تو این مجموعه پستها میخوایم نگاهی مقدماتی بر اوراکل دیتاگارد از روی اسلایدهای اوراکل داشته باشم:

بعد از کامل کردن این سری از اسلایدها شما قراره:
- کامپوننتها و اجزای دیتاگارد رو بشناسید
- اختلاف بین physical standby و logical standby رو بدونید
- فواید پیادهسازی دیتاگارد رو بشناسید
نکته: کلاً وقتی دیتاگارد راه میندازیم یعنی ۲ تا سرور داریم یکی سرور اصلی primary و یکی سرور دیتاگارد که بهش standby میگیم (چون همیشه آماده به خدمته)
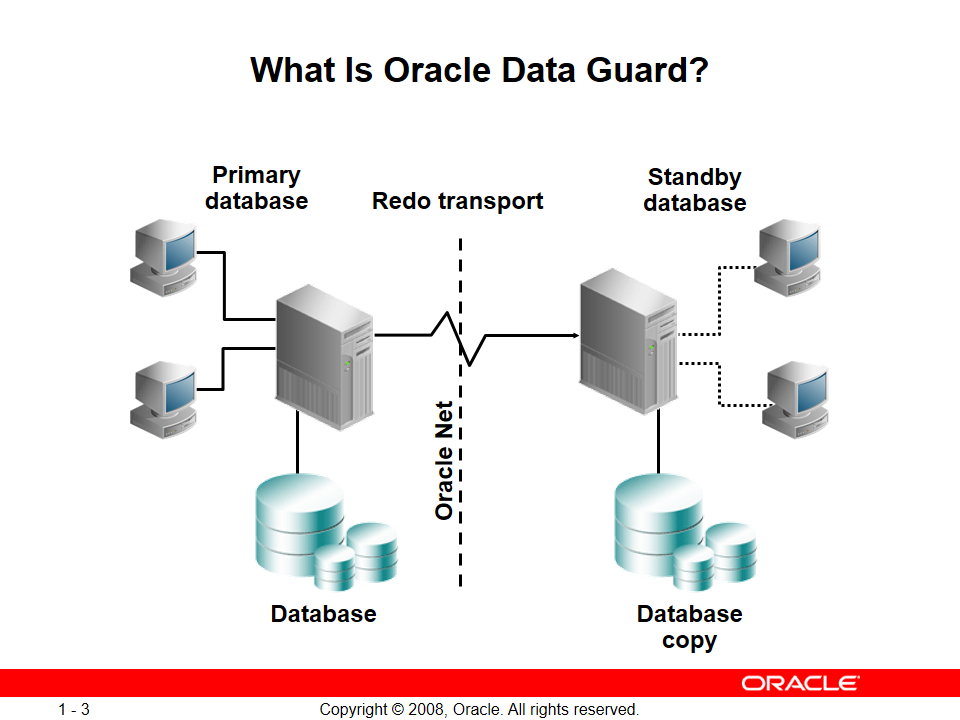
ما ۲ تا سایت داریم سمت چپ میشه سایت اصلی (Primary database) و سمت راست میشه سایت گارد (Standby database) که ارتباط این ۲ سایت از طریق Oracle Net (بستر شبکه) هستش
نکته: تو بیشتر سایتها oracle net بر مبنای پروتکل tcp/ip کار میکنه
تو این سناریو هر تغییری که شما توی سیستم اصلی اعمال کنید از طریق ارسال redoها به سرور سمت standby دیتابیسها باهم sync میشوند.
