بعد از اینکه با معماری اوراکل خوب آشنا شدید و شناخت این موضوع که اوراکل گلدنگیت کجای سازمان ما میتونه باشه و چه راهکارهایی رو میتونه به ما ارائه بده به معماری خود گلدنگیت میرسیم. در کل همین اول کار بهتره بدونید گلدنگیت عملاً از یکسری سرویس تشکیل شده یعنی اینکه اگه فکر میکنید اپلیکیشن گرافیکی هستش و دیتابیسی پشتش قرار میگیره نه این اتفاق در گلدنگیت صورت نمیگیره.
گلدنگیت در اصل یکسری سرویسه اینکه من تو پستهای قبلی همش تاکید میکردم ما CDC داریم این سرویسها هستن که اینکار رو انجام میدن و تغییرات رو میفهمن و تو شبکه جا به جا میکنن و در نهایت اعمال میکنن یا باز همین سرویسها هستن که منتظر تغییرات میمونن و به محض دریافت اونها رو اعمال میکنن و خودشون رو SYNC نگه میدارن درکل ما با یکسری سرویس سر و کار داریم و تمام فعالیتهای ما هم روی همین سرویسهاست حالا این سرویسها هر کدوم برای خودشون آرگومانهایی دارند که ما Config Fileهای موجود آرگومانهای مختلفی رو براشون در نظر میگیریم و در نهایت این کانفیگها هستن که شما با اونها بسیار کار دارید.
سناریوهای قابل پیادهسازی در گلدنگیت
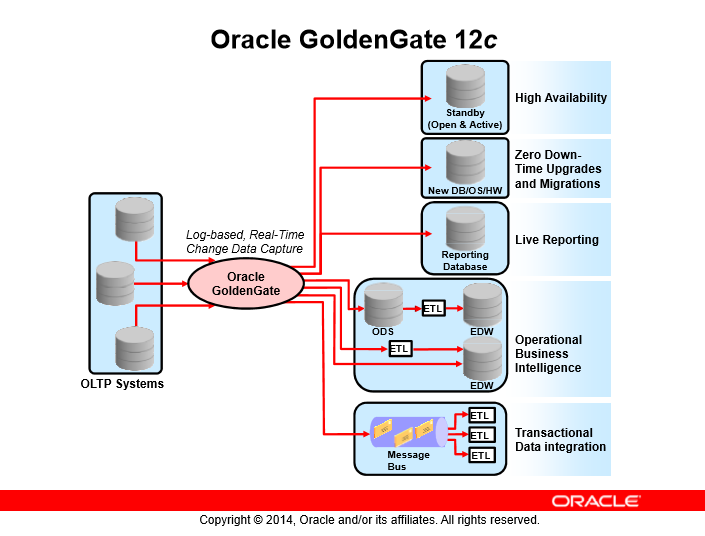 - DB: database
- DB: database
- EDW: Enterprise Data Warehouse
- ETL: Extract, Transform, and Load
- HW: Hardware (Intel 32-bit, Intel 64-bit, SPARC, and so on)
- ODS: Operational Data Store
- OLTP: Online Transaction Processing
- OS: operating system (Linux, Windows, and so on)
نکته: به نظرتون چرا گلدنگیت سراغ online redo log fileها میره؟ سرویسهای گلدنگیت عملاً دنیال تغییرات دیتا هستن حالا در اوراکل این تغییرات در online redo log fileها عملاً نگهداری میشوند و فقط تغییرات در این فایلها هستند در دیتابیسهای دیگه هم گلدنگیت به دنیال فایلهای log و مکانیزمهای تغییر دیتا میگرده و از اونها که برای هر دیتابیسی مختلف و منحصر به فرد هستش استفاده میکنه
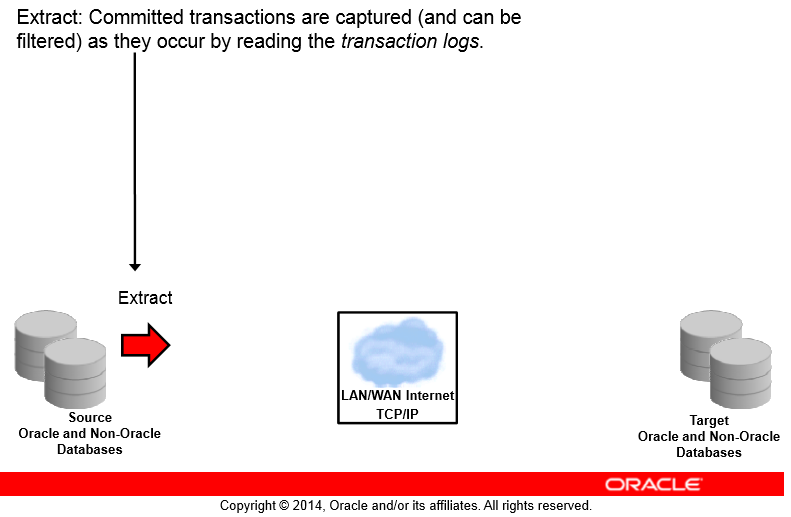
Extract
همونطور که در شکل میبینید ما یک Source و یک Target داریم حالا سورس ما میتونه اوراکلی باشه یا غیر اوراکلی به همین ترتیب Target ما هم میتونه اوراکلی باشه و یا غیر اوراکلی پس گلدنگیت نسبت به نوع دیتابیس Transparent هستش و وابستگی به نوع دیتابیس نداره
