SCN رو که یادتونه؟ همون بچهای که هر تغییری توی دیتابیس ما بخوره یکی میخوره تو سرش و Counter یکی میره بالا (حتی اگه time دیتابیس تغییر بکنه) خب یادمون هم هستش که redoها براساس SCNها هستن که در Online Redo Log Fileهای ما قرار میگیرند خب گلدنگیت خودش با SCN کاری نداره و بین سرویسهاش از مکانیزم دیگهای استفاده میکنه ولی موقعی که Extract میخواد فاز Capture رو شروع بکنه اینجاست که SCNهای دیتابیس رو میخونه و آخرین SCN خونده شده رو نگه میداره تا بدونه آخرین تغییری که خونده تا کجا بوده و اگه Gapای افتاد بتونه Gap رو برطرف بکنه خب گلدنگیت به محض اینکه SCN رو خوند و عملیات Capture رو انجام داد دیگه به SCN ما کار نداره

حالا اگه شما بخواین تو داخل مکانیزم گلدنگیت بین رکوردها جا به جا بشید باید با مفهوم RBA آشنا بشید (Relative Byte Address) یعنی ترتیبی که فایلهای capture ما در trail فایلها نوشته میشوند هر کدوم یک RBA میخورن و بر اساس این RBA این رکوردها از هم جدا و تفکیک میشوند
یکی از مزایای گلدنگیت اینه که میتونه چندین Trail فایل داشته باشه برای اینکار موقعی که نیازه Captureها اجرا بشوند باید یکسری Trail File ساخته بشوند که نام این فایلها توسط اوراکل به صورت ۸ کاراکتری در نظر گرفته میشه که ۲ کاراکتر اول توسط شما مشخص میشه مثلاً SH, SA, T1, L1 و ۶ کارکتر بعدی توسط اوراکل counter میخوره
اولین Trail فایلی که گلدنکیت برای شما میسازه با ۶ تا صفر پر میشه مثلاً: SA000000 دومین فایل یکی میره جلو SA000001 و ... به این ترتیب اگه ما فایلی به اسم SA000004 دیدیم یعنی ۵ تا Trail File ساخته شده
حالا توی هر Trail File ما RBA هربار 0 میشه و دوباره counter میخوره میره بالا پس RBA ها در هر فایل به صورت sequential بالا میروند و درکل Trail Fileها counter نمیخورند
نکته: پس RBA یه تفاوت بزرگ با SCN تو دیتابیس اوراکل داره اونم اینکه SCN هیچوقت دوبار 0 نمیشه ولی RBA در هر Trail File از اول شمارش میخوره
حالا فرض کنید ما یک تغییری در یکی از رکوردهای capture شده داشتیم و میخوایم رکوردی (Insert, Update, Delete = DML) رو به این علت که موقع capture به مشکل خورده پیدا کنیم اینجا گلدنگیت تو فایلهای لاگش میاد آدرس فایل Trail رو با شماره RBA ای که به مشکل خورده رو برمیگردونه مثلاً SEQ SA000006, RBA 1268954 درکل ما باید بتونیم این فایلهای لاگ گلدنگیت رو ترجمه بکنیم و به فایل و RBA مورد نظر برسیم حالا شما بعد از یکسری تغییرات میخواین بگید که سرویس capture دوباره از RBA اول فایل شروع به خوندن بکنه یا از Trail قبلی شروع به خوندن بکنه مثلاً SA000005 پس باید بیایم تو کانفیگ فایل Pump بگیم SEQ SA000005 بشه و RBA 0 باشه تا دوباره از اینجا شروع به Pumpبکنه
حالا اگه بیان به شما بگن که ما روی RBA 17589 به مشکل خوردیم شما نمیتونید کاری بکنید چون نمیدونید این RBA تو کدوم Trail File هستش پس اولین سوال تو ذهنتون اینه که به کدوم SEQ اشاره داره
نکته: سرویس capture ما با RBAها درگیری خاصی نداره چون این سرویس هستش که RBA ها رو میسازه پس RBA بیشتر در خوندن Pump معنی پیدا میکنه
Trail Format
