به اطلاعات زیر دقت کنید:
| نام | فامیل | شهر |
| مهدی | غفاری | تهران |
| احسان | جلالی | تهران |
| فرزاد | کارخانی | تهران |
تعریف داده(Data): به موجودیت مهدی یا جلالی یا تهران داده میگویند.
تعریف فیلد(Field): به موجودیتی که درون خودش داده رو ذخیره میکنه فیلد میگویند. مثل: نام، فامیل، شهر
تعریف رکورد(Record): به مجموعهای از دادهها که در کنار هم قرار بگیرن و یک موجودیت رو تفسیر کنن رکورد میگویند. مثل: مهدی غفاری تهران که مهدی غفاری رو تفسیر میکنه
تعریف جدول(Table): به مجموعه فیلدها جدول میگویند.
تعریف PrimaryKey(کلید داخلی)
به فیلدی که دادههای داخل آن تکراری نباشند کلید داخلی گویند، کلید داخلی مفهومی مشابه به (شماره ردیف) دارد و دارای دو شرط اساسی است:
- تکراری نباشد
- پوچ نباشد
در بعضی از بانکهای اطلاعاتی کلید داخلی میتواند از چند فیلد تشکیل شود. بهتر آن است که کلید داخلی از نوع عددی و شمارنده باشد. پیشنهاد میشود کلید داخلی از عدد 1 آغاز و به ترتیب به آن افزوده شود. هیچگاه سعی نکنید تا فیلدی همانند شماره تلفن را بهعنوان کلید داخلی برگزینید.
تعریف View
در بعضی موارد کاربر نمیخواهد محتویات کامل جدول را مشاهده کند در این صورت میتوان از دید استفاده کرد. در بعضی موارد نیاز است تا چند جدول با هم ترکیب شوند، این نیز یکی دیگر از قابلیتهای دید است. به طور خلاصه میتوان گفت دید، از جدول و یا جداول، مشتق میشود.

دید از جدول مشتق میشود
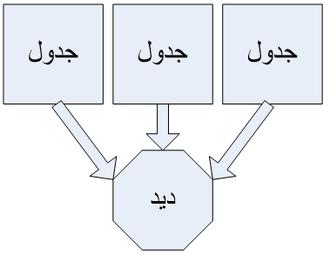
دید ممکن است از چند جدول مشتق شود
تعریف Index
شاخص موجودیتی برای افزایش سرعت پرسوجو در سطح جداول و دیدها میباشد. به طور معمول در هر جدول و یا دید، میتوان فیلد یا فیلدهایی را بهعنوان شاخص تعریف کرد.
تعریف Role
هر کاربر میتواند دارای نقش باشد، دقت داشته باشید که یک کاربر میتواند دارای چندین نقش باشد. به طور مثال یک کاربر هم مدیر پروژه باشد و هم بتواند اسناد سایر مدیران را مشاهده نماید.
تعریف Profile
هر کاربر میتواند دارای یک پروفایل باشد. پروفایل موجودیتی است که با آن میتوان کاربر را به صورت سخت افزاری و نرمافزاری محدود کرد. بهعنوان مثال یک کاربر تنها بتواند در هر ارتباط دو ساعت به بانک اطلاعاتی اوراکل متصل و همچنین قادر باشد مقدار مشخصی از فضای CPU کامپیوتر را اشغال نماید.
جدول میتواند دارای یک مالک باشد به مالک اصطلاحاً schema گفته میشود.
در اوراکل همه چیز دارای مالک است.
جدول دارای مالک است، constraint دارای مالک است، trigger دارای مالک است،view دارای مالک است،procedure دارای مالک است،object دارای مالک است، function pl/sql دارای مالک است در کل همه چیز در اوراکل دارای مالک است و هیچ چیز بیصاحب نیست.
به مالک اصطلاحاً schema گفته میشود یا همان کاربری که مالکه (مالک میتونه مالک هرچی باشه حتی اگه کاربری مالک یک چیز نیز باشد به آن schema گفته میشود.)
نماد کاربر معمولی (کاربری که هنوز مالک چیزی نیست) و نماد کاربر مالک (Schema):
تعریف Repository: مجموعه schema ها که در کنار هم قرار میگیرند Repository رو تشکیل میدهند.
تعریف RDBMS: نرمافزاری که به صورت رابطهای Repositoryهای مارو مدیریت میکند.
در داخل یک RDBMS میتوان بینهایت Repository داشت.
برای ایجاد وجه تمایز بین رکوردهامون فیلدی به نام ID به جدول بالا اضافه میکنیم.
| ID | نام | فامیل | شهر |
| 1 | مهدی | غفاری | تهران |
| 2 | احسان | جلالی | تهران |
| 3 | فرزاد | کارخانی | تهران |
ID غالباً فیلدی است که:
- AutoNumber
- حق نداره null باشه
- حق نداره تکراری باشه
- بهتره عددی باشه
- بهتره متوالی باشه
- بهتره از 0 شروع بشه
نکته: هر فیلد uniq ای رو نباید id کرد، به عنوان مثال اگه کدملی رو id درنظر بگیرید پوست دیتابیستون رو کندید. چون هر چه قدر طول عدد انتخابیتون بیشتر باشه تو بحث index گذاری پردازش بیشتری رو نسبت به پردازش عددی با طول کمتر میگیره. به طور معمول ما کدملی رو میگیریم ولی به عنوان کلید اون رو تعریف نمیکنیم و اولویت کلید رو با id میذاریم.
