یکی از بهترین کتابهای موجود برای یادگیری عملی محصول Oracle GoldenGate کتاب Oracle GoldenGate 11g Implementer's guide نوشته شده توسط John P. Jeffries و انتشار یافته توسط انتشارات packt است.

یکی از بهترین کتابهای موجود برای یادگیری عملی محصول Oracle GoldenGate کتاب Oracle GoldenGate 11g Implementer's guide نوشته شده توسط John P. Jeffries و انتشار یافته توسط انتشارات packt است.
اول از همه یادمون باشه ما دیتابیس اوراکلی رو میتونیم به حالت آرشیو ببریم که وقتی دیتابیسامون رو shutdown میکنیم تا به حالت mount برسیم instance recovery ای اتفاق نیوفتد یعنی لازمه حتما SCNها یکی شده باشند.
پس اگه ما shutdown abort کنیم و رو حالت mount ببریم و بخوایم دیتابیس رو به حالت آرشیو ببریم امکانش وجود نخواهد داشت.
دیتابیس رو shutdown میکنیم:
SQL> shut immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
دیتابیس رو به حالت mount میبریم:
SQL> startup mount;
ORACLE instance started.
Total System Global Area 1653518336 bytes
Fixed Size 2253784 bytes
Variable Size 1543506984 bytes
Database Buffers 100663296 bytes
Redo Buffers 7094272 bytes
Database mounted.
دیتابیس رو روی حالت آرشیو میذاریم:
SQL> alter database archivelog;
Database altered.
حالا دیتابیس رو open میکنیم تا instance تشکیل بشه
SQL> alter database open;
Database altered.
برای چک کردن این موضوع که دیتابیس ما تو حالت آرشیو لاگ هستش یا نه از دستور زیر در SQLPLUS استفاده میکنیم:
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 109
Next log sequence to archive 111
Current log sequence 111
خب همونطور که میبینید مکانیزم آرشیو لاگ در این سرور فعال هستش و مقصد ذخیره آرشیوها در پارامتر db_recovery_file_dest تنظیم شده که اینجا همون فضای FRA ما هستش
حالا اگه یک Switch Logfile دستی بزنیم مشاهده میکنیم Online Redo Log File ما آرشیو شده
SQL> alter system switch logfile;
System altered.
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 110
Next log sequence to archive 112
Current log sequence 112
خب تا حالا داشتیم سناریوی Unidirectional رو باهم مرور میکردیم نوبتی هم باشه نوبته معماری Bidirectional هستش
خب فکر کنید ما نیاز داریم join چند جدول از مبدا رو در یک جدول در دیتابیس مقصد بنویسیم خب در گلدنگیت برای این مورد ما باید شروع به نوشتن اسکریپتنویسی با REM کنیم که جزو موارد advanced گلدنگیت محسوب میشه، البته شما میتونید از یه راهکار به مراتب سادهتر اسفاده کنید اونم اینکه جداول مورد نیازتون رو بدون join بیارید به سمت سرور مقصد و روی جدول آخری که میخواد آپدیت بشه شما یک Triger مینویسید که وقتی ۲ تا رکورد از ۲ جدول اومدن join بزنه و روی جدول نهایی بنویسه پس تا stage io رو با گلدنگیت جلو میاریم و از Stage I/O به DWH رو با تریگر جلو میبریم بعد شما چون فقط یک تریگر روی جدول آخر دارید performance بالایی خواهید داشت.

