تو این پست میخوایم نگاهی دوباره بر معماری اوراکل از روی اسلایدهای دانشگاه اوراکل بندازیم.
![]() دریافت
دریافت
حجم: 558 کیلوبایت
توضیحات: Less01_Architecture
![]() دریافت
دریافت
حجم: 23 مگابایت
توضیحات: تمام اسلایدهای اوراکل ورکشاپ ۱ به همراه اسکریپتها
نگاهی بر معماری Oracle Database 11g - قسمت اول
نگاهی بر معماری Oracle Database 11g - قسمت دوم
نگاهی بر معماری Oracle Database 11g - قسمت سوم
یادتون باشه اگه معماری اوراکل رو خوب ندونید برای tuning اون نمیتونید مانور زیادی انجام بدید. پس اول باید معماری رو خوب بلد باشیم که چه اتفاقهایی تو سیستم میوفته بعد برای tun کردن دیتابیس اقدام کنیم.


خب تو این اسلاید میخوایم نگاهی به کامپوننتهای اصلی دیتابیس بندازیم و اونها رو بشناسیم
- وقتی دیتابیس بالا میاد چه اتفاقی براش میوفته
- ساختار memory در دیتابیس چجوریه
- background process ها چیها هستن
- physical و logical در ساختار storage به چه شکل هستش
- و توضیحاتی درباره ASM

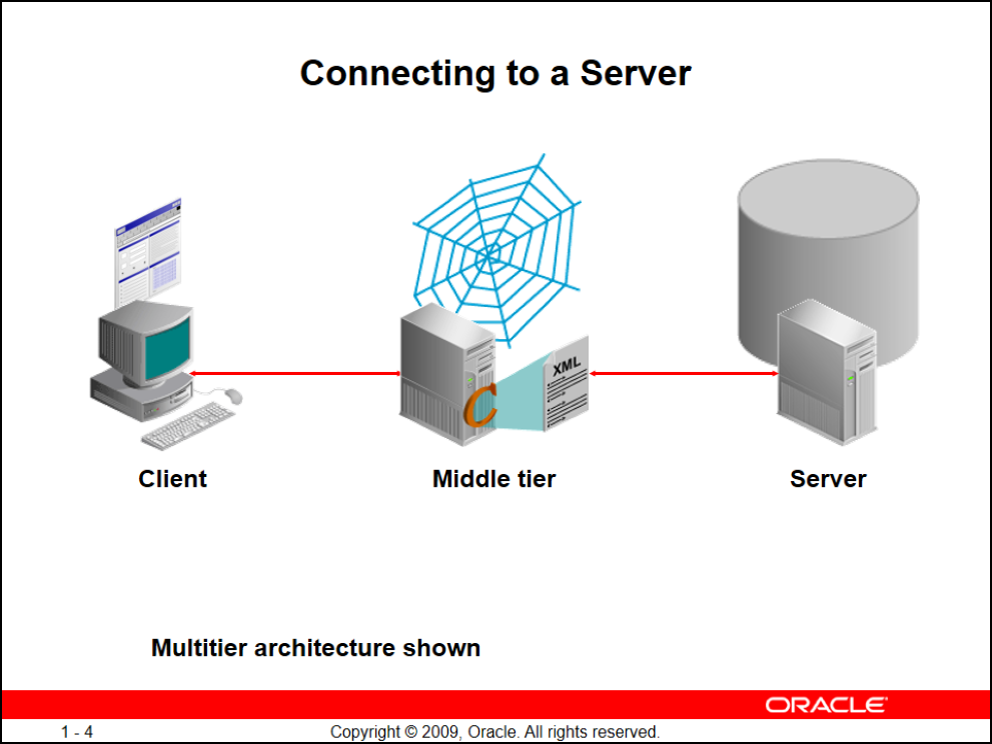
اولین چیزی که باید یاد بگیریم اینه که کلاینت ما میتونه laptop / server / pc و ... باشه
خب ما میخوایم به دیتابیسمون وصل بشیم پس معماری ما میتونه ۲ لایه یا ۳ لایه باشه:
- Client -> Middle Tier -> Server
- Client -> Server
معماری ۲ لایه:
فرض کنید اپلیکیشن دسکتاپی نوشتید که روی ماشین کلاینتتون باید نصب بشه (سیستمعامل کلاینتتون میتونه هرچیزی باشه)، سرور شما هم میتونه هر چیزی باشه (از لحاظ سختافزار و سیستمعامل)
حالت fat: thin
این دسته از برنامهها سمت کلاینت چاقاند یعنی کلاینت باید خوب باشه (RAM و CPU قوی داشته باشه)
مثلا اگه با اپلیکیشنهای مالی و حقوق دست مزد همکاران سیستم یا رایورز کار کرده باشید این اپلیکیشنها به طور کامل روی کلاینت نصب میشن و اصلاً براشون سمت دیتابیس مهم نیست (میتونه access, sql server, oracle, ...) باشه (اصطلاحاً سمت دیتابیس thinه یعنی از منباع کمی برخورداره)
معماری ۳ لایه:
تو این حالت شما یک کلاینت دارید و یک سرور هم وسط ارتباطت کلاینت و دیتابیس
تمام اپلیکیشنهایی که به صورت وب ازشون استفاده میکنید عموماً ۳ لایه هستند
تو این حالت یک سرور جدا برای دیتابیس در نظر گرفته میشود و یک سرور جدا برای moddle tier اتون (مثل tomcat, weblogic, jboss, oracle application server, IIS, ...)