نکته: اگر رکوردی نیاز به حذف داشت اون رکورد رو حذف نکنید، چون فقط پردازش بیشتری از سرور شما میگیره و به هیچ عنوان اون رکورد از سطح دیتابیس حذف نمیشه.
مقدماتی از نرمالسازی
در جدول بالا میتوانیم به شکل زیر تغییراتی رو اعمال کنیم تا از افزونگی داده پرهیز کنیم:
جدول شهرها
| ID_City | نام شهر |
| 1 | تهران |
| 2 | یزد |
جدول کارمندان
| ID | نام | فامیل | ID_City |
| 1 | مهدی | غفاری | 1 |
| 2 | احسان | جلالی | 1 |
| 3 | فرزاد | کارخانی | 1 |
| 4 | مهران | صاحبدل | 2 |
نکته: تا جایی که میتونید موجودیتها رو جدا کنید و بکشید بیرون، به عنوان مثال در جدول کارمندان شهر یه موجودیت مستقله پس میشه آوردش بیرون و در جدول دیگری ذخیرهاش کرد. بعد از جدا کردن شهرها از جدول کامندان بین این ۲ جدول رابطه برقرار میکنیم.
همانطور که در بالا مشاهده میکنید یک تغییر کوچک در جدول کارمندان ایجاد شده، به جای نام شهر از فیلد جدیدی بنام ID_CITY استفاده کردهایم. اعداد داخل این فیلد با کلید داخلی جدول شهرها رابطه دارند.
- ID_CITY: در جدول شهرها حکم کلید داخلی را ایفا میکند.
- ID: در جدول اطلاعات کارمندان حکم کلید داخلی را ایفا میکند.
- ID_CITY: در جدول اطلاعات کارمندان حکم کلید خارجی را ایفا میکند.
پس کلید خارجی همانند یک سفیر در یک کشور بیگانه عمل میکند.
تعریف رابطه
نظریه رابطه حاصل تلاشهای دکتر Edgar F. Codd میباشد، کلمه رابطه را ایشان به دنیای بانکهایاطلاعاتی وارد نمود. دکتر Edgar F. Codd یکی از پرسنل شرکت IBM بود، نظریات ایشان باعث تحولات عظیمی در دنیای بانکهای اطلاعاتی شد. به جدول ذیل دقت کنید.
انواع تحلیل رابطه در ER
- Self Scope (یعنی رابطه رو از سطح جدول میبینیم، بیشتر در بحث Object Analysis مطرح میشه)
- Up Scope (یعنی از بالا تحلیل دیتابیس رو انجام میدیم)
در بانکاطلاعاتی ما با روابط UpScope (یعنی از بالا تحلیل دیتابیس رو انجام میدیم) سروکار داریم. همچنین در واقع در بانک اطلاعاتی دو نوع رابطه (منطقی) از این جنس وجود دارد.
- رابطه یک به چند (و یا همان رابطه چند به یک)
- رابطه یک به یک
نکته: رابطه چند به چند به دلیل ایجاد افزونگی داده مورد استفاده قرار نمیگیرد، و حتماً این رابطه باید نقض و شکانده شود.
تعریف رابطه یک به چند
در این نوع رابطه یک رکورد از یک جدول با چند رکورد از جدول دیگر رابطه دارد. به عنوان نمونه، مثال قبل بیانگر یک رابطه یک به چند است.
مزیتهای رابطه یک به چند
در این نوع رابطه سعی بر آن است که از وارد کردن دادههای تکراری جلوگیری شود. در ضمن فراموش نکنید که این رابطه باعث دستهبندی اطلاعات نیز میشود.
تعریف رابطه یک به یک
دراین نوع رابطه یک رکورداز یک جدول، تنها با یک رکورد از جدول دیگر رابطه دارد. فرض کنید میخواهیم اطلاعات یک جدول را در سطح دو جدول توزیع نماییم. در این مورد نیاز به دانش دستهبندی اطلاعات داریم. به طور مثال به جدول قبل دقت کنید.
مثالی برای رابطه Self Scope
فرض کنید من یکنفر به تنهایی میخوام یک جمعی رو بزنم، پس باید یه جمعی رو بزنم. (رابطه ۱ به چند)
حال فرض کنید من چند نفرم و میخوام یکنفر رو بزنم پس درکل باید ۱ نفر رو بزنم. (رابطه چند به ۱)
حال فرض کنید من بکنفرم و میخوام یکتفر رو بزنم پس در کل یکنفر رو میزنم. (رابطه ۱ به ۱)
در حالت Self Scope رابطه (چند به ۱) با رابطه (۱ به ۱) برابره
(در حقیقت هیچ فرقی نمیکنه شما یک object از ref تون میگیرید)
مزیتهای رابطه یک به یک
در این نوع رابطه مقصود دسته بندی اطلاعات است و با استفاده از این نوع رابطه سزعت جستجو به دلیل طبقهبندی دادهها افزایش مییابد.