انواع standby databaseها


- Physical standby database
- Logical standby database
- Snapshot standby database
Physical standby database
یعنی عملیات به صورت بلاک به بلاک انجام میشه و کل فیزیک دیتاها از طریق ارسال redo log fileها منتقل میشه
توی ورژن 10g دیتابیس standby استفاده دیگهای تو این mod نداشت چون دیتابیس فقط تو حالتهای shutdown, nomount, mount, open قابل دسترس بود و دیتابیس standby فقط تا مرحله mount بالا میاد پس وقتی نمیتونید instance رو open کنید استفاده دیگهای هم از دیتابیس standby نمیتونید داشته باشید
از ورژن 11g به بعد میشه دیتابیس standby رو تو حالت open readonly هم بالا آورد پس با این امکان میشه از دیتابیس standby به عنوان DW برای گرفتن گزارشهای BI هم استفاده کرد
Logical standby database
تو logical شما میتونید به صورت schema به schema دیتا رو منتقل کنید در حقیقت برعکس physical که شما هرکاری بکنید به سرور standby منتقل میشه. یه جورایی شبیه replication یعنی شما حتی میتونید جداول مختلف رو به هم متصل کنید. پس در اصل redo ها انتقال داده نمیشن و دستورات sql منتقل میشن (sql apply)
تو این حالت شما میتونید دیتابیس stanby رو به صورت read/write هم بالا بیارید فقط توجه داشته باشید که replication اتون به صورت یکطرفه از سمت primary به standby ه و هر تغییری روی stanby اعمال کنید رو primary اعمال نمیشه
اگه بخوایم از replication امون رو به صورت ۲ طرفه راهاندازی کنیم از Oracle GoldenGate استفاده میکنیم که یک محیط ناهمگن به صورت n به n ه
محدودیتهای stanby خیلی بیشتر از goldengate ه مثلاً: از لحاظ نسخه و پچهای اوراکل حتماً و حتماً باید ۲ دیتابیس یکی باشند
ولی توی streams و goldengate پلتفرمها و نسخه اوراکل میتونه متفاوت باشه حتی تو goldengate دیتابیسها میتونن متفاوت باشن
