نگاهی بر معماری Oracle Database 11g - قسمت اول
نگاهی بر معماری Oracle Database 11g - قسمت دوم
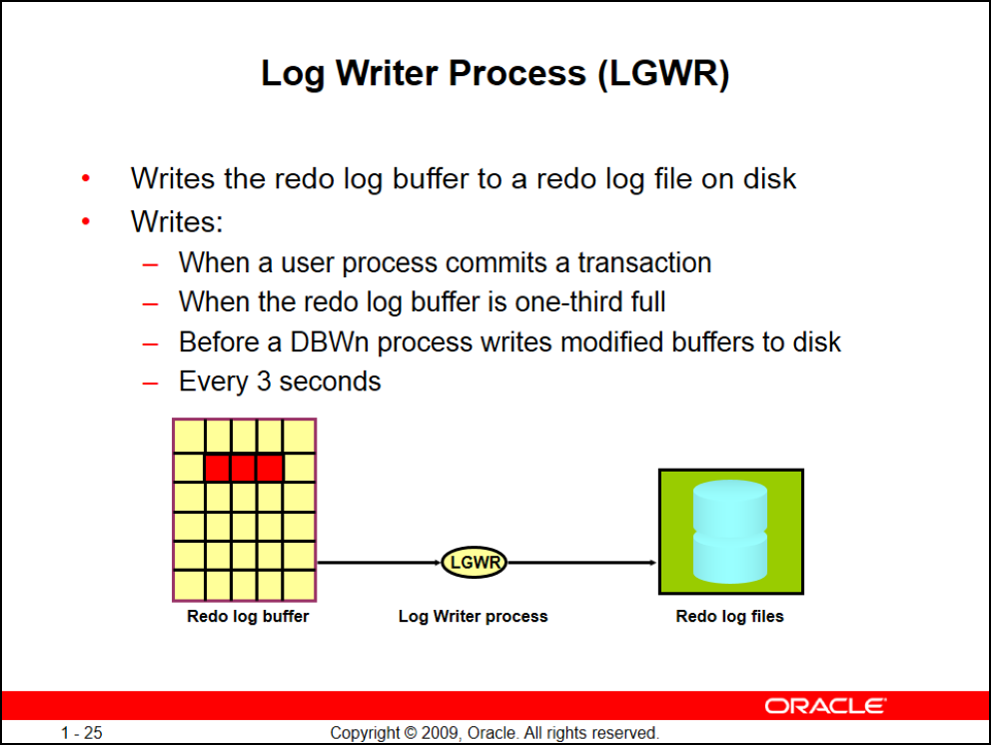
LGWR
کار background process log writer اینه که تمام redo entryها رو که توی log buffer نوشته میشه رو توی redo log file بنویسه
LGWR تعداد نداره یعنی همیشه یکی است و اگه این background process پایین بیاد دیتابیس کلاً shutdown میشه
زمانهای نوشتن:
- اگر کاربر دستور commit رو بزنه
- وقتی که 1/3 redo log buffer پر بشه
- قبل از شروع نوشتن بافر در دیسک توسط DBW
- هر ۳ ثانیه یکبار
سرعت نوشتن LGWR بسایر بیشتر از DBW ه چون فقط به انتهای یک فایل باینری redo entryها رو میبره
LGWR به صورت چرخشی بین redo log file ها عمل میکنه که بهش log witch میگیم
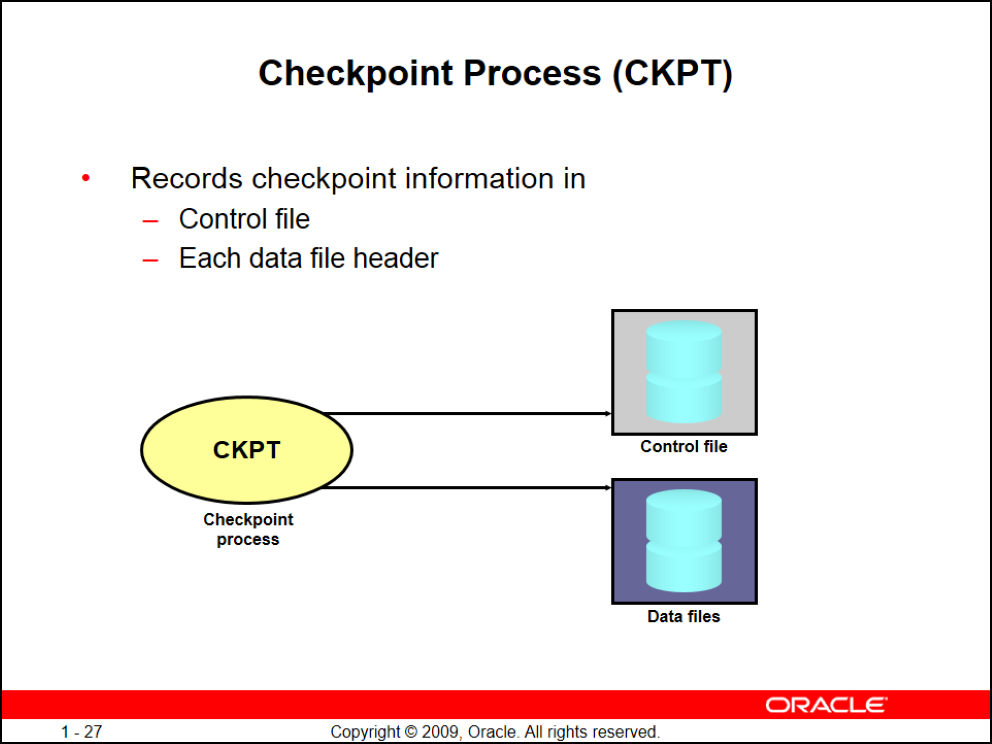
CKPT
checkpoint میاد روی control file و روی header تمامی Data fileها یک SCN مینویسه (System Change Number) که این یک عدد به صورت ترتیبی است و هیچوقت به عدد قبلی برنمیگرده (auto number) و به محض اینکه log switch اتفاقی میافته CKPT سریع میره تو control file با timestamp لاگ رو با یه SCN جدید ثبت میکنه همچنین بعد از اتمام کار DBW میره تو Headerهای Data Fileهای نوشته شده SCN رو درج میکنه