یک نتیجه گیری ساده
اگر کلید داخلی یک جدول با کلید داخلی جدول دیگر رابطه داشته باشد، رابطه یک به یک است.
اگر کلید داخلی جدولی با کلید خارجی جدول دیگر رابطه داشته باشد رابطه یک به چند است.
از ایجاد رابطه بیش از حد بپرهیزید
در صورتی که رابطههای زیادی بین جداول ایجاد کنید پرسوجوی شما به سختی انجام خواهدشد.(اصطلاحاً به این عمل شخمزدن بانک اطلاعاتی گویند.)
از حذف فیزیکی رکوردها در جداول رابطهای بپرهیزید
در صورت حذف رکورد اصلی اگر رکوردهای وابسته به آن از سطح سایر جداول حذف نشوند، بانک اطلاعاتی شما دچار مشکل خواهد شد.(البته در بانکهای اطلاعاتی مدرن این مشکل حل شدهاست، به طوری که در صورت تمایل میتوانید به بانک اطلاعاتی اعلام کنید رکوردهای وابسته را در صورت حذف رکورد مرجع حذف کند. اما لازم است برای اطمینان بیشتر از روش ذیل استفاده کنید).
به جای حذف رکوردها از فیلد جایگزین استفاده کنید
همانطور که اشارهشد حذف رکورد در جداول رابطهای مشکل ایجاد میکند. برای جلوگیری از بروز این مشکل میتوانید به جای حذف فیزیکی رکوردها بر روی آنها نشانههای منطقی قرار داده و از روی آن نشانهها متوجه شوید که آیا آن رکورد حذف شدهاست یا خیر.
نکته: در رابطه Up Scope روابط (چند به ۱) و (۱ به چند) یکی هستند و در رابطه Self Scope روابط (۱ به ۱) با (چند به ۱) یکی است.
نکته: در خیلی از موارد (مثل سیستمهای بانکی) نرمالسازی کار درستی نیست، چون نرمالسازی درسته که حجم داده رو پایین میاره ولی به جاش پردازش رو بالا میبره.
البته بهتره بدونید که مفاهیمی مثل نرمالسازی امروزه کمکم داره زیرسوال میره و ساختارهای دیگهای بجاش در نسل سوم ساختارهای دیتابیس ورود پیدا کردن به اسم NoSQL.
کمی بیشتر درباره NoSQL
MongoDB یکی از بانکهایاطلاعاتی معروف در بحث NoSQL ه. این بانکها به طور کامل Full Object Oriented هستند و دیگه ساختار منسجمی ندارن، ما تا به امروز یه ساختار منسجمی به اسم table داشتیم که ساختارش همیشه منسجمه توی NoSQL ما دیگه یه ساختار مشخصی نداریم یه چیزی داریم به اسم Document که توش هر چیزی رو میشه با هر نوعی ذخیره کرد. (میتونه یه رکوردش لپتاپ باشه یه رکوردش انسان باشه یه رکوردش مدرسه باشه) دیگه رکوردها یه ساختار مشخصی نداره و ساختار رکوردها داینامیکه.
خب چرا این اتفاق افتاده: یه جایی مثل فیسبوک رو درنظر بگیرید به عنوان مثال یه فیلدی هست به اسم id زن یا id شوهرش ما این فیلد رو تو جدول کاربران میبینیم حالا یادمون باشه خیلیها اصلا ازدواج نکردهان پس تمام id های اونا بای null بشه پس وقتی قراره null بشن چرا اصلا براشون تغریف شدن؟!!
امکانش هست که شما ۱۰ میلیون رکورد داشته باشید که اصلاً زن نداشته باشن پس اون id برای این ۱۰ میلیون نفر اضافه هستش.
اینجاست که ما میرسیم به یه دیدگاهی که ساختار table مشکل داره و بهتره یک ساختار دیگه رو پیش بگیریم به اسم ساختار داکیومنت بیس این ساختار میگه همه چیز داینامیکه یعنی یک جدول یک ساختار رکوردی رو نگهداری نمیکنه
در واقع یک داکیومنت تو حالتهای مختلف ساختارهای مختلفی رو نگه میداره مثلا در مورد رکوردی که اصلاً زن نداره اصلا فیلد id زن تو اون رکورد توی اون داکیومنت مطرح نیست.
نکته: NoSQL عموماً برای huge data ها و اپلیکیشنهایی که با دیتای خیلی زیاد کار میکنن استفاده میشه
نکته: میشه از یک داکیومنت به عنوان یک فیلد در RDBMS استفاده کرد و در نتیجه از ترکیب این ۲ در اوراکل استفاده کرد. (ترکیب با Oracle Migration از RDBMS به ORDBMS به RDBMS)
نکته آخر
یادآوری میکنم هر tools ای برای هدفیه و اصلا توصیه نمیشه از اوراکل در اپلیکیشنهای دسکتاپ یا بازی به صورت embed استفاده شود.
 رضا
رضا