توجه داشته باشید که logical standby تمام data typeهای اوراکل رو ساپورت نمیکنه و شما محدودیتهایی روی BLOB, CLOB, NCLOB, BFiILE و ... داره ولی physical هیچ محدودیتی نداره
نکته: تو حالت logical چون دیتابیس همیشه به صورت open هستش رو همهی ورژنهای اوراکل میتونید ازش به عنوان DW استفاده کنید
Snapshot standby database
به صورت لغوی snapshot یعنی عکس گرفتن یا همون ثبت لحظه
توی دیتابیس snapshot به این صورته که وضعیت تمام دیسک و حافظه رو میگیره و شما آزادید هر تغییری میخواین رو دیتابیس بدید و هر وقت بخواین به لحظه قبل برگردید
خب با این اوصاف راهاندازی snapshot standby بیشتر برای آپدیتهای بزرگ یا اعمال پچهای مختلف رو سیستمعامل یا دیتابیس به درد میخوره
راهاندازی snapshot خیلی منطقیتر از دوباره کانفیگ کردن physical standby هستش (بر فرض این که روی standby پچ یا آپدیت موردنظر رو اعمال کردیم و دیتابیس بر اثر اون پچ یا آپدیت failed شده)
تو ابن حالت redo هایی که از سمت دیتابیس primary میاد انتقال داده میشن اما apply نمیشن اینجا شما آزادید هرکاری رو دیتابیس میخواین رو انجام بدید و بعد از اعمال تغییرات در صورت موفقیت snapshot رو بردارید و standby رو برگردونید روی حالت خودش (physical, logical) و redoهایی که باعث تغییرات روی سرور اصلی بودند شروع به apply شدن میکنن
نکته: به طور معمول snapshot رو روی physical راهاندازی میکنن
سروریسهای Data Guard

Redo transport services = وظیفهی این سرویس فقط و فقط ارسال و انتقال redoها از primary به standby هستش (سمت دیتابیس primary)
Apply Services = ما یا redo apply داریم یا sql apply
Role managment services = سناریو اتصال یه کلاینت به دیتابیس primary یا اپلیکیشن سرور به دیتابیس primary رو در نظر بگیرید اگه primary خاموش بشه حالا شما باید یه تنظمی روی کلاینت انجام بدید که آدرس کانکشن دیتابیس به standby بخوره و به صورت دستی هم باید standby database رو از حالت read only خارج کنید و روی حالت read/write ببرید