نکته: ما زمانی به Instance Recovery نیاز داریم که SCN تو control file نوشته شده باشه ولی تو Data File نوشته نشده باشه پروسه چک کردن SCNها موقع بالا اومدن instance رخ میده

SMON
- موقع بالا اومدن instance به محض این که instance recovery نیاز باشه SMON شروع به کار میکنه و میاد تمام دیتاها رو sync میکنه
- همچنین وظیفه SMON اینه که جداول temporary رو در زمان آنلاین بودن دیتابیس از tablespace temp خالی کنه
tablespace temp: وقتی عملیاتی انجام میشه که server process برای انجام اون حافظه کافی تو SGA, PGA نداره server process کار رو کم کم انجام میده و نتیجه محاسبات رو توی table temp نگهداری میکنه
مثلاً ما sort برای ۲۰ میلیون رکورد زدیم در حالی که حافظه کمی در اختیار داریم تو این مورد server process فضای کافی تو محفظهی sort area نداره پس ۱۰۰۰ تا ۱۰۰۰ تا sort رو انجام میده تو حافظه و نتیجه رو توی جدول temp روی دیسک مینویسه (معمولا tablespace tempها به صورت auto extend است)
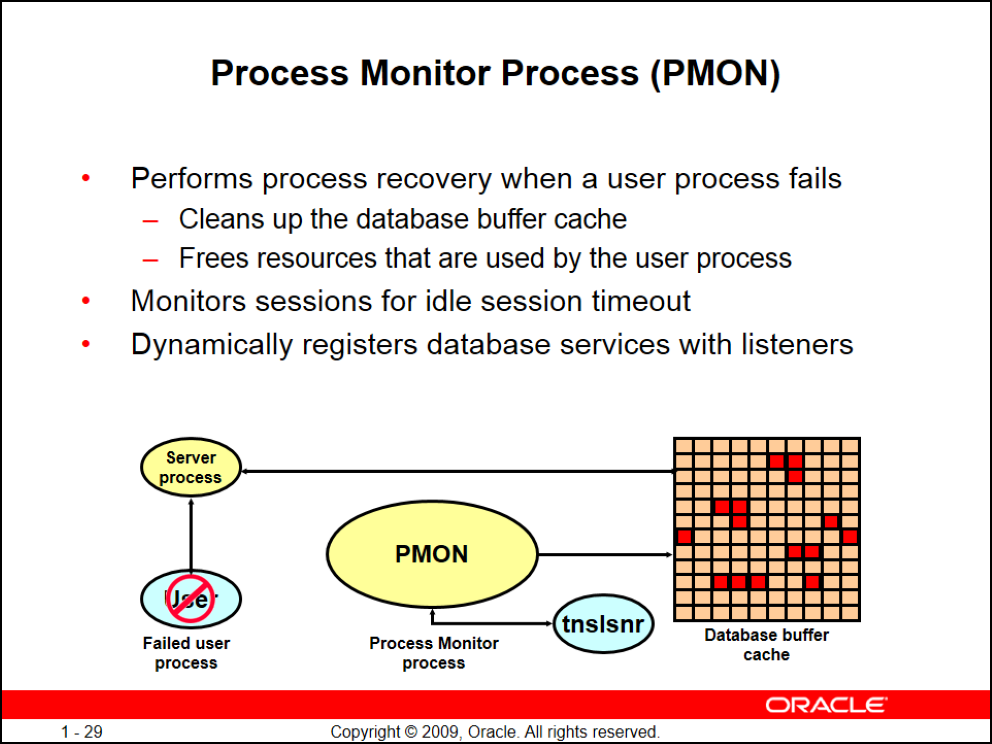
PMON
خب server process که از روی دیسک میخوند و میاورد تو database buffer cache میذاشت
فرض کنید کاربر یک update یا selectای زده ولی در بین کار session کاربر قطع میشه، خب درسته کاربر قطع شده ولی دیتا هنوز توی database buffer cache مونده