 خب همونطوری که تو شکل بالا میبینید Trail Fileها یکسری فایل بدون ساختار هستند(تو معماری canonical format) که حاوی redoهای convert شده با طولهای متغیراند. فایلهای Trail برای ایجاد performance بهتر در بلاکهای بزرگ سیستمعاملی نوشته میشن
خب همونطوری که تو شکل بالا میبینید Trail Fileها یکسری فایل بدون ساختار هستند(تو معماری canonical format) که حاوی redoهای convert شده با طولهای متغیراند. فایلهای Trail برای ایجاد performance بهتر در بلاکهای بزرگ سیستمعاملی نوشته میشن
این فایل به ۲ بخش کلی تشکیل میشه:
- Record header area: اول فایل نوشته میشه و شامل اطلاعاتی راجع به فایل Trail امون هست
- Record data area: شامل یک header و یک بخش data هستش
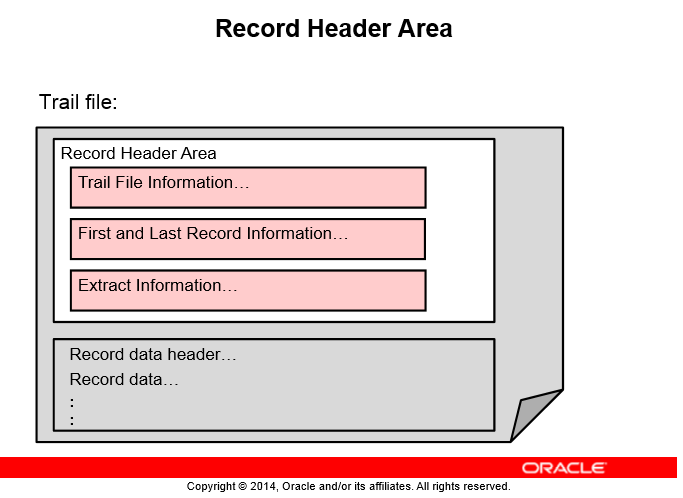
هر Trail File شامل بخشی هستش که header فایل رو نگهداری میکنه این بخش موارد زیر رو در برمیگیره:
- Trail File Information
- Compatibility level
- Character set - globalization function with version 11.2.1 and later
- Creation time
- File sequence number
- File size
- First and Last Record Information
- Timestamp
- Commit Sequence Number - CSN
- Extract Information
- Oracle GoldenGate version
- Group name
- Hostname and Hardware type
- OS type and version
- DB type, version, and character set
 فضایی که دادههای redo به صورت کانورت شده در اون قرار میگیرن بخش زیر هستش که شامل:
فضایی که دادههای redo به صورت کانورت شده در اون قرار میگیرن بخش زیر هستش که شامل:
- Trail record header
- The time that the change was written to the Oracle GoldenGate file
- The type of database operation - Insert, Update, Delete
- The length of the record
- The relative byte address(RBA) within the trail file
- The table name
- The data changes in hex format
- Optional user token area
نکته: معماری Trail Fileها توی حالت canonical خیلی مهمه چون شما میتونید این فایلها رو با ابزارهایی باز کنید و در موارد به خصوص از SEQها و RBAها استفاده بکنید
سناریو: فرض کنید Pump ما الان داره Trail File شماره ۶ و RBA شماره ۱۰۰ رو میخونه یه دستوری هستش که شما میتونید رکوردی که Pump از Trail داره میخونه و همچنین شماره Trail, RBA خروجی رو ببینید اینجا میبیندی نوشته Trail File شماره ۱۰۰ ساخته شده با RBA شماره ۱۰۰۰ به نظرتون اینجا چه اتفاقی افتاده؟ خب اینجا ورودی و خروجی Pump ما باهم یکسان نیستش و البته اصلاً موردی نداره چون محتوا یکی هستش و همون فایل رفته اونور و در حال نوشته ولی بنا به دلایلی مثلاً مشکل شبکهای یا دیسکی در سمت مقصد(مثلاً یه لحظه مشکل شبکه بوده فایل ساخته شده ولی از روش رد شده و یکبار counter seq رفته جلو) نتونسته Trail ها رو به موقع بنویسه و باعث ایجاد فایلهای dumpشده و counter اش بالا رفته پس روی اینها حساسیت نداشته باشید
نتیجه: counterهای ExTrailها با RmtTrail ها باهم یکی نیستش
CHECKPOINT
