خب فکر کنید ما نیاز داریم join چند جدول از مبدا رو در یک جدول در دیتابیس مقصد بنویسیم خب در گلدنگیت برای این مورد ما باید شروع به نوشتن اسکریپتنویسی با REM کنیم که جزو موارد advanced گلدنگیت محسوب میشه، البته شما میتونید از یه راهکار به مراتب سادهتر اسفاده کنید اونم اینکه جداول مورد نیازتون رو بدون join بیارید به سمت سرور مقصد و روی جدول آخری که میخواد آپدیت بشه شما یک Triger مینویسید که وقتی ۲ تا رکورد از ۲ جدول اومدن join بزنه و روی جدول نهایی بنویسه پس تا stage io رو با گلدنگیت جلو میاریم و از Stage I/O به DWH رو با تریگر جلو میبریم بعد شما چون فقط یک تریگر روی جدول آخر دارید performance بالایی خواهید داشت.
قابلیتها
Filtering

ما برای تمام سرویسها تو گلدنگیت یکسری قابلیت عمومی داریم مثلاً میتونیم برای سرویس capture مشخص کنیم که فقط یک schema رو منتقل بکنه که همهی دیتابیس رو capture نکنه یا اینکه میتونیم این فیلترینگ رو تا سطح table, filed و حتی با where جلو ببریم
حتی توی pump هم میتونیم اینجوری بگیم که سرویس capture همه چیز رو بگیره ولی pump تو همه رو برندار و فقط تغییرات یکسری از جداول یا schema ها رو ببر اونور یا حتی میشه گفت که روی این جدول اگه فلان کاربر تغییری داد pump حق نداری تغییرات رو ببری اونور(exclude) و اینجوری میتونیم به تکتک رفتارهای کاربر سناریو رو bund کنیم.
قابلیت Filtering در تکتک سرویسهای گلدنگیت قابل پیادهسازی هستش مثلاً capture, pump ما به طور کامل تغییرات رو بردن سمت target حالا ما توی سرویس delivery میایم میگیم نیازی نیست تو تمام دیتا رو apply کنی فقط ۱۰ درصد داده رو apply کنی کفایت میکنه البته این سناریو منطقی نیست چون از همون اول میتونستیم بگیم فقط ۱۰ درصد داده رو capture کنه تا trail فایلهای کوچکتری هم ساخته بشه و از شبکه کمتر استفاده بشه اما در کل این قابلیت هستش مثلاً فرض کنید ما ۲ تا دیتابیس در target داریم و روی یکی فقط بخوایم ۱۰ درصد داده رو اعمال بکنیم و روی یکی بخوایم داده رو به صورت full وارد بکنیم پس این قابلیت باعث میشه انعطاف پذیری شما بالا بره در طراحی سناریو
Comparison

با این قابلیت میتونیم به سرویس extarct, capture امون بگیم هرچیزی رو که capture کردن خروجی رو به صورت فشرده شده در trail فایلها قرار بده یا مثلا به pump میگیم موقع فرستادن trailها به target برای ساختن RmtTrailها به صورت فشرده شده اینکار رو انجام بده پی اینجا ما فشردهسازی رو در سطح شبکه انجام دادیم و پهنای باند کمتری رو استفاده میکنیم
Oracle Advanced Compression
راهحل بسیار عالی برای کم کردن حجم یا بهبود performance دادهها در سطح دیتابیس اوارکل، حالا به نظرتون compression چجوری performance رو بهتر میکنه؟ موقعی که ما یه BUS برای خوندن دیتا مصرف میکنیم و در حالت عادی مثلاً 10K داده برمیگشت با فشردهسازی داده ما دیتای بیشتری رو برمیگردونیم یعنی IO ما پایین میاد و CPU Usageامون بالا میره چون وقتی میخواد decompress کنه نیاز به CPU Usgae داره ولی چون همیشه تو دیتابیس ما Cost CPU رو به Cost IO ترجیح میدیم پس استفاده از این سولوشن خیلی کاربردی هستش
یکی از راهکارهای پیشنهادی SAP برای بهبود performance دیتا در محصول ERPاش استفاده از Oracle Advanced Compression هستش با همین راهکار ما یک جدول ۱ ترابایتی رو به یک جدول ۴۰۰ گیگابایتی رسوندیم
این سولوشن اوراکل در چند لایه کار میکنه یکی روی خود جداول و ایندکسها که میتونید متدهای مختلفی رو براش انتخاب کنید (مثلاً فشردهسازی برای Archive, OLTP, ...) یه بحث دیگهاش توی lg shipping سناریوی گارد هستش مثلا شما گارد با نیشابور راهاندازی کردید خب این گارد خودشو با لاگها sync نگه میداره و ما با این مکانیزم فشردهسازی اوراکل میتونیم لاگهامون رو فشرده کنیم تا پهنای باند کمتری مصرف بشه
یه نوع فشردهسازی دیگه که توی Oracle Advanced Compression معرفی میشه بحث Secure File هستش، وقتی شما از BLOB, CLOB استفاده میکنید مثلاً اسکن یک نامهای رو در دیتابیس به صورت باینری قرار میدهید و کاربر دیگهای هم همین فایل رو عیناً در دیتابیس قرار میده حالا فکر کنید ۱۰۰۰ تا کاربر دارید و این duplicate داده زیاد میشه ولی وقتی از Oracle Advanced Compression بر روی Secure Fileها استفاده میکنید میاد موقع insert داده hash code دیتاها رو در میاره و حواسش به این hash codeها هست و اگه کاربر دیگهای همین دیتا رو وارد کنه دیگه همون دیتا رو وارد نمیکنه و pointer به جاش میذاره (البته توجه کنید اگه hash code فایل تغییر کنه دیگه این اتفاق نمیوفته)
به این حالت فشردهسازی عمودی میگن خوبه بدونید ما یه فشردهسازی افقی هم داریم یعنی خود فایل باینری به صورت فشرده در دیتابیس ذخیره بشه
فقط یه نکته در گلدنگیت داره اگه شما Compressionدر سناریوی Capture Classic راهاندازی بکنید شما به مشکل میخورید چون گلدنگیت تو این ورژن(12C) به مشکل میخوره ولی اگه اصرار داشتید این سولوشن رو راهاندازی بکنید باید از سناریوهای integrate captureاستفاده بکنید
امنیت