- یکی از وظایف PMON اینه که دادههای idle شده session در database buffer cache رو پاک کنه
- آزادسازی منابع استفاده شده user process
- مانیتور کردن sessionهای idle شده یا timeout خورده
فرض کنید سمت دیتابیس شما یک listener و یک instance دارید موقعی که یک user میخواد connection ای روی پروتکل tcp/ip برقرار کنه پکتها رو میفرسته و بعد از broadcast شدن پکتها و رسیدن به سرور listener وظیفه داره پکتی که مقصدش سرور جاری و پورت listener است رو بگیره و بلافاصله بعد از گرفتن درخواست بلافاصله یک server process به instance مورد نظر ایجاد کنه (تشکیل connection)
از اونجایی که ممکنه روی یک دیتابیس ۲ تا instance داشته باشیم listener باید بدونه روی کدوم instance امون باید server process رو بالا بیاره و ارتباطهای SGA, PGA رو هندل کنه
- یکی از وظابف PMON تشخیص، register و اتصال listener به instance موردنظر به صورت dynamic ه و به صورت پیشفرض PMON اولین instance رو برای اتصال در نظر میگیره
نکته: میشه به صورت مستقیم listener رو کانفیگ کرد که این listener به کدوم instance وصل بشه و بار رو از روی PMON برداریم
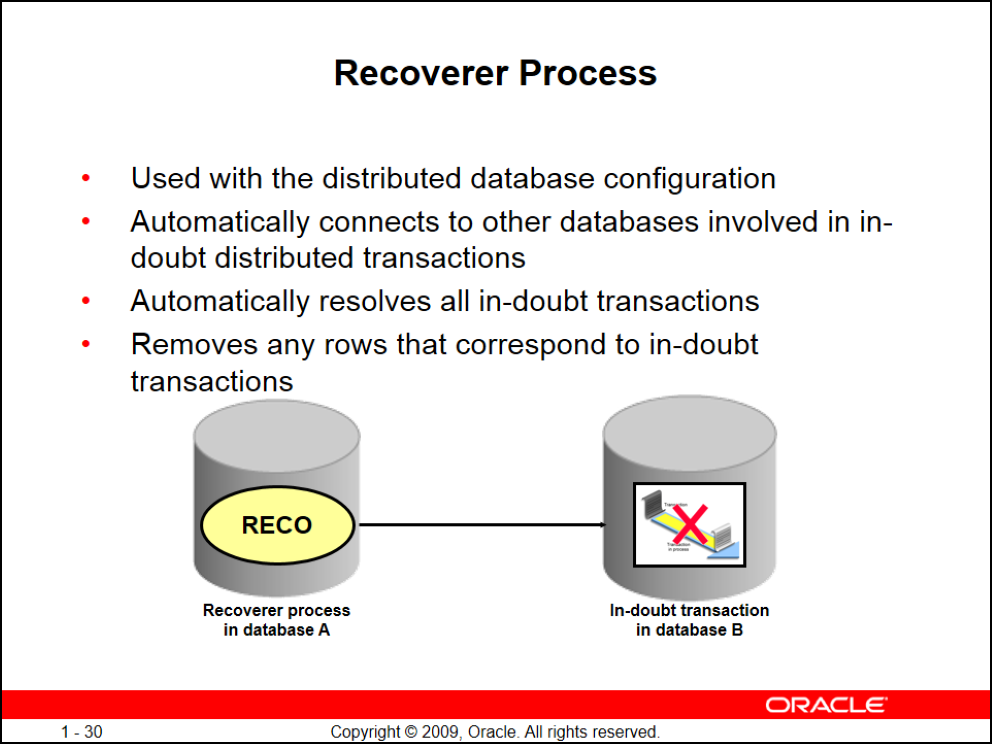
Recoverer Process
- در مواقعی که دیتابیسهای ما به صورت distribut هست از این Background Process استفاده میشود