بعد از جداسازی این ۲ سرور شما اصطلاحاً برنامهتون رو روی این وباپلیکیشنتون deploy میکنید تو این حالت به هیچ عنوان خود کلاینت نمیتونه مستقیماً به دیتابیس وصل بشه همچنین از لحاظ امنیتی میتونید این وباپلیکیشنتون رو DNZ کنید و اصلا ip ها رو local بدید یا میتونید proxy ران کنید
حالت thin: fat
تو این حالت اگه برنامه دسکتاپی باشه بسیار سبکه و تو بیشتر موافع با جاوا نوشته میشه همچنین میتونه به صورت web ای هم باشه پس کلاینت شما thinه سمت دیتابیس و وباپلیکیشن شما هم میتونه هر چیزی باشه ولی به سختافزاری قوی نیاز داره پس fatه
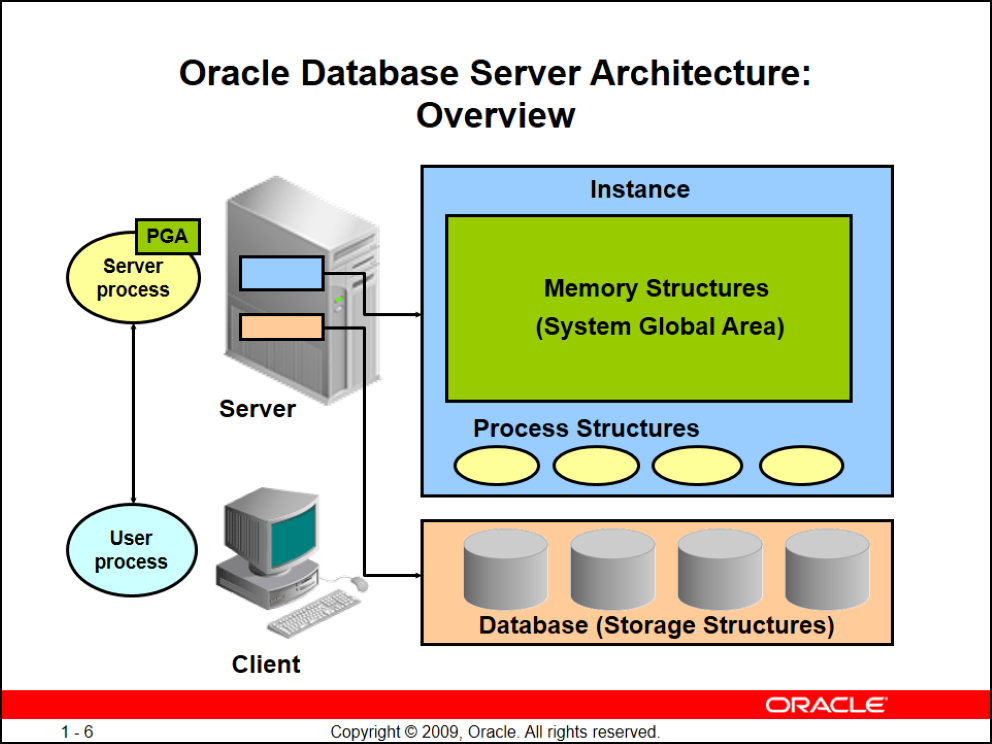
بخشهای مختلف دیتابیس اوراکل
بخش اول) Instance: قسمتی از اطلاعات میاد درون ram قرار میگیره instance (نمونه) نام داره
که این instance از ۲ قسمت تشکیل شده:
- SGA
- Process Structure
Process Structure
اوراکل یکسری process داره که در حقیقت ارتباطات و پردازش کارهای شما رو برعهده میگیرن
بخش دوم) (Database(Storage Stuctures: فایلها و اطلاعاتی که روی disk نشستهاند که بهش Storage Stuctures یا ساختارهای دیتابیس میگن
بخش سوم) Server process: وقتی میخواین از یک کلاینت به دیتابیس وصل بشین (مثلا با ابزارهای: sqlplus, plsqldeveloper, toad, sql developer, ...) بعد از auth شدن و برقراری کانکشن بین شما و دیتابیس
اوراکل برای اون کاربری که وصل شده یک server process سمت سرور بالا میاره (پس به ازای هر کانکشن و کاربر یک server process بالا میاد) هر Server process ای یک PGA هم ایجاد میکنه
بخش چهارم) User process: دقیقاً این همون اپلیکیشنیه که استفاده میکنید (sqlplus, plsqldeveloper, toad, sql developer, ...)