اولین کاری که میخوایم گلدنگیت برامون انجام بده اینه که یکسری تغییرات رو capture بکنه همونطور که گفتم گلدنگیت سرویس بیس هستش یعنی برمبنای یکسری سرویس عملیاتهاش رو انجام میده
پس اول از همه ما به یک سرویسی نیاز داریم که بیاد تغییرات دیتا رو capture بکنه به این سرویس Capture میگیم که از جنس Extract هستش یعنی میخواد عملیات Extract و Capture رو برای ما انجام بده
سرویسهای ما در گلدنگیت به ۲ دسته کلی تقسیم میشوند:
- Extract = لاگها رو از دیتابیس استخراج میکنه و عملیات capture رو انجام میده
- Replicat = لاگها رو بر روی دیتابیس مقصد apply میکنه
یعنی یا دارند یکسری لاگها رو استخراج میکنند یا دارند یکسری لاگها رو اعمال میکنند
شاید یه موضوعی ذهنتون رو درگیر کنه اونم اینکه تو شکل بالا نوشته Committed transactions خب این یعنی گلدنگیت فقط تراکنشهای commit شده رو Extract میکنه پس اگه ما یک تراکنشی داشته باشیم که هنوز commit اش نکردیم و معلوم نیست شاید rollback اش کنیم نیازی نیست اون رو به دیتابیس مقصد انتقال بدیم ما فقط نیاز داریم چیزی کپچر بشه که commit شده و وضعیتش stable هستش
سرویس capture ما در اوراکل از روی online redo log fileها میاد تراکنشهای commit شده رو پیدا میکنه و از اینجا استخراج دستورات commit شده رو انجام میده حالا فکر کنید یک gap ای ایجاد بشه و اوراکل نتونه از روی online redo log fileها استخراجش رو انجام بده و نیاز اطلاعات مثلا 2 ساعت قبل رو داشته باشه که توی online redo log file ها نیست (خود gg بعد از هر عملیات مپچر scn مربوطه که extract کرده رو نگهداری میکنه پس وقتی میره سراغ online redo log fileها میدونه دقیقاً از کدوم scn دیتا رو باید استخراج کنه در صورتی که online redo log file ما اون scn رو نداره و خیلی وقته از روش گذشته و سوییچ رو انجام داده) اینجا پروسه کپچر سراغ archive log fileها میره و از روی آرشیوها برای حذف gap به خوندن میکنه
نکته: گلدنگیت به صورت اجباری شما رو مجبور نمیکنه که دیتابیستون رو روی حالت آرشیو ببرید و بدون حالت آرشیو هم به درستی کار میکنه و دیتابیسها رو SYNC نگه میداره ولی اگه gap ای وسط کار بیوفته تمام مسئولیتش با خودتون هستش و گلدنگیت نمیتونه براتون gap رو بدون آرشیوها handle بکنه