- این Backgroung Process وظیفهی درخواست ارسال مجدد پکتهای از دست رفته بین سرورها و پاک کردن رکوردهای خراب از کانکشن را بر عهده دارد
- (مثلا از یک سرور میخواهیم ۲۰۰ رکورد را به سرور دیگری انتقال دهیم و در بین راه از ۲۰۰ رکورد فقط ۱۵۰ تا رکورد به سرور دوم انتقال داده میشود، وظیفهی Recoverer این هستش که درخواست رکوردهای جا مانده را دوباره بدهد)
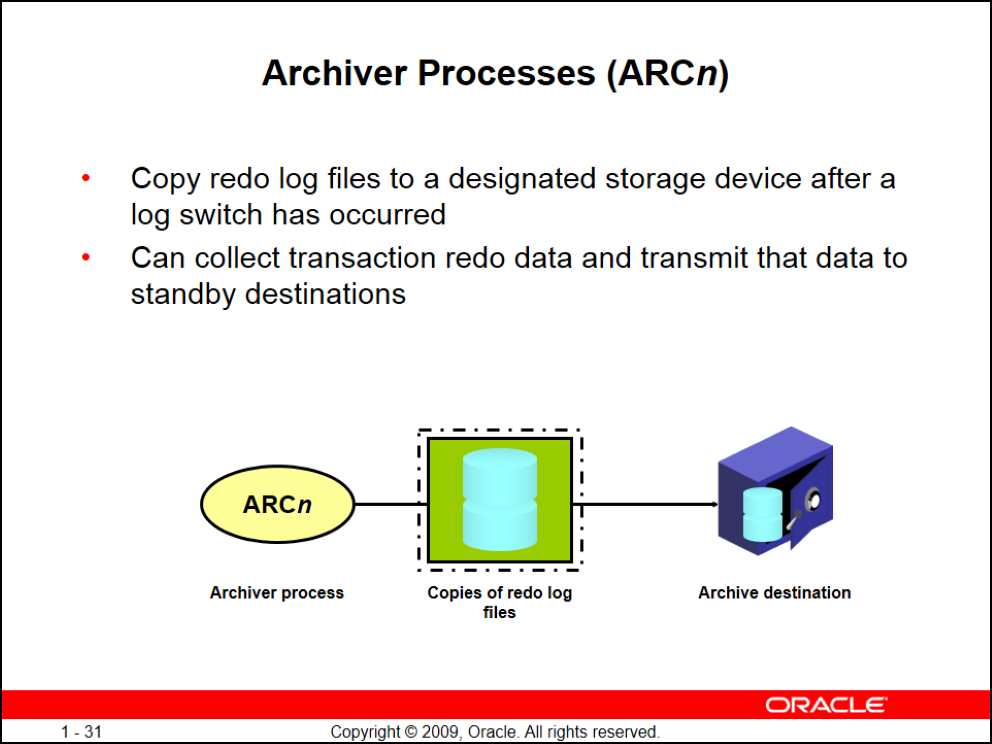
(Archiver Processes (ARCn
این Background Process با اولین Log Switch شروع به کار میکنه و از Onine Redo Log Fileها یک کپی آفلاین تو مسیری که ما مشخص میکنیم میگیره (میشه تا ۹ مسیر برای Archiver مشخص کرد تا redundant بیشتر برای حفظ دیتا ایجاد کنیم حتی میتونیم یکی از مسیرها رو برای Active Data Guard در نظر بگیریم)
حال ممکن است یک اتفاق بیوفتد، هنوز archiver کارش تموم نشده مجدد log switch اتفاق میوفتد، در این حالت waiting رخ میدهد که موجب کندی سیستم میشود. برای حل این مشکل باید یا حجم redo log file ها را بیشتر گرفت که خود دچار تاخیر در ارسال به standby میشود یا تعداد گروه ها را بیشتر کرد که معمولا از این حالت استفاده میشود. در این حالت برای اینکه archiver فرصت کافی برای انجام عمل آرکایو را داشته باشد باید تعداد archiver ها را افزایش داد.