SCN رو که یادتونه؟ همون بچهای که هر تغییری توی دیتابیس ما بخوره یکی میخوره تو سرش و Counter یکی میره بالا (حتی اگه time دیتابیس تغییر بکنه) خب یادمون هم هستش که redoها براساس SCNها هستن که در Online Redo Log Fileهای ما قرار میگیرند خب گلدنگیت خودش با SCN کاری نداره و بین سرویسهاش از مکانیزم دیگهای استفاده میکنه ولی موقعی که Extract میخواد فاز Capture رو شروع بکنه اینجاست که SCNهای دیتابیس رو میخونه و آخرین SCN خونده شده رو نگه میداره تا بدونه آخرین تغییری که خونده تا کجا بوده و اگه Gapای افتاد بتونه Gap رو برطرف بکنه خب گلدنگیت به محض اینکه SCN رو خوند و عملیات Capture رو انجام داد دیگه به SCN ما کار نداره

حالا اگه شما بخواین تو داخل مکانیزم گلدنگیت بین رکوردها جا به جا بشید باید با مفهوم RBA آشنا بشید (Relative Byte Address) یعنی ترتیبی که فایلهای capture ما در trail فایلها نوشته میشوند هر کدوم یک RBA میخورن و بر اساس این RBA این رکوردها از هم جدا و تفکیک میشوند
یکی از مزایای گلدنگیت اینه که میتونه چندین Trail فایل داشته باشه برای اینکار موقعی که نیازه Captureها اجرا بشوند باید یکسری Trail File ساخته بشوند که نام این فایلها توسط اوراکل به صورت ۸ کاراکتری در نظر گرفته میشه که ۲ کاراکتر اول توسط شما مشخص میشه مثلاً SH, SA, T1, L1 و ۶ کارکتر بعدی توسط اوراکل counter میخوره
بعد از اینکه با معماری اوراکل خوب آشنا شدید و شناخت این موضوع که اوراکل گلدنگیت کجای سازمان ما میتونه باشه و چه راهکارهایی رو میتونه به ما ارائه بده به معماری خود گلدنگیت میرسیم. در کل همین اول کار بهتره بدونید گلدنگیت عملاً از یکسری سرویس تشکیل شده یعنی اینکه اگه فکر میکنید اپلیکیشن گرافیکی هستش و دیتابیسی پشتش قرار میگیره نه این اتفاق در گلدنگیت صورت نمیگیره.
