را مورد ارزیابی قرار می دهد.