نکته: هیچگاه دیتابیس عملیاتی را به ساعات قبل برگشت ندهید بلکه باید از روی یک دیتابیس دیگر که معمولا برای تست استفاده میشود بک آپ سرور را برگردانید و از روی فایل های archive شده عمل برگشت به عقب (flashback) را انجام دهید و رکوردهای آسیب دیده را برگردانده و به سرور اصلی اضافه کنید.
نکته: حتماً دیتابیس عملیاتیتون رو روی حالت archive بذارید و اگه دیتابیسی تو حالت archive نبود پشتیبانی اون رو نگیرید اصلاً هم به فضا و کندی دیتابیس بها ندید (یادتون باشه حذف دیتا عواقب مالی زیادی داره)
نکته: تا زمانی که کار Background Process Archiver تمام نشده Overwriteای در Redo Log Fileها اتفاق نمیافتد و wait رخ میدهد
نکته: Best Practice برای Log Switch در این مواقع اینه که سایز عضوها یا تعداد گروهها یا تعداد ARCها را زیاد کرد
نکته: هیچوقت بر روی سرور عملیاتی عملیات بازگردانی از روی آرشیوها رو انجام ندهید (مگر این که سرور کرش کرده باشه) و حتماً یک سرور تست بالا بیارید و دیتا رو برگردونید و بعد از بازگردانی دیتای مورد نظر را به سرور اصلی انتقال دهید.
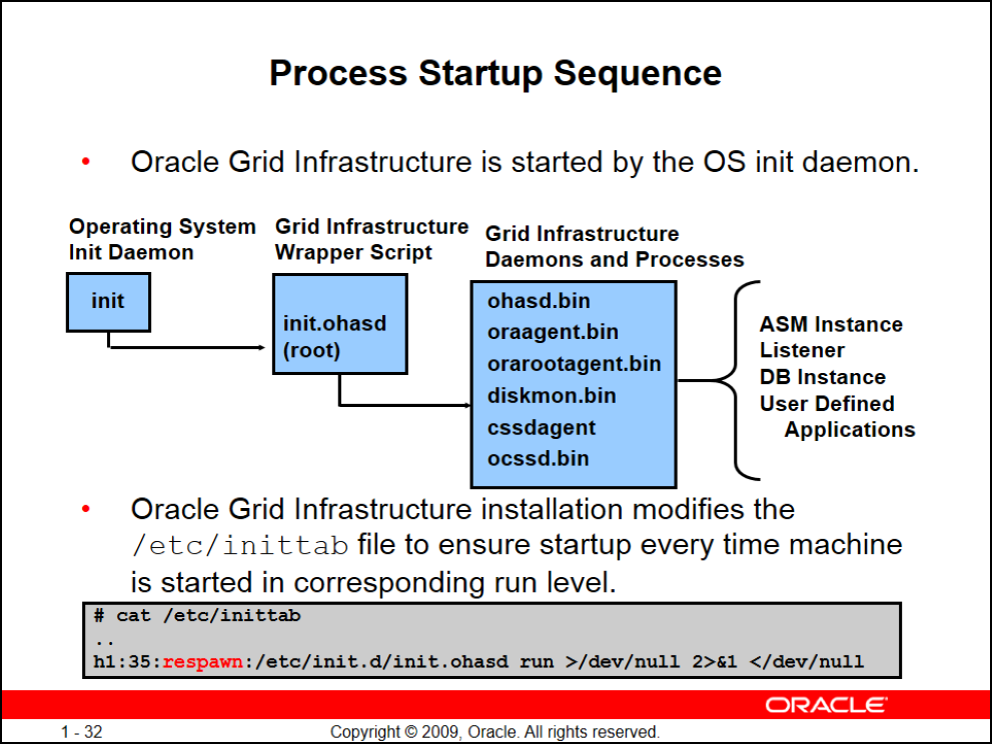
Process Startup Sequence
Background Processهایی که وقتی شما Grid Infrastructure رو نصب میکنید اجرا میشوند