نکته: هر زمانی سرویس capture ببینه نمیتونه آخرین SCN اش رو در Online Redo Log Fileها پیدا کنه و در صورتی که Archive Redo Log Fileها هم موجود نباشه سرویس capture به حالت abbended در میاد و تو این حالت شما باید وارد کار بشید و به صورت دستی براش تکلیف مشخص کنید مثلاً بگید gap رو بیخیال بشه و از scn فعلی دوباهر شروع به کار کردن بکن
پس گلدنگیت بدون آرشیو لاگ هم کار میکنه ولی شما رو تو خطر بزرگی قرار میده پس همیشه سعی میکنیم دیتابیس مبدا رو روی آرشیو لاگ بذاریم تا خودش بتونه gap رو هم handle بکنه
خب حالا ما شروع به capture تغییرات با پراسس Extract کردیم خب نتیجه این capture بی زبون ما باید یه جایی ذخیره بشه چون سرویس ما یه ورودی گرفته و دستورات commit شده رو از redo ها کشیده بیرون حالا باید یه جایی نتیجه کارش رو که convert این دیتاها به فرمت universal هستش رو ذخیره کنه این خروجی در گلدنگیت یکسری فایل به اسم Trail هستند
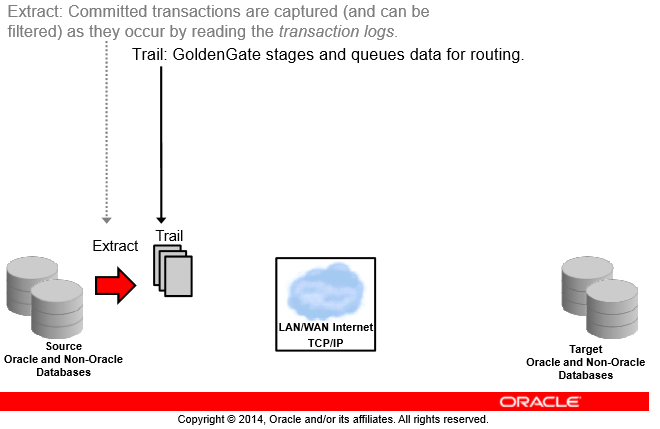
Trail
Trail File ها در حقیقت همون تغییراتی هستند که سرویس Extract ما Capture و Convert کرده داخل یکسری فایلهای سیتسمعاملی در مسیری مشخص گلدنگیت پشت سرهم و با timestamp خروجی سرویس Extarct رو در Trail ها مینویسه حالا اگه این فایلها پر بشن میره یه فایل Trail جدید میسازه و اونجا ادامه کار رو جلو میبره (شما میتونید یک اندازه ثابت به Trail ها بدید)
اینکه گلدنگیت داره خروجی کار Extract رو بیرون دیتابیس قرار میده خودش یک مزیته مثلاً شما در نظر بگیرید ما در حال کار با دیتابیس مبدا هستیم و دیتابیسمون همنی لحظه کرش کنه این وسط هم دیتای ما به سمت دیتابیس مقصد به خاطر مشکل شبکهای نرفته اینجاست که میبینید اوراکل خیلی هوشمندانه عمل کرده چون با استفاده از همین Trailفایلها بعد برطرف شدن مشکلات میتونه دیتا رو تا آخرین نقطهای که در Trail فایلها هستش بخونه و اعمال بکنه پس ما data lost پایینی رو با استفاده از گلدنگیت تجربه میکنیم
نکته: چون گلدنگیت هیچ background process ای رو سمت دیتابیس اعمال نمیکنه پس باعث کرش دیتابیس نمیشه و کرش دیتابیس هم ارتباطی به سرویسهای سیستمعاملی گلدنگیت ندارند
نکته: میشه RMAN رو جوری تنظیم کرد که بعد از خوندن گلدنگیت آرشیو لاگها رو پاک کنه