گلدنگیت در اصل یکسری سرویسه اینکه من تو پستهای قبلی همش تاکید میکردم ما CDC داریم این سرویسها هستن که اینکار رو انجام میدن و تغییرات رو میفهمن و تو شبکه جا به جا میکنن و در نهایت اعمال میکنن یا باز همین سرویسها هستن که منتظر تغییرات میمونن و به محض دریافت اونها رو اعمال میکنن و خودشون رو SYNC نگه میدارن درکل ما با یکسری سرویس سر و کار داریم و تمام فعالیتهای ما هم روی همین سرویسهاست حالا این سرویسها هر کدوم برای خودشون آرگومانهایی دارند که ما Config Fileهای موجود آرگومانهای مختلفی رو براشون در نظر میگیریم و در نهایت این کانفیگها هستن که شما با اونها بسیار کار دارید.
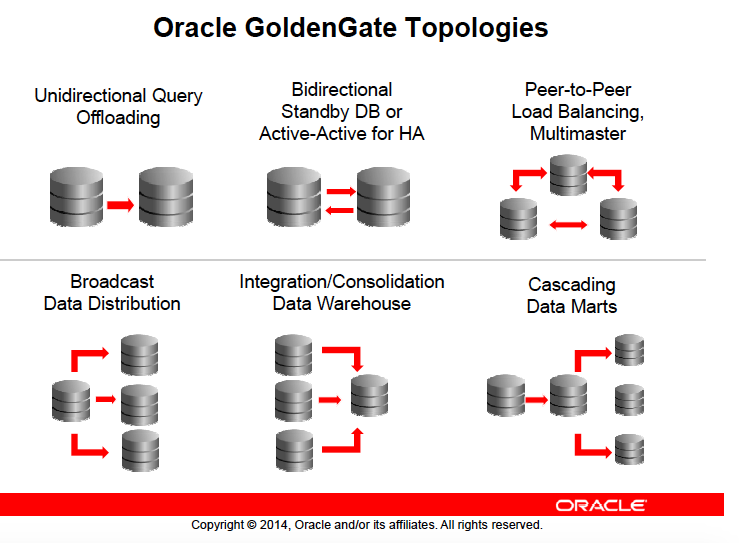
سناریوهای قابل پیادهسازی در گلدنگیت
 - DB: database
- DB: database
- EDW: Enterprise Data Warehouse
- ETL: Extract, Transform, and Load
- HW: Hardware (Intel 32-bit, Intel 64-bit, SPARC, and so on)
- ODS: Operational Data Store
- OLTP: Online Transaction Processing
- OS: operating system (Linux, Windows, and so on)
خیلی مهمه برای درک معماری گلدن گیت معماری اوراکل رو خوب بلد باشیم، برای مطالعه معماری اوراکل 11g میتونید از لینکهای زیر استفاده کنید
نگاهی بر معماری Oracle Database 11g - قسمت اول
نگاهی بر معماری Oracle Database 11g - قسمت دوم
نگاهی بر معماری Oracle Database 11g - قسمت سوم
مهمترین بخش معماری که باید برای گلدنگیت خوب بلد باشید شکل زیر هستش:
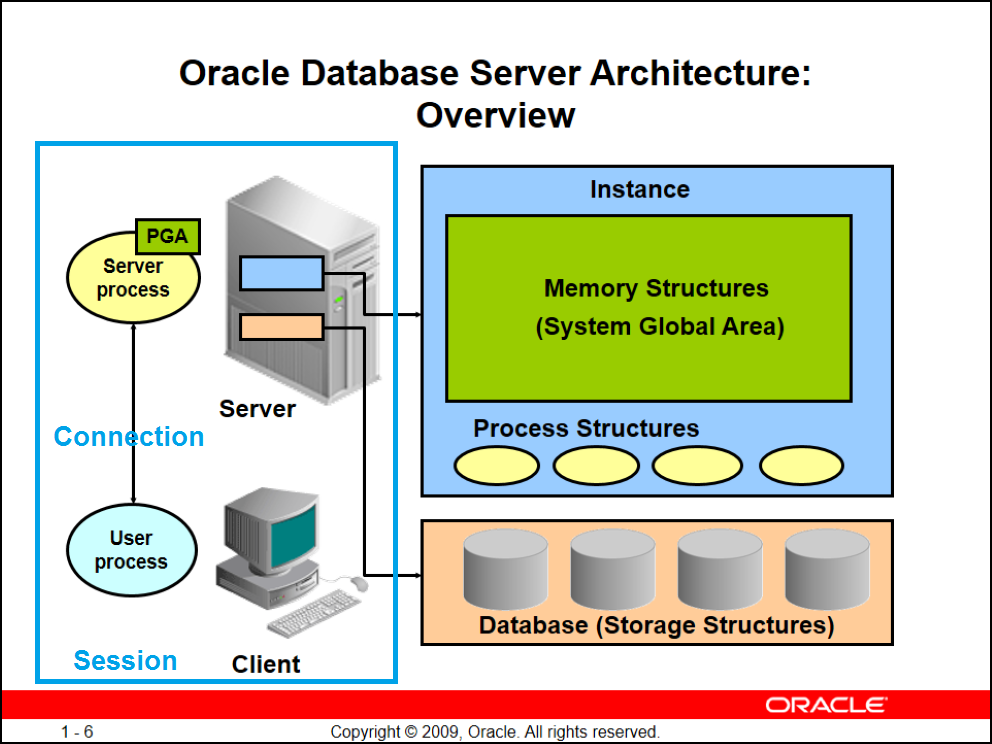
خب میخوام معماری اوراکل رو به صورت سناریو بیس و خلاصه دوباره دوباره تکرار کنم چون مسلط بودن به این معماری از ضروریات کاره
گلدن گیت ۲ نوع معماری کلی داره:
در این سناریو گلدن گیت وابسته به ورژن باینری خودش بر روی پلتفرم مورد نظر هستش و گلدن گیت باید کنار هر دیتابیس در سرور مبدا و مقصد نصب بشود
در این معماری گلدن گیت بر روی یک سرور در کنار یک دیتابیس نصب میشه و با agentهایی دیتابیسها باید logهای خودشون رو به این سرور ارسال کنند و capture (بازکردن لاگها) در سرور گلدن گیت انجام میشه. مثلاً شما میتونید گلدن گیت رو بر روی یک سرور لینوکسی نصب و راهاندازی کنید و ریپلیکیشن بین دیتابیسهای سرورهای ویندوزی راهاندازی کنید.