رمزنگاری پسورد کاربر دیتابیس
تا الان فهمیدید که captureهای ما با یکسری file config انجام میشوند خب یکی از این کانفیگها نامکاربری و پسورد دیتابیس هستش که براساس این نام کاربری و پسورد گلدنگیت میاد به source امون وصل میشه و دیتا رو capture میکنه پس هرکی این فایل رو بتونه باز کنه پسورد کاربر دیتابیس گلدنگیت رو هم میفهمه خب پسورد کاربری که به گلدنگیت وصل میشه هم دسترسیهای کمی نداره پس هرکسی میتونه با این کاربر لاگین بکنه و وارد دیتابیس بشه
خب اینجا اولین مسئله امنیتی به وجود میاد که راهکار اوراکل برای این مسئله رمزنگاری این پسورد هستش شما باید یک key تولید بکنید و براساس این کلید رمزنگاری رو انجام بدید و این کلید رو به عنوان یک فایل در محلی از پیش تعیین شده قرار بدهید تا اوراکل بدونه براساس چه کلیدی باید دیتا رو decrept بکنه
اینجا شما باید رشته decrept شده پسورد رو در file config بذارید تا اینجوری فقط گلدنگیت بتونه این رشته رو از حالت رمز خارج بکنه
رمزنگاری فایلهای Trail
بحث دوم موقع ساخت trail file ها هستش چون در آخر خود این trailها خودشون فایل os ای میشن(چون از بلاکهای os برای ساختشون استفاده میشه) که اگه تو os با notepad باز کنیم حتما میتونید یکسری از رشتهها رو بفهمید
حالا ما میخوایم کسی نتونه این trailها رو باز کنه یا اینکه اگه این trailها دست کسی افتاد نتونه با نصب یک گلدنگیت و شبیهسازی سناریو این فایلها رو بخونه و استفاده بکنه
پس ما نیاز داریم خود trail fileها رو هم رمزنگاری کنیم گلدنگیت به ما این امکان رو به صورت کامل میده که اینکار رو انجام بدیم
رمزنگاری کل فایل Config
بحث سوم خود file config سرویس capture هستش (به غیر از رشته پسورد یعنی کل فایل) که نیاز رمزنگاری بشه
سناریو رمزنگاری
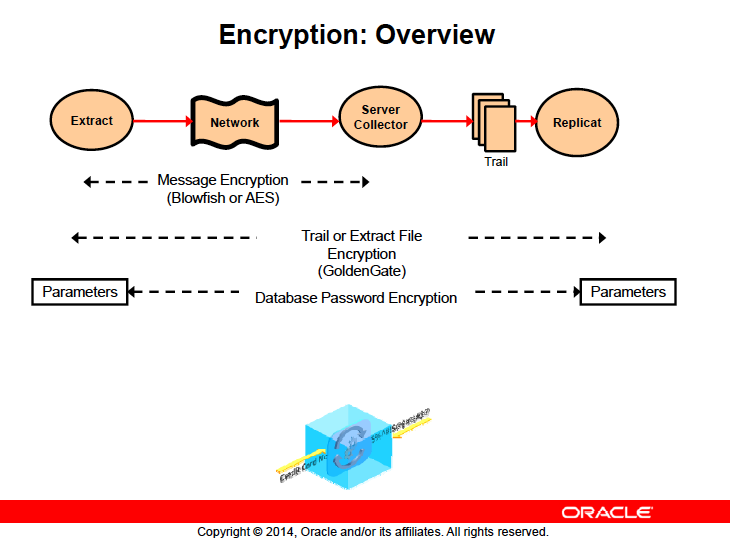
حالا چه اتفاقی میوفته فرض کنید ما پسورد سرویس capture رو رمزنگاری کردیم حالا خود گلدنگیت باید این رشته رو برداره و از حالت رمز خارج بکنه تا بتونه به دیتابیس وصل بشه
بعد از اینکه تغییرات capture شد میاد توی trail fileها و رمزنگاری رو برای trail file ها انجام میده حالا pump باید بیاد و این trail ها رو بخونه و ببره اونور بسازه پس اولین کاری که باید در pump انجام بشه decrypt کردن فایلهای رمز شده trail هستش و اینجا اگه بخوایم فایلها به صورت رمز شده در شبکه فرستاده بشن باید به سرویس pump بگیم که این فایلها رو encrypt بکن و توی شبکه بفرست در نهایت سرویس relicat هم باید این فرآیند رو برعکس بره یعنی فایلها رو decrypt بکنه پس اگه ما encryption رو تو سرویسها راهاندازی کردیم باید تو سرویس replicat هم decryption رو انجام بدیم