برخلاف sql server که قابلیت mirroring (همون standby database) به این صورت انجام میشه که هر سروری اول بالا بیاد master و هر سروری که بعدش بالا بیاد میشه mirror اونیکی هستش توی اوراکل با استفاده از سرویس role managment حتی اگه شما ۱۰۰۰ بار هم سرورها رو reboot کنید نفشها به طور خودکار عوض میشن و تمام کارهای موردنیاز برای بردن دیتابیس رو حالت standby موقع بالا اومدن سرور انجام میشه

Switchover
اوراکل با استفاده از switchover نقشها رو عوض میکنه (primary, standby) این شرایط به درد مواقعی که شما حتی نمیتونید downtime سختافزاری بدید میخوره و نهایت downtime شما چند دقیقه است
Failover
اگه به هر دلیلی primary از بین بره و شما بخواین دیتابیس standby رو کلاً به صورت primary استفاده کنید از failover استفاده میکنید
- پلنی برای ای نوع downtime نداشتید
- زمانهای اضطراری
- از دست دادن دیتا تو این حالت به ۰ میرسه (که البته بستگی زیادی به حالت protection standbyاتون داره)
- اگه fast-start رو راهاندازی کنیم به صورت خودکار اگه failover شد standby میشه primary و سرور دوم هر وقت درست شد میشه standby
Oracle Data Guard Broker Framework
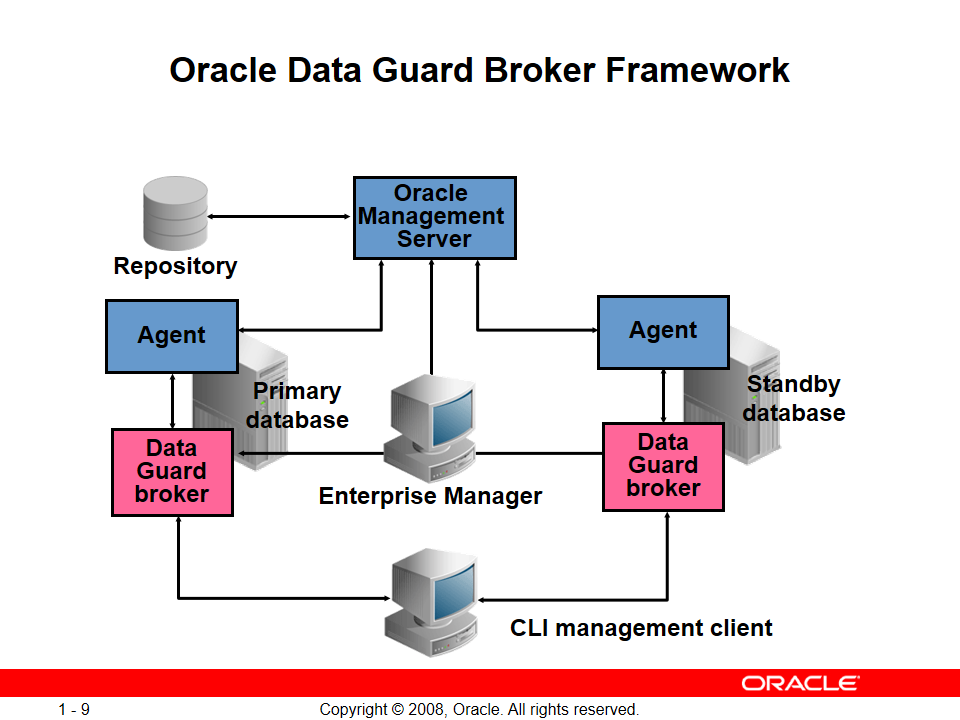
broker یه repository و یه agent ه که میاد تنظیمات دیتابیسها رو توی گارد نگهداری میکنه مثلاً اسم دیتابیس primary یا SID و ... + roleهای هرکدوم (کدوم دیتابیس primary هستش کدوم standby)
برای مدیریت broker معمولاً از EM Cloud Control استفاده میشه
نکته: db_unique_name در دیتابیس primary و standby میتواند همنام باشد ولی دیگه نمیتونیم از broker استفاده کنیم و دیگه از طریق EM Cloud Control نمیشه دیتابیسها رو مدیریت کرد و همیشه standby به صورت down نشون داده میشه برای همین اصرار بر این است که db_unique_name ها (SIDها) یکسان نباشد