یادتون باشه اگه دیتابیس اوراکل رو روی لینوکس به صورت database only نصب کنید به هیچ عنوان نه listener نه database بالا نمیآید و یا باید دستی اینکارو کنید یا اسکریپت بنویسید ولی اگه شما grid رو نصب کرده باشید این اتفاق به طور خودکار میوفته و توسط init.ohasd اینکار انجام میشود. (Oracle High Availability Services Daemon)
نکته: توی مسیر etc/inittab/ شما هر اسکریپتی بذارید موقع اجرای توزیعتون به طور خودکار اجرا میشود.
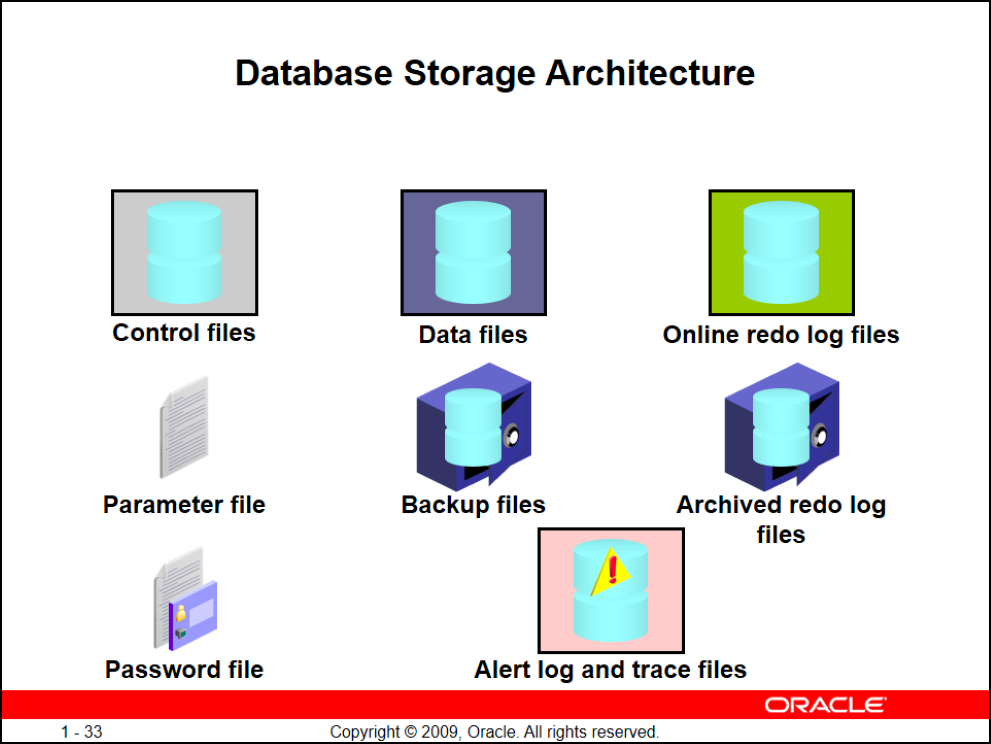
Database Storage Architecture
- Data files = تمام دیتای ما
- Online redo log files = تمام تغییرات رو نگهداری میکنند
- Control files = ساختار فیزیکی تمام data fileها و redo log fileها و undo segmentها تو کنترل فایله همچنین یکی دیگه از کاربردهای Control fileها نگهداری متا دیتای بکآپها است
- Backup files = آرشیوها . بکآپهای گرفته شده از دیتابیس
- Archived redo log files = همون Background Process ARCn که از redoها کپی میگیره
-
Alert log and trace file = هر خطایی که توی دیتابیس به وجود بیاد تو این فایل نوشته میشه
- oracle/admin/<SID>/bdump = 10g/
- oracle/diag/rdbms/orcl/orcl/trace = 11g/
- Password file = پسورد کاربرهای sysdba، sysoper و sysasm رو به صورت encrypt شده نگهداری میکنه و هر وقت شما میخواین به صورت ریموت به دیتابیس وصل بشید پسورد این کاربرها رو از این فایل میخونه