اگر سرور گلدن گیت با یکی از دیتابیسها یکی باشه بهش integrate capture میگن ولی اگه کلاً سرور گلدن گیت جدا از سرورهای دیتابیس باشه بهش integrate capture downstream میگن
نکته: یادمون باشه مبنای سناریوی integrate کلاً انجام عملیات logminer هستش
-- توپولوژیهایی که GG میتونه برای ما ساپورت بکنه به صورت کلی شکل زیر هستش راجع به هر توپولوژی من یک توضیح مختصری میدم:
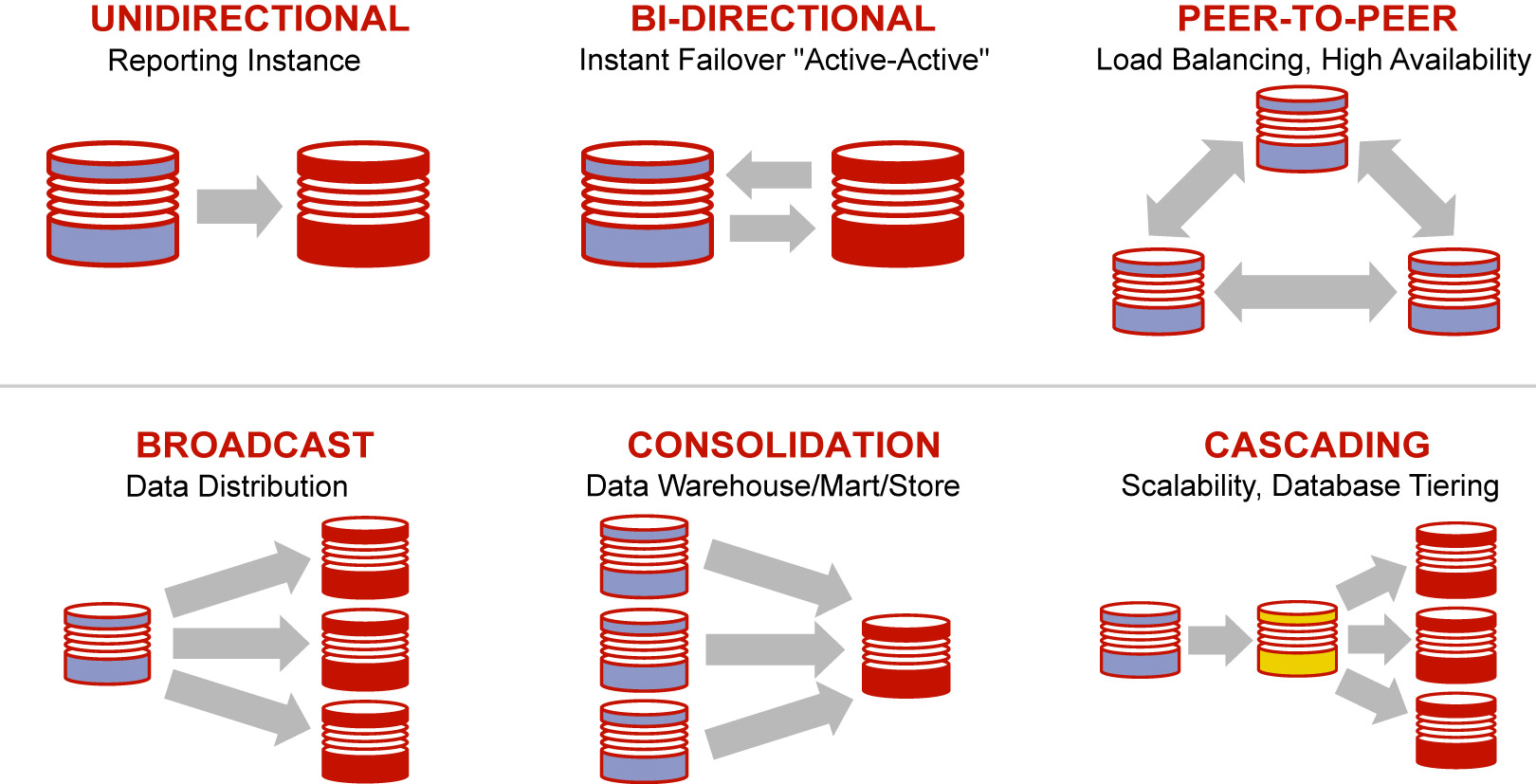
سناریو
به عنوان DBA یک بانک که در ایران و اروپا دفتر دارد مشغول کار هستید. بانک شما ۲ تا دیتابیس اوراکل 12C مجزا بر روی دو container مجزا در دفاتر اصلی خود دارد. شما نیاز دارید که برخی از جداول را از اسکیمای IR به اسکیمای EURO ببرید برای رسیدن به این هدف میتوانید Oracle GoldenGate for Oracle 12c را امتحان کنید.