بخش پنجم) ارتباط بین User process و Server process: این ارتباط همون Session شماست
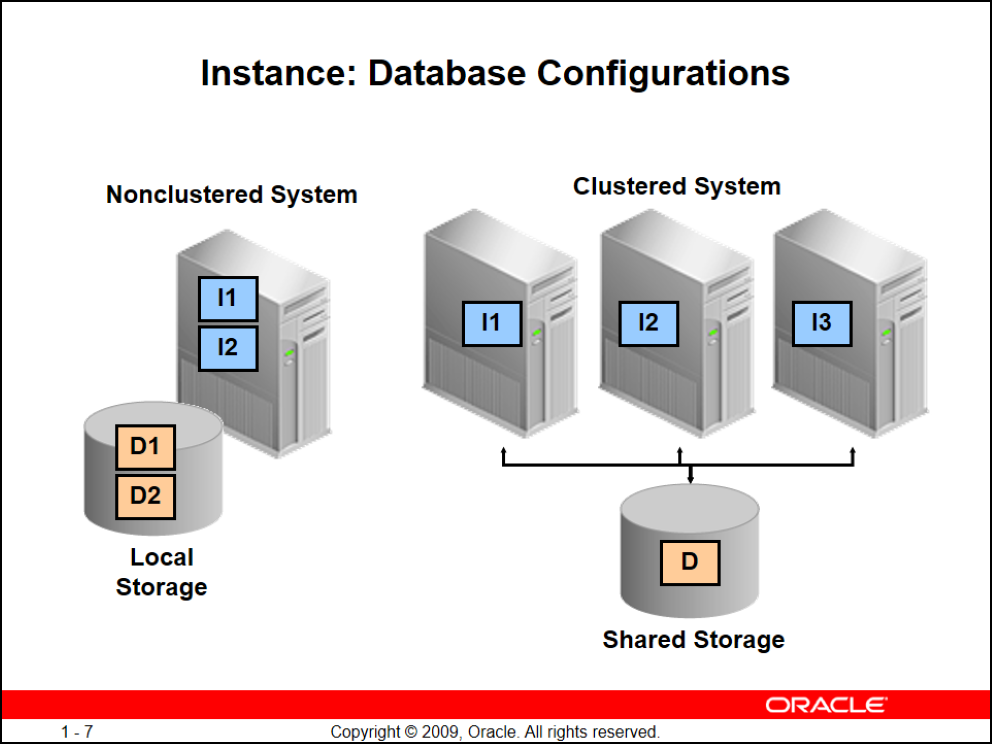
(Single Instance(Nonclustered System
دیتابیس شما ممکنه فقط یکی باشه به این معنی که ممکنه شما یک سرور داشته باشید و دیتابیس رو روش بالا آورده باشید. روی دیتابیستون میتونید instance1,2,..,n داشته باشید
نکته: شدیدا توصیه میکنم بیش از ۱ نمونه (instance) روی یک دیتابیس برای کار عملیاتی بالا نیارید. مگر اینکه از لحاظ بودجه و سرور محدو باشید اونوقت توصیه میشه حداکثر ۲ نمونه(instance) روی دیتابیستون بالا بیارید(اولی برای محصول و به صورت عملی و دومی برای تست) خب هر Instance ای storage, disk خودش رو داره و بهتره از یک disk برای ۲ instance استفاده نکنید (حتما هم دقت کنید مسیر فایلها جدا باشه)
(Clustered System(RAC
بهتره اول مفهموم کلاستر رو باهم مرور کنیم
وقتی چندتا سرور رو به هم دیگه وصل میکنیم و نمیخوایم اون کسی که به دیتابیس وصل میشه کاری داشته باشه که به کدوم سرور وصل میشه
به نظرتون چه زمانی باید به سمت کلاستر بریم؟
این دقیقاً بستگی به نوع پروژه داره یعنی ممکنه یک پروژه انقدر حساس باشه که حتی نیم ساعت قطعی هم براش قابل قبول نباشه
پس اگه شما ۱ سرور داشته باشید و سختافزارهای سرور به هر دلیلی خراب بشن و سرور down بشه تعمیر خرابی سرور ممکنه زمان زیادی رو ازتون بگیره ما با RAC میخوایم down time رو کم کنیم
۱) SLA
فرض کنید شما پیمانکارید و میخواین به کارفرمایی solution بدید شما باید قبل از هر کاری یک (SLA(Service-level agreement ببندید شما توی SLA شرح خدمات خودتون رو تو مادهها و بندها ارائه میدید همچنین توی بخشی از SLA شما میاین و میگین من ۹۹.۰۵ درصد uptime میدم حواستون باشه الکی عدد ندید و به ممیزها توجه کنید مثلا اگه عدد شما بشه ۹۹.۹۵ درصد میلیونها تومن به هزینههای شما اضافه میشه
مثلاً:
۳۶۵ روز * ۲۴ ساعت * ۶۰ دقیقه = ۹۱۴۴۰۰ دقیقه => این کل دقیقههای شما توی ساله پس اگه میگید ۹۹.۹۵ درصد فقط 0.05 درصد از این دقیقهها رو میتونید(plan or unplan) downtime بدید (حدود 7 ساعت در سال)
downtime plan => یعنی شما از قبل با کارفرما هماهنگ کردید و برای این خاموشی برنامه دارید
downtime unplan => یعنی شما برای این خاموشی از قبل برنامه نداشتید (مثل رفتن برق که باید ژنراتور و UPS تهیه کنید)
پس تو محاسباتمون برای پروژه اگه بیش از مقدار تعیین شده downtime داشتیم مجبوریم سرورهامون رو کلاستر راه بندازیم
توی RAC برای این که بشه به دیتابیس از هر node دسترسی داشت مجبوریم باید یک sharedisk درست کنیم و دیتابیس رو روی اون نصب کنیم.