- Parameter file = ما ۲ فایل spfile و initfile داریم که تمام پارامترهای دیتابیس موقع لود شدن رو داخل خودشون نگهداری میکنند
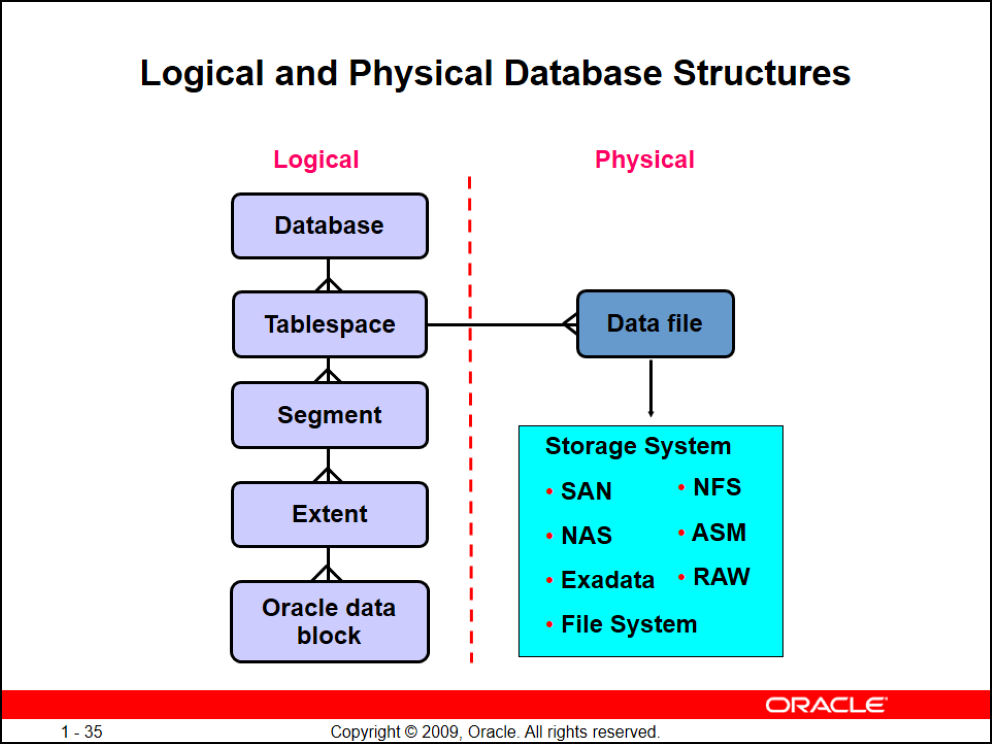
Logical and Physical Database Structures
تو معماری فیزیکی
فقط یکسری فایل هستند که روی هر media ذخیرهسازی قابلیت ذخیرهسازی را دارند مثل(NFS, SAN, ASM, NAS, RAW, Exadata, File System)
تو معماری منطقی
برای منظم کردن و دسترسی بهتر به دیتاها لایهی منطقی به چند بخش تقسیم میشود
(Database, Tablespace, Segment, Extent, Oracle data block)
یک دیتابیس میتونه چندین tablespace داشته باشه
خود tablespace به صورت segmentبندی شده ایجاد میشود
هر Segment به Extentهای مختلفی تشکیل میشه تا واکشی rowidها سریعتر از data blockها انجام گیرد

Segments, Extents, and Blocks
میخوایم راجع به ارتباط این مفاهیم باهم صحبت کنیم
- هر tablespace از چند segment تشکیل شده
- segmentها از چند تا extent تشکیل شدن
- هر extentای از چند تا data block تشکیل شده
- هر data block اوراکل میتونه مضربی از disk block های سیستمعامل باشه
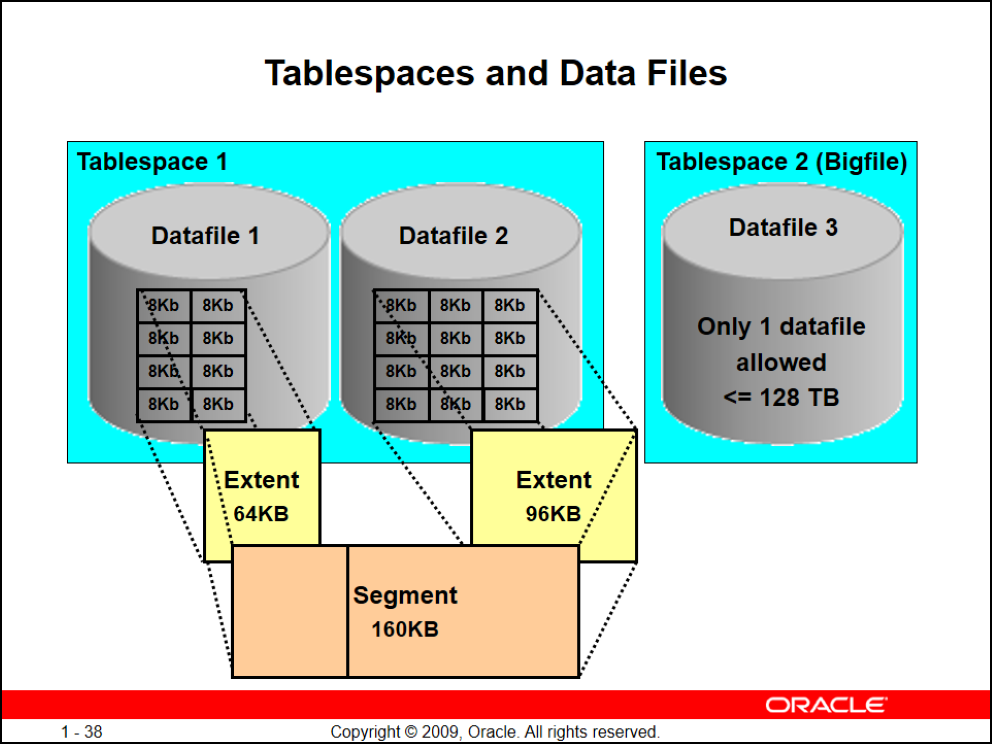
Tablespaces and Data Files