خب اگه سرویسها وسط کار down بشن چه اتفاقی رخ میده؟ اصلاً به نظرتون گلدنگیت متادیتاهای مربوط به سرویسها رو کجا نگه میداره (مثلاً capture اومده scn شماره فلان رو خونده و فلان TrailFile رو تا این RBA ساخته)؟ هر سرویسی یک فایلی به اسم checkpoint داره که این متادیتاها رو به عنوان checkpoint تو این فایلهای OSای نگهداری میکنه
همچنین سرویسها قابلیت این رو دارند که آخرین رکورد متادیتاهای خودشون رو در جدول ذخیره بکنن(برای اینکه سرعت خوندن از جداول بیشتر از فایل هستش)
Server Collector
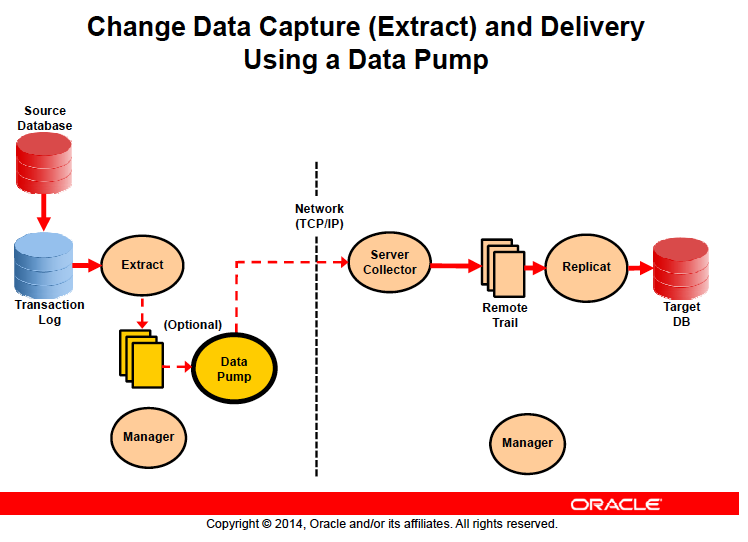
خب شکل بالا نمای کلی هرآنچه تا الان گفتم هستش، البته شاید یه جایی رو جا انداخته باشم خب صد البته اون بکگراند پراسس Server Collector هستش تا الان گفتم pump میاد دیتا از capture میگیره و خروجی Trail میسازه ولی در حقیقت به این شکل نیستش و Pump فقط دیتا رو برای مقصد روی شبکه ارسال میکنه پس یکی اونور تو سطح OS باید منتظر باشه که دیتا رو بگیره اسم این BG Server Collector یا همون Collector هستش عملاً این Collector هستش که خروجی Pump رو میگیره و RmtTrail هامون رو میسازه
البته به طور کلی شما متوجه کار این BG نمیشید به همین خاطر من قبلاً بهش اشاره نمیکردم ولی واقعیت موضوع به این شکل هستش
Collector ما وقتی بالا میاد که گلدنکیت ما حتماً در Target بالا اومده باشه یا به عبارت دیگه Manager ما بالا اومده باشه
Manager

خب حالا که با اجزای کلی آشنا شدیم بهتره بدونیم هر گلدنگیتی که توی هر سروری نصب میشه یک نوع سرویس از جنس Manager داره این سرویسها کارشون اینه که مدیریت باقی سرویسها رو انجام بدن این سرویس کاری با RBA و دیتا نداره فقط کارش اینه که حواسش به وضعیت باقی سرویسها باشه که بالا هستند یا به خطا خوردهاند. البته یکی از وطایف مهم این سرویس این هستش که بررسی کنه آیا پورتهای لازم باز هستند یا نه.
مثلاً گفتیم Pump وظیفهاش اینه که trailها رو به سمت سرور مقصد با استفاده از شبکه بفرسته خب Pump داره از یه کانفیگی استفاده میکنه که ما اونجا یه ip, port ای رو مشخص کردیم ip که مشخصه ولی port چی؟ خب میدونیم که هر پکیجی که بخواد تو شبکه حرکت بکنه احتیاج به یه ip, port داره و نیازه این port در سمت سرور مقصد باز باشه پس باید یه سرویسی سمت سرور مقصد باشه که به این پورت گوش بکنه، اگه سرویسی روی این پورت شروع به گوش کردن نکنه میگیم اون پورت اصلاً establish نشده
خب سرویسای که سمت مقصد بالا میاد پورت رو باز میکنه Manager هستش که بعد از باز کردن میاد سرویس collector رو صدا میزنه تا به این پورت گوش بده و دیتای pump رو در RmtTrailها بنویسه
پس نتیجه میگیریم اگه سرویس Manager ما بالا نباشه هم collector ما کار نمیکنه هم پورتمون بسته است
خود اوراکل این سرویس رو به صورت زیر شرح میده:
Manager processes on both systems control activities such as starting, monitoring, and restarting processes; allocating data storage; and reporting errors and events.
نکته: یه موقعهایی پیش میاد میبینیم pump ما شبکهاش برقراره و مشکلی از بابت شبکه نداره ولی Trailها به سمت سرور مقصد نمیرند اینجاست که اولین چیزی که باید چک بکنیم سرویس Manager در سمت سرور مقصده که اصلاً بالا هستش یا نه