برای این کار باید قبل از نصب دیتابیس Grid رو روی همهی سرورها نصب کنیم اما با این تفاوت که کافیه grid رو روی یک سرور node نصب کنیم تا خود grid خودکار رو همهی nodeها بیاد نصب رو انجام بده
بعد از نصب grid رو همهی nodeها باید دیتابیس رو نصب کنید
برای shared storage هم باید یک SAN Storage داشته باشیبم که به سرورهامون وصل کنیم
SAN Storageها هم ۲ نوعاند
- فیبرنوری
- اترنت
یادتون باشه SAN Storage رو نمیشه مستقیماً به چندتا سرور وصل کرد و حتماً باید از یک SAN Switch استفاده کرد
نکته: اگه از چند SANSwitchاستفاده کنید redundant بهتری دارید
همچنین هر سرور نیاز به یک کارت HBA(host bus adapter) داره که بهتره همهی سرورها از یک برند کارتشون تهیه بشه(emulex, qlogic , ...)
شما میتونید از NAS هم استفاده کنید ولی چون NAS فقط خروجی شبکه داره و حداکثر سرعت شبکه ۱ گیگه پس نمیتونه گزینه خیلی مناسبی باشه
۲ نوع فیبرنوری داریم:
- Multimode
- Singlemode
اگر فاصلتون زیاده یعنی بیشتر از ۱۰۰ کلیومتره حتما باید از singlemode استفاده کنید ولی اگه توی اتاق سرور هستید و میخواین سرورها رو به هم وصل کنید باید multimode انتخاب کنید که پهنای باند بیشتری داره این ۲ نوع کابل از لحاظ ظاهری هیچ فرقی باهم ندارند.
وقتی ما RAC راه میندازیم درحقیقت زمان downtime رو کم کردیم البته ممکنه کندی ایجاد بشه اما سرویسمون هنوز بالاست
۲) رشد پروژه
فرض کنید به هر دلیلی تعداد کاربران پروژه شما به ۳ برابر معمول خودش برسه تو این حالت اگه شما کلاستر نکرده باشید باید RAM, CPU به سرورتون اضافه کنید. حالا اگه سرورتون جا داشته باشه میتونید اینکارو کنید ولی اگه سرورتون دیگه قابل ارتقا نباشه مجبورید سختافزار عوض کنید
پس تو پروژههایی که از روز اول رشدشون معلومه بهتره از اول کلاستر ببندید حتی کلاستر با ۱ نود و بعداً هر موقع نیاز داشتید node اضافه میکنید
نکته: یادتون باشه نیازی نیست تو کلاستر کردن نوع سختافزارتون یکی باشه هر سرور میتونه resourceهای مختلف از برندها و مدلهای
مختلف باشه
نگاهی به انواع مدلهای SAN Storageها
- HP MSA 2040 SAN Storage
- HP P2000 G3 MSA Array Systems
- HP EVA P6000 Storage
یادتون باشه برای محیطهای enterprice سراغ HP نرید و best practice اینه که از emc یا hitachi استفاده کنید
برای اطلاعات بیشتر به مطلب زیر مراجعه کنید:
مروری اجمالی بر سختافزاریهای مورد نیاز کلاستر - قسمت اول
مشکلات RAC
- نگهداری مشکل
- نیاز به دانش بالا
نگاهی بر ASM
Automatic Storage Management
شما وقتی به سمت کلاستر میرید best practice اینه که از ASM استفاده کنید
ASM به ۲ صورت موجوده:
- Single
- Cluster
Single: وقتی از لحاظ RAM, CPU سرور کافیه و میخواین Storageاتون زیاد باشه (مثلا ۱۰۰ ترا دیتا دارید) و اصلاً هم نمیخواین کلاستر راه بندازین نیاز دارید ASM رو به صورت Single راه بندازید
یادتون باشه ASM حتماً نیاز به راهاندازی Grid رو قبلش داره پس در نهایت شما از SAN یک فضا میگیرید و روش grid, asm , databaseاتون رو نصب میکنید
نکته: اگه دیسکتون crach کرد باید ۲ تا دیسک از ۲ تا SAN Storage بگیرید، همچنین best practice اینه که failover رو روی ASM هم راه بندازید.
نکته: برای جلوگیری از مشکلات crach کردن هر ۲ دیسک best practice اینه که Data Guard راه بندازید. (راهاندازی سابیت mirror)
نکته: برای جلوگیری از خرابی دیتا باید حتماً پلن برای تهیه Backup داشته باشید.