ممکنه یک tablespace چندین data file داشته باشه خب اگه data fileها رو به صورت فیزیکی در نظر بگیریم هر data file رو میشه به بلاکهای 8k ای در سطح هارد تقسیم کرد پس مجموعهای از چندتا از این بلاکها میشه Extent که به صورت پیشفرض 64k هستش و مجموعه چند extent میشه segment
پس امکان این که جدول شما روی چند data file ذخیره بشه وجود داره
یادتون باشه logic ما به واسطهی tablespace انجا میشود و با وجود این شی دیگه ما به نحوه کارکرد خود لایه فیزیکی کاری نداریم
tablespaceهای ما میتونه n تا فایل داشته باشند

SYSTEM and SYSAUX Tablespaces
از tablespaceهای معروف
SYSTEM = یکی از حیاتیترین tablespaceهای اوراکل system ه اگه این tablespace کرش بکنه دیتابیس به هیچ عنوان بالا نمیاد و تو این موارد بدون بکآپ و آرشیوها به هیچعنوان نمیشه کاری کرد، این Tablespace حاوی متادیتاهاست
SYSAUX = تیبل اسپیس کمکی auxiliary) sysaux) آمارهای em و اطلاعات performanc ای در این tablespace نگهداری میشود. اگر این tablespace کرش کنه اصلاً مهم نیست و میتونید دوباره آمارها رو محاسبه کنید ولی باعث میشه دیتابیس برای مدتی کند بشه. (تو 9i و قبل اون این tablespace جزئی از SYSTEM بود)
Automatic Storage Management
انشالله در پستهای آینده به این معماری به صورت جامع میپردازم.