خب این Trail Fileهای ما یکسری فایل سیستمی هستند که از بلاکهای سیستمعامل ما تشکیل شدهاند درون اون هم به سرعت شروع به نوشتن میکنه توی این Trail فایلها تغییرات دیتابیس مبدا که با سرویس Extract کپچر شدهاند و به صورت یک فرمت عمومی تبدیل شدهاند قرار میگیره
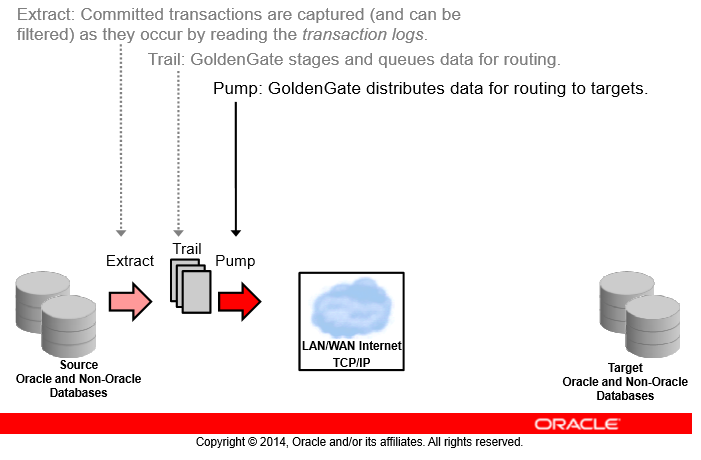
Pump
خب وقتی Trail File سمت سرور مبدا ساخته بشه بهش Extrail میگیم یا همون Extract Tril
تو یه معماری ما میتونیم بگیم که Extrail ها سمت مبدا ساخته نشه و سمت مقصد ما ساخته بشه (با دادن آدرس شبکهای در مسیر trail file)
تو این حالا ما میگیم RmTril یا Remote Tril ساخته شده تو این حالت اگه شبکه ما قطع بشه capture ما به مشکل میخوره و خروجی نمیتونه ذخیره کنه و اگه تو این قطعی شبکه یهو مبدا ما هم کرش بکنه دیگه ما دیتا رو نداریم
برای اینکه این مشکل رو نداشته باشیم از همین معماری Extrail استفاده میکنیم و یک سرویس pump (از جنس Extract) بالا میاریم
وظیفه این سرویس pump کردن trailها به سمت مسیر شبکهای که ما بهش دادیم هستش
در نهایت بعد از انتقال trailها در شبکه trilهای ما با سرویس pump در سمت مقصد ساخته میشوند
نکته: این Pump ما هیچ ارتباطی با فیچر Data Pump دیتابیس اوراکل نداره

Route
در این عملیات Route که به وسیلهی Pump انجام میشه دیتای ما فشرده و رمزنگاری میشه و میتونه هزاران تراکنش رو بدون محدودیت فاصله به شرط داشتن یک شبکهی stable در ثانیه منتقل بکنه همچنین این Trailهایی که ما با سرویس Pump در سمت مقصد ساختیم به RmTrail معروف هستن
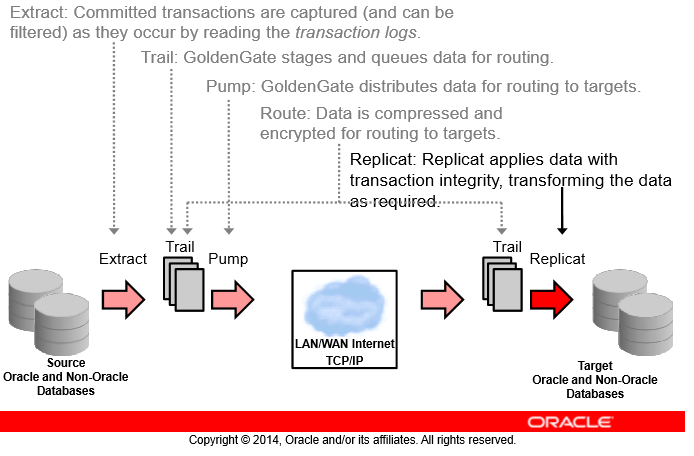
Replicat
این سرویس به Delivery هم شهرت داره و جنسش از کامپوننتهای Replicat گلدنگیت هستش
کار این سرویس اینه که RmTrail رو بخونه و روی مقصد اعمالش کنه این سرویس همیشه کارش همینه و فقط applie داده رو انجام میده و کار دیگهای انجام نمیده ولی کامپوننت Extract ما یا میتونه هم Capture بکنه و هم Pump
این کامپوننت در سمت سرور مقصد نصب و کانفیگ میشه و وقتی شروع به خوندن RmTrailهامون میکنه اونها رو به شکل SQLهای Native بر روی دیتابیس مقصد اعمال میکنه
گلدنگیت سناریوی Replicat Classic که دربارهاش صحبت کردیم رو به صورت Native در تمام پلتفرمهایی که پشتیبانی میکنه انجا میده پس سرعت بالایی در اینکار داره