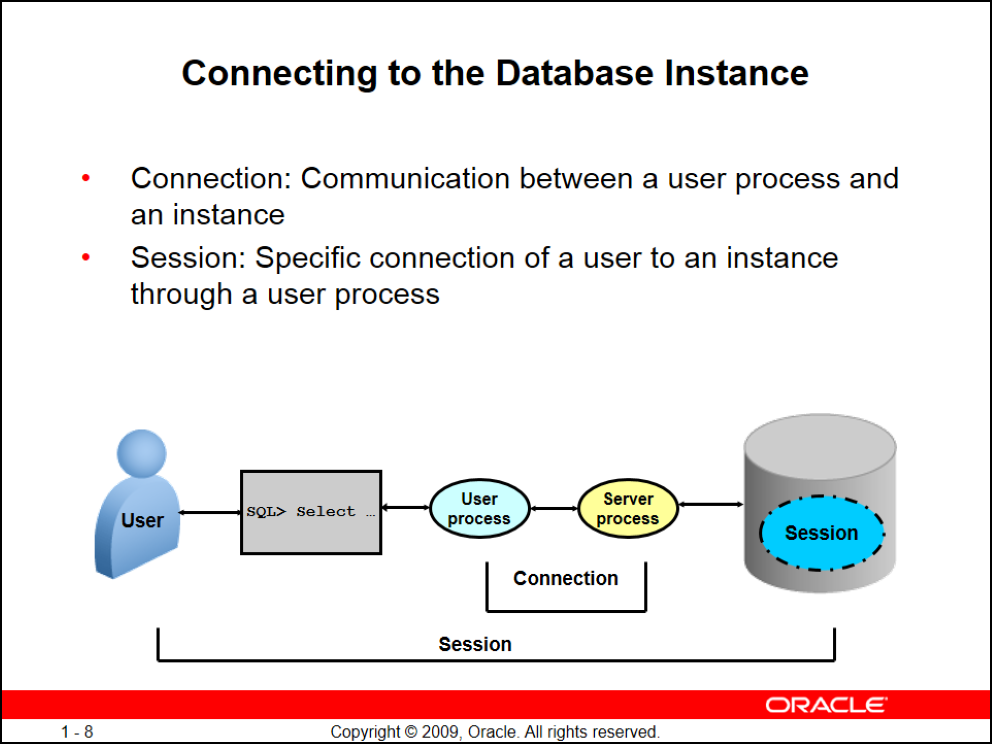
مفهوم کانکشن
وقتی کاربر کانکشن میزنه و کوئری رو اجرا میکنه یک User process سمت کلاینت به وجود میاد و یک Server process سمت دیتابیس همونطور که تو شکل بالا میبینید بین User process, Server process یک Connection به وجود میاد
بعد بین کاربر و دیتابیس یک Session ایجاد میشه (مثلا اگه ۵ بار روی یک کلاینت sqldeveloper رو باز کنید و Connection ایجاد کنیم ۵ تا Session
ایجاد شده یا اگه با یک sqldeveloper با ۵ کانکشن وصل بشیم بازم ۵ تا Session ایجاد کردیم)
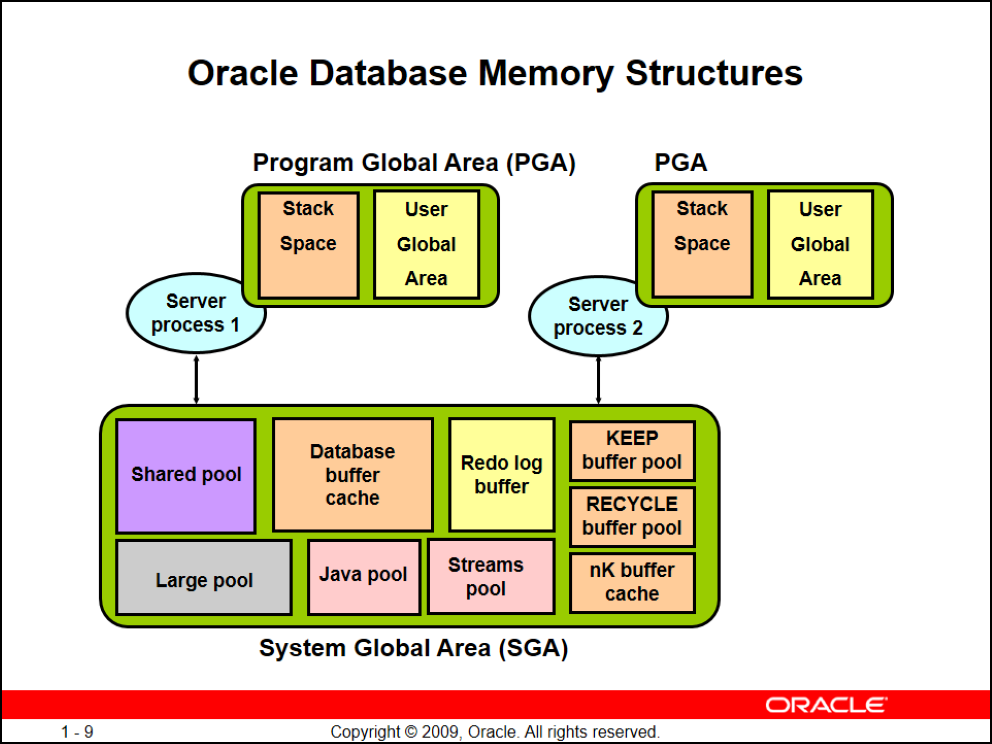
همونطور که گفتیم هر کاربری که connection برقرار کنه یک Server procees, PGA سمت سرور میسازه
ساختار SGA
- Shared pool (اصلی)
- Database buffer cache (اصلی)
- Redo log buffer (اصلی)
- Large pool (اختیاری)
- Java pool (اختیاری)
- Streams pool (اختیاری)
- KEEP buffer pool
- RECYCLE buffer pool
- nK buffer cache
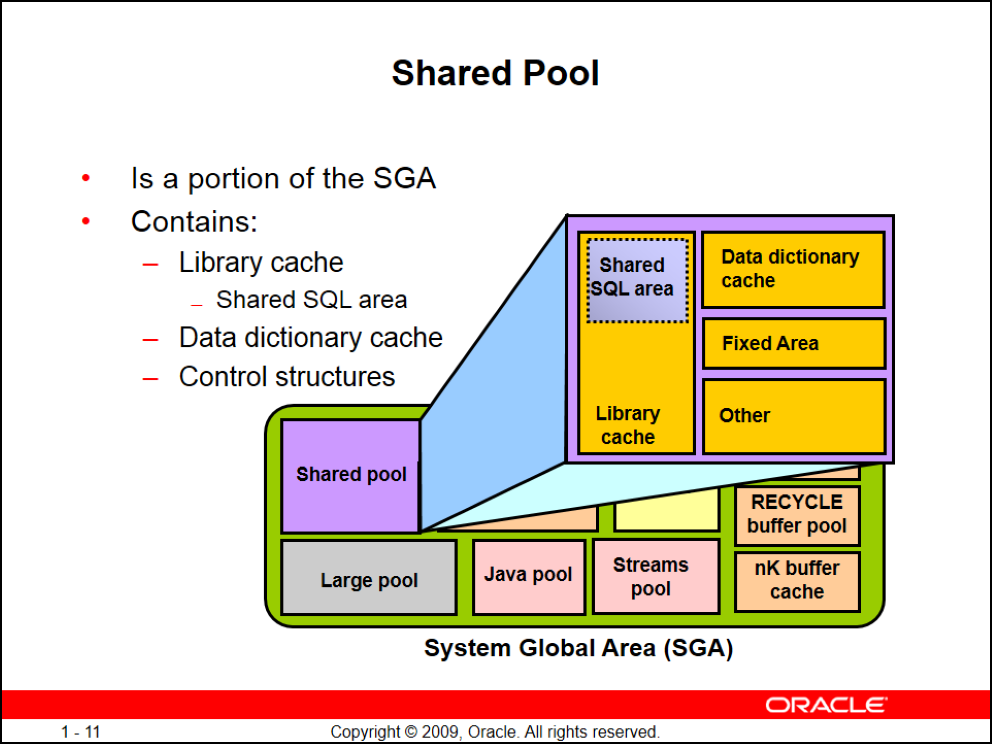
Shared Pool
خودش به چند قسمت تشکیل میشه
- Library cache
- Data dictionary cache
- Fixed Area
- Shared SQL area
معماری اوراکل
همونطور که گفتم بین user process و server process برای هر session یک connection ایجاد میشه
user process اپلیکیشن شما کل کوئری کاربر رو به سمت server process میفرسته و اولین کاری که میکنه parse اش میکنه
تو مراحل parse
اول) syntax check انجام میشه
Data dictionary cache
دوم) اوراکل میاد جداول رو چک میکنه پس باید select از data dictionary بزنه
- metadata = اطلاعاتی درباره ماهیت دیتا مثل: سایز، تاریخ ایجاد، اسم، مالک و ... (در کل هر سوالی راجع به دیتا)
- data = محتوای تولید شده
تمام metadataها تو اوراکل توی data dictionary قرار میگیرن
برای data dictionary دیگه IO انجام نمیشه و همهی metadataی لازم موقع بالا اومدن اوراکل توی Data dictionary cache قرار میگیره
پس اوراکل تمام recursive select ها رو که برای parse نیازشون داره رو از این cache میگیره
سوم) کل دستور توسط engine sql کامپایل و بعد hash میشه
Library cache