رابطهایی برای مدیریت Data Guard

کانفیگ از طریق broker
- دستور command-line ای DGMGRL
- محیط Enterprise Manager Grid Control
- از طریق دستورات SQL و کوئری گرفتن از دیتادیکشنریها
کانفیگ بدون broker
- دستورات SQL
معماری Data Guard
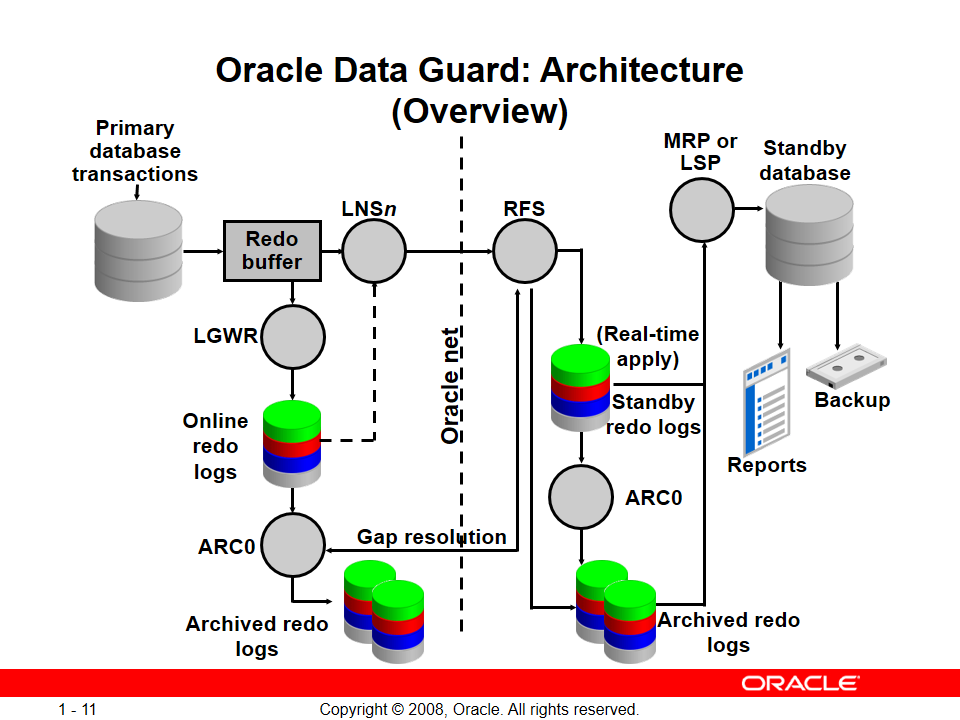
همونطور که میبینید ارتباط دیتابیسها از طریق شبکه و پروتکل Oracle Net هستش
یکی از کامپوننتهای اصلی ما Redo LOG Buffer هستش و کارش ثبت Redo Entryها یا همون ثبت دستورات SQL ای (DCL, DDL, DML) هستش
مواقعی که خالی میشه:
- هر ۳ ثانیه یکبار
- پر شدن ۱/۳ آن
- checkpoint یا commit یا switch log ای اتفاق بیافته
در نهایت تغییرات در Online Redo Log File قرار میگیره و وظیفهی background process (LGWR) هستش که اینکار انجام بده (از Redo Log Buffer میاد redoها رو میگیره و توی Online Redo Log File ها مینویسه)
نکته: وظیفهی Online Redo Log Fileها فقط و فقط instance recover هستش همچنین Online Redo Log Fileها به صورت گروهی هستن و حداقل باید ۲ تا گروه داشته باشیم (کمتر از این دیتابیس بالا نمیاد) حالا هر گروه میتونه چندتا فایل یا همون member داشته باشه که حداکثر اون توی control file مشخص میشه (به صورت پیشفرض دیتابیس هر گروه ۲ عضوه هستن)
نکته: امکان اینکه تعداد اعضای هر گروه از هم متفاوت باشند وجود دارد
نکته:برای این multiplex میکنیم که redundany دیتا روی اعضا ایجاد بشه و هر عضو رو روی یک دیسک جدا میذاریم که اگه یکی از بین رفت یکی دیگه باشه
وقتی LGWR شروع به نوشتن Log Buffer روی یه گروه میکنه یعنی روی همهی اعضای اون گروه به طور همزمان به صورت پارالل داره مینویسه و اگه یک گروه پر شد به گروه بعدی سوییچ میکنه