با این حال اگه پلتفرم دیتابیس مقصد شما یکی از ورژنهای دیتابیس اوراکل باشه به صورت اختیاری میتونید عملیات apply رو به صورت direct بر روی دیسک انجام بدید و از SQL apply استفاده نکنید
نکته: تنهار سرویس اختیاری ما در این سناریو Pump هستش یعنی میتونیم با ایجاد کردن مستقیم RmTrail ها در سمت مقصد کارمون رو جلو ببریم پس اگه مسیر Trail ها رو در مبدا بهصورت لوکالی بدیم باعث این میشیم که به صورت اجباری سرویس Pump رو پیادهسازی کنیم.
نکته: Trail فایلها درسته با استفاده از بلاکهای سیستمعامل ساخته میشوند و از اوراکل بلاکها برای ساختشون استفاده نمیشه ولی با این حال تنها کسی که میتونه این فایلهای باینری رو بخونه گلدنگیت هستش
این کلیت فرآیند انجام مکانیزم گلدنگیت در سناریوی UNDIRECTIONAL هستش
نکته: ما تا الان باهم به این قاعده رسیدیم که هر سرویسی که خروجیش Trail فایل بشه از جنس Extract هستش و هر سرویسی که خروجیش باعث یک تغییری در دیتابیس بشه از جنس replicat هستش، اگه ببینیم Extract ما بخه یک دیتابیسی وصل شده و داره مستقیم توی یه مسیر شبکهای فایلها رو میکنه پس میفهمیم که تو این سناریو سرویس Pump نداریم و RmTrail فایلها توسط سرویس Capture ایجاد میشوند و اگه کانفیگ سرویس Extract ای رو باز کردیم و فهمیدیم سرویس به دیتابیسی وصل نمیشه و فقط آدرس یک مسیر شبکهای رو داره این سرویس Pump ما هستش، پیدا کردن سرویس Replicat هم که پیدا کردنش خیلی راحته چون حتماً باید به یک دیتابیسی وصل بشه و حتماً هم درونش یک maping ای وجود داره و چیزی رو capture یا pump نمیکنه درک این موضوع خیلی مهم و حساس هستش چون شاید درست الان مشکلی تو درک اینها نداشته باشید ولی بعداً که سناریوهای پیچیدهتری پیادهسازی کنیم و به مشکل بخوریم اینکه بدونیم کدوم سرویس به مشکل خورده خیلی مهمه
نکته: بهتره از یک استاندارد نامگذاری برای نامگذاری سرویسها استفاده بکنید مثلاً Extract اول(capture) ما اسمش همیشه با E شروع بشه یا pump ما اسم سرویسش همیشه با P شروع بشه یا اسم سرویس Replicat ما همیشه با R شروع بشه حالا اگه وارد سازمانی شدید که نامگذاریهاش اینجوری نبود باید براساس قاعده بالا بفهمید که کدوم سرویس از جنس Replicat هستش و کدوم سرویس از جنس Extract