چهارم) رشتهی hash شده رو توی Library cache قرار میده
پنجم) قبل از اجرای دستور چک کردن permissionها (کاربر مورد نظر اصلاً میتونه این کوئری رو بزنه یا نه)
نکته: پس اگه کاربر دیگهای بیاد یا مجدداً این select توسط همین کاربر اجرا بشه اوراکل اول میاد hash شده این کوئری رو با رشتههای موجود در Library cache چک میکنه اگه موجود بود پس دیگه نیازی به کامپایل دستور نداره
نکته: یکی از وظایف ادمین اینه که به برنامهنویسها بگه که از bind variable در کوئریها استفاده کنند و به صورت fix کوئریها رو نزنه، این قضیه بر اساس زبان برنامهنویسی شماست مثلا در محیط sqlplus از & استفاده میکنیم تا از کاربر ورودی بگیره پس چون ورودی میگیره hash کوئری ثابت میمونه و عوض نمیشه فقط ورودیها فرق میکنن (تو جاوا variable:)
library cache براساس الگوریتم LRU کار میکنه (یعنی آخرین باری که استفاده شده) و میاد برحسب یک زمانی کوئریهای کش شده رو چک میکنه اینکار برای این انجام میشه که اگه کاربری بیاد و یک کوئری دیگهای اجرا کنه و library cache پر باشه نمیتونه hash رو نگه داره پس اگه یک کوئری به مدت طولانی استفاده نشه از library cache دور انداخته میشه
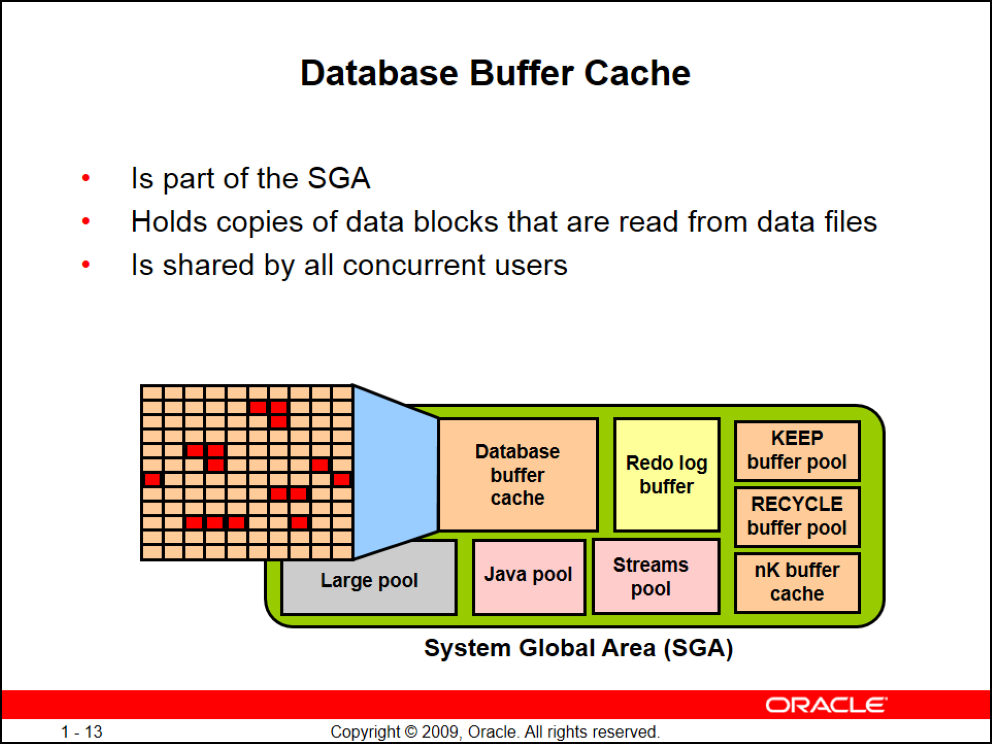
Database Buffer Cache
وقتی شما کوئری میزنید اورکل قبل از IO زدن فضای Database Buffer Cache رو نگاه میکنه که شاید از قبل دیتای درخواستی شما cache شده باشه اگه دیتا موجود نباشه اوراکل میره سراغ disk و data fileها
نحوه خوندن از دیسک هم همیشه با rowidه پس اوارکل برای پیدا کردن دیتای شما روی دیسک یا باید full table scan کنه یا اگه index داشته باشید و optimizer صلاح بداند rowid را از index بخونه
rowid = آدرس فیزیکی رکورده
بعد از به دست آوردن rowid اوارکل سراغ اون آدرس میره و بلاک مربوطه رو میخونه
بلاک سایزهای اوراکل معمولاً مضربی از بلاک سایزهای سیستمعامل هستند
(هر بلاک در سیستمعامل به مقدار فضای پیشفرضی که برای ذخیرهسازی بیتها و بایتها از مدیای ذخیرهسازی گرفته میشود گویند)
physical read
وقتی اوراکل به data dictionary cache نگاه کرد و دید دیتا رو نداشت server process این session مجبوره بره از روی دیسک IO بزنه و بلاک رو بخونه