نکته: به این دلیل روی همون گروه قبلی overwrite نمیکنه که بتونیم instance recovery رو تو لحظه داشته باشیم پس به همین دلیل حداقل ۲ گروه حتماً داریم
ARCn = این Background process وظیفهی کپی گرفتن از Online Redo Log Fileها رو داره تا بتونیم در آینده media recovery کنیم و به یه نقظه خاصی برگردیم چون Online Redo Log Fileها به هر حال تو چرخشی که دارن overwrite میشن و باعث از بین رفتن اطلاعات قبلی میشن
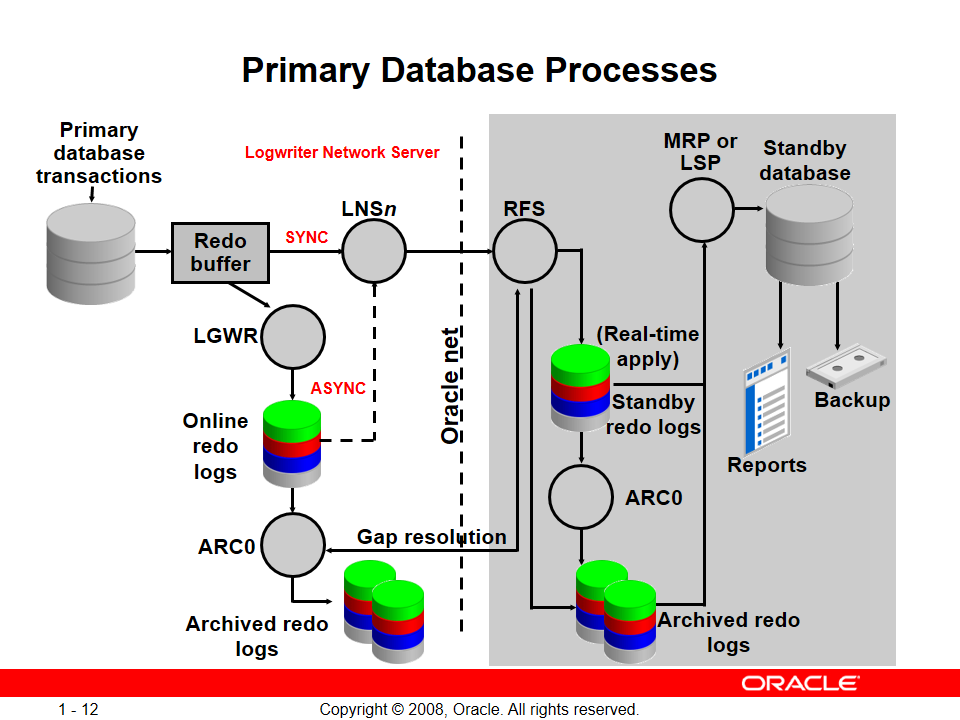
یه Background Process دیگهای تو Data Guard سمت primary ایجاد میشه به اسم LNS یا همون (Logwriter Network Server) که کارش ارسال redoها از primary به standby هستش
خب این Background Process میتونه redoها رو هم از Redo Log Buffer بگیره و هم از Online Redo Log Fileها و اینکه از کدوم بخونه و redoها رو انتقال بده بسته به شما داره که حالتش رو روی Sync یا Async بذارید
- sync = همزمان یا همون realtime
- async = همون غیرهمزمان (با تاخیر)
اگر Background Process LNS تغییرات رو از Redo Log Buffer بخونه و به سمت سرور standby بفرسته حالت sync اتفاق میافته
و اگه تغییرات رو از Online Redo Log File ها و از روی دیسک بخونه حالت async اتفاق میافته
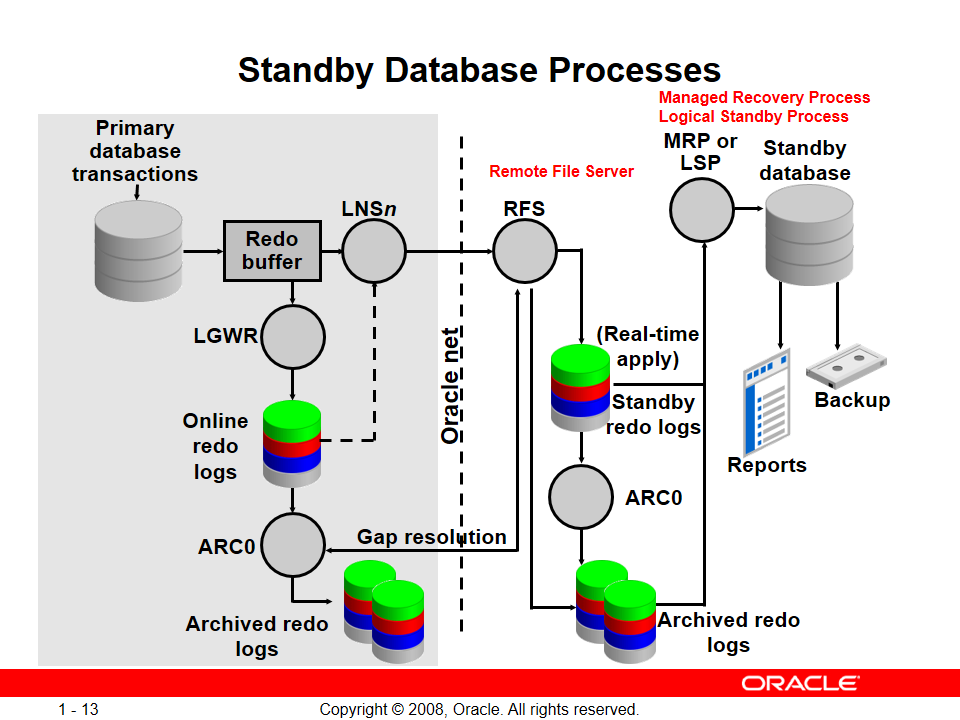
خب وقتی اطلاعات از سمت primary با LNS فرستاده میشه سمت دیتابیس standby وظیفهی RFS هستش که اطلاعات رو بگیره
بعد از دریافت اطلاعات میاد redo entryها رو روی standby redo logها رو مینویسه
خب بعد از نوشتن اطلاعات روی standby redo logها با استفاده Background Process ای به اسم (MRP Managed Recovery Process) یا (LSP (Logical Standby Process دستورات SQLای ما روی دیسکها و data fileها اعمال میشوند
نکته: بسته به نوع standby اتون اگه physical بود MRP بالا میاد و اگه logical باشه LSP بالا میاد و یادتون باشه همزمان هر دو رو هیچوقت نداریم.
