ما یک RAC سه نود رو نگهداری میکنیم. به طور معمول کوئریهای سنگین ما از نظر زمان اجرا خیلی باهم متفاوت هستند. به این علت که حجم دیتای بیزنس ما زیاد و دارای نوسان زیادی است در دیتای ما واریانسهای طبیعی زیادی وجود داره. با این حال خیلی از بلاکهای این نوسانها تا حدی توی حافظه RAC قرار دارند.
من یکسری تستها انجام دادم که یه رخدادی رو به من نشون میده که میتونم اون رو به عنوان یک مشکل غیر منتظره در وبلاگم ثبت کنم.
تسک ما اجرای یک کوئری با چندین join هستش که باعث ایجاد هش جویان های زیادی در سیستم میشه
مشکل ما این بود که تاخیرهای مرتبط با گرفتن دیتا با Full Table Scan از روی دیسک کمتر از گرفتن دیتا از روی شبکه interconnect بود. در حقیقت به این معنی که همه بلوک ها روی node ای قرار میگیرند که از همه دورتر است پس wait های GC CR MULTIBLOCK REQUEST به مقدار زیادی بالا بودند.
میانگین waitهای scattered-read من به طور معمول ۸ میلی ثانیه و میانگین waitهای GC CR MULTIBLOCK REQUEST به طور معمول ۲۱ میلی ثانیه بود.
اگر هرکدام از جدول ها توسط یک کوئری از قبل فراخوانی شده بودند، یا کوئریهای مشابه در همان روز از دیتابیس گرفته شده باشد و در نتیجه اوراکل محتوای جدول را در نود far-side (دورترین نود - نود ۳) قرار داده باشه اونوقت hash joinهای ما ۴۵ دقیقه طول میکشه و توسط wait ما (GC CR MULTIBLOCK REQUEST) محاصره میشه
حالا اگه هر نود ما alter system flush buffer cache رو اجرا کنه که در نتیجه اتفاق خواندن از دیسک انجام میشه اونوقت همون کوئری وقتی دوباره اجرا بشه ۵ دقیقه طول میکشه و ایندفعه توسط wait ای به نام scattered/sequential read محاصره میشه
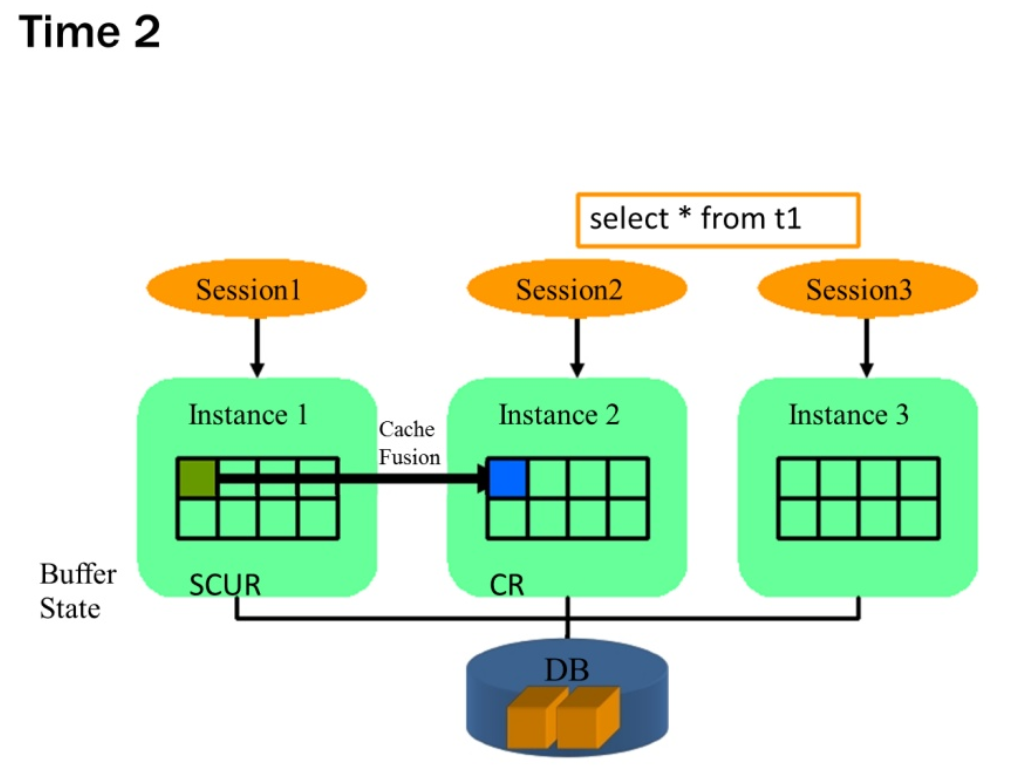
خواننده گرامی قبل از ادامه کار شما باید با Cache Fusion در RAC و مفاهیم Past Image و انواع Waitها در RAC آشنایی داشته باشید. سعی میکنم در مقاله های بعدی به این موضوعات بپردازم.
وقتی اوراکل بلوک های درخواست شده رو از نود دور (far-side) به نود نزدیک (near-side) منتقل میکنه با فرض اینکه همه چیز به شکل صحیح پیکربندی شده باشه کلاستر اوراکل از شبکه private استفاده میکنه.