شما برای امتحان حتماً دارید از یه محیط توسعه و آزمایشی استفاده میکنید (جدا از نگرانیهای محیط عملیاتی) که این محیط آزمایشی میتونه روی یه PC هم باشه ولی یادمون باشه در محیط عملیاتی دیتابیس EURO و IR از هم جدا هستند.
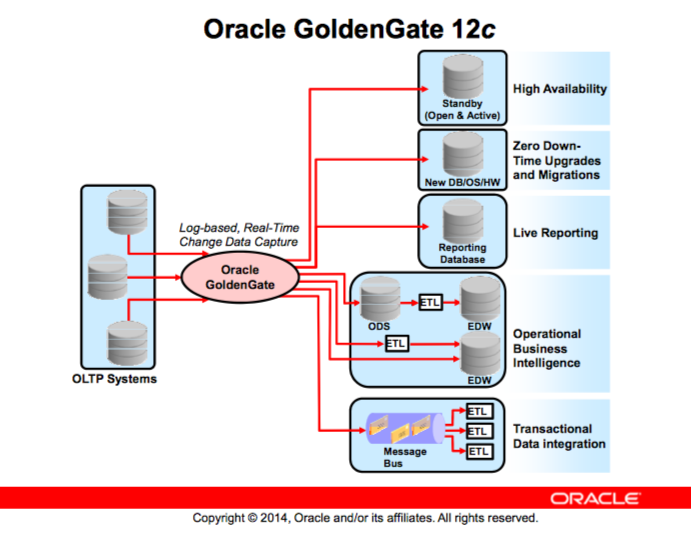
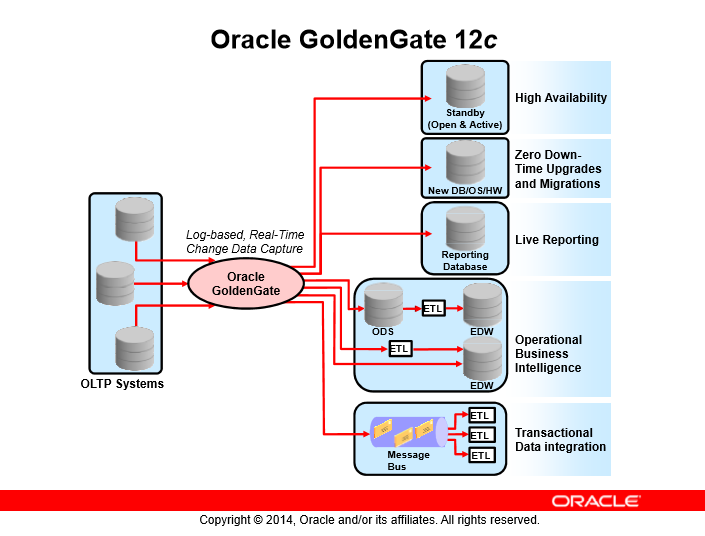
اوراکل گلدنگیت یکی از محصولاتیه که تاثیرات خیلی کمی موقع کپچر اطلاعات(capture)، مسیریابی(routing)، تفییر اطلاعات(transformation) و انجام تراکنشهای مختلف در پایگاهدادههای مختلف داره تقریباً زمانی نزدیک به زمان بیدرنگ
اوراکل گلدنگیت تبادل و تغییر دادهها رو در سطح پایگاهدادههای مختلف و سیستمعاملهای مختلف به صورت بیدرنگ انجام میدهد همچنین یکپارچگی تراکنشها رو با زمان تاخیر خیلی کم نزدیک به بیدرنگ انجام میدهد.
همچنین قابلیت پیادهسازی سولوشنهای high availability و zero down time برای انواع upgrades یا migrations و live reporting و operational business intelligence و transactional data integration را به ما میدهد.