حالا اگه به فرض هر بلاک ما 8k باشه و اطلاعات درخواستیمون اطلاعات کارمندها باشه که نهایتاً هر رکورد برامون 0.5k دربیاد توی این 8k تقریباً ۱۰ تا رکورد جا میشه (باقی فضا به header اختصاص داره)
پس وقتی این بلاک خونده میشه ۱۰ رکورد از دیسک میاد بیرون و این بلاک توی database buffer cache قرار میگیره
اینجاست که باید database buffer cache ذو دقیقاً براساس بلاکهای disk بذاریم
(پس اگه disk رو موقع نصب 8k گذاشتید حتما باید database buffer cache رو هم 8k بذارید)
logical read
وقتی اتفاق میافته که بلاک شما وارد database buffer cache شده باشه و حالا اوراکل میخواد دقیقاً همون رکورد شما رو بهتون بده پس دنبال رکوردتون میگرده و اون رو برمیگردونه
نکته: در مواقعی دیدم که physical read به سرعت بلاک رو آورده ولی تو logical read زمان زیادی wait میخوره پس باید نسبت رو دربیارید
نکته: وقتی یک کاربر دیگه دقیقاً همین کوئری رو اجرا کنه از همین hash موجود در library cache استفاده میکنه و درنهایت explaiin plan(نقشه راه) درست میشه
optimizer اوراکل برای این که بهترین plan رو بچینه میاد از sql profile که توش شامل اطلاعات به روز برای sql ما براساس دیتا و سختافزارمونه استفاده میکنه و تو بازههای مختلف زمانی با jobهایی میاد این sql profile رو میسازه -> اوارکل وقتی sql profile داره دیگه مسیر رو برای sql شما از اول درست نمیکنه چون مسیر رو داره
Result Cache
وقتی یک کاربر دیگه دقیقاً همین کوئری رو بزنه اوراکل میاد دوباره logical read میکنه پس اگه ۲۰ بار همین کوئری اجرا بشه ۲۰ بار باید logical read داشته باشیم پس برای اینکه logical readها رو کم کنیم اوراکل دقیقاً همون رکوردی که برای بارها درخواست شده رو میاد میذاره تو result cache که توی shared pool قرار داره پس اینجوری logical read های تکراری نداریم
objectها در اوارکل
هر کاربر میتونه یکسری object داشته باشه objectها شامله:
- table
- view
- index
- synonym
- sequnce
نکته: هر کاربری که حداقل یک object داشته باشد در اوراکل یک schema خوانده میشود.