حقیقتاً به نظر من ۲۱ میلی ثانیه خیلی طولانی میاد بیشتر سیستم هایی که من دیدیم یا درباره اونها تحقیق کرده ام خوندن اطلاعاتشون بین ۸ تا ۱۰ میلی ثانیه طول میکشه در کل خوندن بلاک از interconnect باید کمتر از چند میلی ثانیه طول بکشه به عنوان یک اصل کلی این عدد برای سلامت RAC اوراکل بیش از حد مهم و بالاست هستش.
سوالی که برای من پیش میاد اینه که تحت چه شرایطی ممکنه wait یک کوئری با GC CR MULTIBLOCK REQUEST بیشتر از waitهای scattered-read باشه؟ (به عبارت دیگه چرا ممکنه انتقال بلوکها از طریق interconnect بیشتر از انتقال از طریق disk طول بکشه؟)
خب در جواب سوال باید بگم مقایسه بین انتقال اطلاعات در CR global cache بین نودها با خواندن از روی دیسک مثل مقایسه هویج و بادمجون ه.
یادمون باشه تحت خیلی از شرایط ممکنه این مشکل پیش بیاد اول از همه اینکه پیکربندی شبکه برای private امون چیه؟ آیا از اترنت گیگابیت استفاده میکنیم؟ (در کل بهتره از یک شبکه 10G یا Infiniband استفاده کنیم). آیا این شبکه private واقعا private ه یا شخص دیگه ای هم توی شبکه است؟ (در صورت شلوغی این شبکه خود این شبکه ممکنه باعث این چنین مشکلاتی بشه)
اوراکل توصیه میکنه حتما از jumbo frame برای این شبکه استفاده بشه خب با پیگیری های فراوان قبلاً در شبکه ما jumbo frame پیکربندی شده بود و این رخداد به تازگی و بدون تغییر در بیزنس اپلیکیشن رخ داده بود.
خب در ادامه باید بگم اوراکل در انتقال CR Global Cache یک read image واحد درخواست میکنه اونم به خاطر این که یک تراکنش ممکنه یک تغییری در بلوکی که در instance دیگه وجود داره ایجاد کنه پس ما نیاز به خوندن یک ایمیج واحد داریم
ایمیج برداشته شده از روی دیسک در صورتی که هنوز commit نشده باشه همچنان نیاز داره که با session درخواستی به دیتابیس هماهنگ بشه پس تغییراتی که هنوز commit نشدند باید قبل از اینکه session بتونه ازشون استفاده بکنه rollback بشوند.
در غیر این صورت ایمیج برداشته شده از روی دیسک یک بلوک current هستش که در این مورد ایمیج همونطور که هست و بوده در اون instance استفاده میشه و در مقیاسه با به دست آوردن ایمیج CR کار کمتری مورد نیازش هست و بار کمتری ایجاد میکنه (چون ایمیج CR باید به صورت منسجم از نودها فراخوانی بشه)
با تمام این توضیحات مشکل رو یا باید در شبکه جستجو میکردم یا در پیکربندیهای اخیر - با این توضیح که قبلاً چنین مشکلی وجود نداشت و تستهای انجام شده بر روی شبکه مشکلی رو نشون نمیداد سراغ پارامتر UNDO_RETENTION رفتم
یک توضیحی باید بدم که من برای گرفتن export از یکی از جداولمون که سایز بسیار زیادی داره (بیش از ۳ ترابایت) این پارامتر رو روی ۷ روز تنظیم کرده بودم
خب وقتی به یاد این پارامتر افتادم فهمیدم مشکل کجاست چون همین پارامتر قطعاً در رفتار کلاستر تفاوت ایجاد میکنه - مقدار من برابر ۷ روز بود پس دیتاها توی اینتنس ۱ لود شده و برای مدت طولانی در آینده گرفته میشوند اگه یک کوئری توی اینستنس ۲ اجرا بشه اوراکل ممکنه تصمیم بگیره که نیاز به یک read image منسجم داره ... خب همونطور که میدونید بازسازی مجدد بلاک مقداری زمان میبره به ویژه اگه حجم عظیمی از تغییرات در undo وجود داشته باشند چیزی که گیج کننده بود اینه که تراکنشی که تغییر رو ایجاد کرده باید تا الان وضعیت اش مشخص شده باشه پس به جای بلوک CR باید یک بلوک current درخواست میکرد ولی از اونجایی که بلوک CR به دفعات درخواست شده بود این موضوع نشون میده که تغییرات جداول مرتبط هنوز commit نشده بودند.
در نهایت با پایین آوردن مقدار این پارامتر به عدد دیفالت (۹۰۰) یا همون ۱۵ دقیقه این مشکل رو حل کردم.

زمانی بلاک از undo فراخوانی میشه که trans کامیت نشده باشه. و اگه رو یه ins تغییر کامیت نشده باشه و رو یه instance دیگه درخواست داده بشه gc میخوره.
حالا سابقه تغییرات بلاک تا 1000 روز هم تو undo باشه تاثیری نداره...
مگه شما trans هایی داشته باشید که چندین روز کامیت نشوند.