همچنین همزمان با استفاده از ARCn از standby redo logها آرشیو تهیه و نگهداری میشود
نکته: دیتابیسی که برای standby راهاندازی میکنیم حتماً و حتماً باید تو مد archive باشه
نحوه اعمال redoها در physical

تو اسلاید بالا اوراکل میخواد بگه که Redoها در معماری physical به شکل stream(جریانی از دادهها به صورت پیوسته) منتقل میشوند و به محض خوندن redoها اونها apply میشوند.
نحوه اعمال SQLها در logical
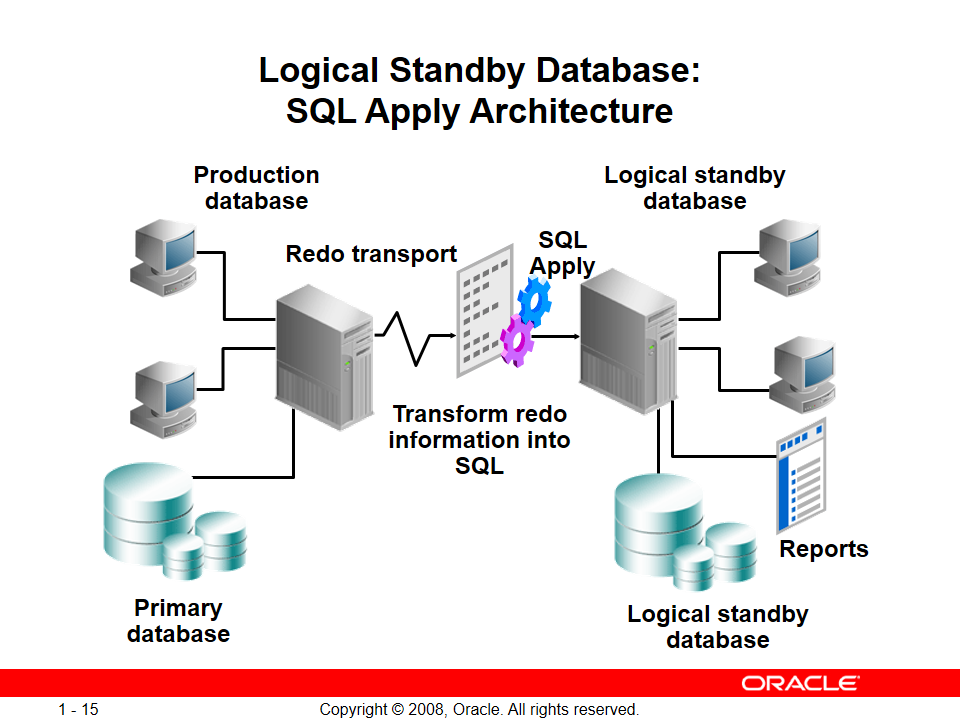
تو این حالت هم redoها فرستاده میشن ولی موقع خوندن redoها در standby روی redoها عملیات LogMiner انجام میشه یعنی دستورات sql روی دیتابیس اعمال میشود(SQL Apply)
نکته: با استفاده از تکنولوژی Oracle LogMiner میتوان redo entryها رو خوند و دستورات SQL را استخراج کرد
ex: https://oracle-base.com/articles/8i/logminer
نکته: تو معماری دیتاگارد اوراکل 10g فقط با استفاده از physical standby میتوان دیتابیس گارد رو روی حالت open-readonly برد و با معماری physical اینکار در 10g امکانپذیر نیست.
امیدوارم براتون مفید بوده باشه

آقا دمت گرم خیلی خوب و واضح توضیح دادی،خیلی برام مفید بود...دستت درد نکنه