شما ممکنه بخواین با کاربری به دیتابیس login کنید که خودش هیچ object ای نداره اما میخواد بره از جدول کاربر دیگهای select بزنه پس باید مجوزهای کاربران موقع کوئری زدن چک شود
سناریوی update
کاربر آپدیت رو میفرسته
server process مراحل رو انجام میده و کامپایل انجام میشه
به database buffer cache نگاه میکنه که آیا دیتا داخل بلاکهای RAM موجوده یا نه
اگه نبود باید server process بره IO بزنه
پس update پشت صحنه select میزنه
بعد از قراردادن دیتا توی database buffer cache
باید دیتا تغییر کنه و تغییر توی database buffer cache انجام میشه نه disk اینجا ۲ حالت پیش میاد:
- commit
- rollback
قبل از آپدیت اوراکل database buffer cache رو توی دیتافایل undo segment مینویسه
پس بعد از آپدیت رکورد توی database buffer cache آپدیت میشه و رکورد lock میشه که کاربر دیگهای این رکورد رو آپدیت نکنه تا تکلیف آپدیت این کاربر مشخص بشه user wait میشه (اگه این کارو نکنه ممکنه یک کاربر بخواد رکوردی رو ویرایش کنه و همون لحظه کاربر دیگهای اسم فیلدهای جدول رو عوض کنه پس تداخل پیش میاد)
شما میتونید با select for update کوئریهاتون رو بزنید و try/catch کنید
رکورد زمانی از lock خارج میشه که یا کاربر commit کنه یا rollback
اگه کاربر commit کنه همچنان اوراکل دیتای تغییر یافته جدید رو نمیبره تو disk و کار رو به تعویق میندازه چون:
- شاید کس دیگهای بخواد این اطلاعات رو بخونه یا تغییر بده که اطلاعات به سرعت قابل تغییر باشند
- اوارکل نیاز به پیدا کردن rowid بلاک اون رکورد داره که بدونه این آپدیت کجا روی چه بلاکی باید انجام بشه
حال اوراکل rowid رکورد رو داره و میخواد دیتا رو آپدیت کنه اگه بیاد ببینه که سایز بلاک فیلد آپدیت شده بیشتر از بلاک قبلی بوده باشه و جا نداشته باشه تو 9i میومد از دیتادیکشنری استفاده میکرد و بلاکی که فضای خاله داره رو پیدا میکرد و اونجا آپدیت رو انجام میداد ولی اینکار به شدت باعث پایین اومدن performance میشد پس از 10g به بعد اوراکل یک بلاک جدید بلافاصله میسازه و کل رکورد رو جا به جا میکنه (block migrate)
بعد از اینکار اوراکل میره سراغ rebuild کردن indexهای جدول آپدیت شده
نکته: null هیچ حافظهای نمیگیره
حالتهای مختلف بلاکهای database buffer cache
- unused (بدون استفاده)
- cleen
- pinned (در حال استفاده)
- dirty
unused = دیتابیس اومده بالا توی database buffer cache هیچ اطلاعاتی ریخته نشده
pinned = وقتی اطلاعات select میشه و کاربری نیاز به اون بلاک داره
dirty = وقتی رکورد در آپدیت تغییر کنه اون بلاک dirty میشه یا مدت طولانی کسی با اون بلاک کاری نداشته باشه
cleen = وقتی با الگوریتم LRU میاد dirtyها رو مینویسه تو disk (با backgroun process dbwriter) یا میندازه بیرون و database buffer cache خالی میشه
نتیجه کلی: database buffer cache کلاً برای بالا بردن performance کاره پس اگه selectهاتون کند بود update, insertهاتون طولانی شد ممکنه database buffer cache شما کم باشه
تو 11g با افزایش فضای SGA به طور خودکار با AMM فضای database buffer cache هم زیاد میشه
چه سیستمهایی چه بلاک سایزی
transactional = هرچی بلاک سایزها کمتر باشه بهتره چون:
- دستورات dml ای (insert, delete, update, merge) زیاده پس مجداله (هجوم) به بلاکها و خوندن رکوردها زیاده
- صف برای خوندن بلاکها زیاد ایجاد میشه
پس اگه ما بلاکهای بزگ داشته باشیم چون کاربرهامون نیاز به آپدیت و درج رکورد دارند باید کل بلاک رو هر بار در اختیار چند نفر بذاریم در صورتی که ممکنه بقیه هم نیاز به رکوردهای اون بلاک داشته باشند
اینجا هرچی یاز بلاکهامون کمتر باشه مجادله کمتر میشه و performance بالاتر میره (تو مستندات اوراکل best practice میگه که کمتر از 4k نگیرید و یادتون باشه نباید از بلاک سایزهای os کمتر باشه)
تو این حالت selectهامون کندتر میشه چون بلاکهامون کوچیکه
warehouse = هرچی بلاک سایزها بیشتر باشه بهتر چون با یه بار IO میره ۵۰ تا بلاک رو میخونه (32k نسبتاً خوبه)
سیستمهای ترکیبی = best practice اینه که بلاک سایزها رو 8k بگیرید

سلام